- 2.1 低负载机器上的
vmstat输出 - 2.2 高负载机器(CPU 绑定)上的
vmstat输出 - 3.1
/etc/logrotate.conf示例 - 4.1 简单 SystemTap 脚本
- 4.2 带计时器事件的探针
- 4.3 带格式说明符的
printf函数 - 4.4 使用全局变量
- 4.5 使用
tcp_connections.stp监控传入的 TCP 连接 - 12.1
cpupower frequency-info的示例输出 - 12.2
cpupower idle-info的示例输出 - 12.3 示例
cpupower monitor输出 - 20.1 使用软件时间戳的从时钟
- 20.2 使用硬件时间戳的从时钟
- 20.3 使用硬件时间戳的主时钟
- 20.4 使用软件时间戳的主时钟(通常不推荐)
版权所有 © 2006–2024 SUSE LLC 及其贡献者。保留所有权利。
在 GNU 自由文档许可协议第 1.2 版或(可选)第 1.3 版的条款下,允许复制、分发和/或修改本文档,其中本版权声明和许可协议为不变部分。许可协议第 1.2 版的副本包含在题为 “GNU 自由文档许可协议” 的章节中。
有关 SUSE 商标,请参阅 https://www.suse.com/company/legal/。所有第三方商标均为其各自所有者的财产。商标符号(®、™ 等)表示 SUSE 及其关联公司的商标。星号 (*) 表示第三方商标。
本书中的所有信息均经过仔细核实。但是,这不能保证完全准确。SUSE LLC、其关联公司、作者和译者对可能出现的错误或由此产生的后果不承担任何责任。
- 在线文档
我们的文档可在 https://doc.opensuse.net.cn 上在线获取。浏览或下载各种格式的文档。

注意:最新更新
最新的更新通常可在本文档的英文版本中获得。
- SUSE 知识库
如果您遇到问题,请查看在线提供的技术信息文档 (TID),网址为 https://www.suse.com/support/kb/。搜索 SUSE 知识库,以获取由客户需求驱动的已知解决方案。
- 在您的系统中
为了离线使用,发布说明也可用在您的系统上的
/usr/share/doc/release-notes下。各个软件包的文档可用在/usr/share/doc/packages下。许多命令也在其 手册页 中进行了描述。要查看它们,请运行
man,后跟特定的命令名称。如果您的系统上未安装man命令,请使用sudo zypper install man进行安装。
欢迎您对本文档提出反馈和贡献。以下是提供反馈的渠道:
- 错误报告
请在 https://bugzilla.opensuse.org/ 上报告文档问题。
为了简化此过程,请单击 HTML 版本本文档中标题旁边的 图标。这将预先选择 Bugzilla 中的正确产品和类别,并添加指向当前章节的链接。您可以立即开始编写错误报告。
需要一个 Bugzilla 帐户。
- 贡献
要贡献本文档,请单击 HTML 版本本文档中标题旁边的 图标。这将带您到 GitHub 上的源代码,您可以在那里打开一个拉取请求。
需要一个 GitHub 帐户。
注意: 仅适用于英文
“”图标仅适用于每份文档的英文版本。对于所有其他语言,请改用“”图标。
有关用于本文档的文档环境的更多信息,请参阅存储库的 README 文件。
- 邮件
您还可以将错误报告和有关文档的反馈发送至 <doc-team@suse.com>。请包含文档标题、产品版本和文档的发布日期。此外,请包含相关的章节编号和标题(或提供 URL),并提供问题的简洁描述。
- 帮助
如果您在 openSUSE Leap 上需要进一步的帮助,请参阅 https://en.opensuse.net.cn/Portal:Support。
本文档中使用了以下通知和排版约定:
/etc/passwd:目录名和文件名占位符:将 占位符 替换为实际值
PATH:环境变量ls、--help:命令、选项和参数user:用户名或组名软件包名:软件包的名称
Alt、Alt–F1:要按下的键或键组合。键以键盘上的大写字母显示。
、 › :菜单项、按钮
第 1 章,《“示例章节”:对本指南中另一个章节的交叉引用。
必须使用
root权限运行的命令。您也可以使用sudo命令以非特权用户的身份运行这些命令。#command>sudocommand可以由非特权用户运行的命令
>command命令可以通过行尾的反斜杠字符 (
\) 分成两行或多行。反斜杠告知 shell 命令调用将在行尾之后继续。>echoa b \ c d一个代码块,显示命令(前面带有提示符)和 shell 返回的相应输出。
>commandoutput通知

警告:警告通知
在继续之前您必须了解的重要信息。警告您有关安全问题、潜在的数据丢失、硬件损坏或物理危害。

重要:重要通知
在继续之前您应该了解的重要信息。
注意:注意通知
其他信息,例如关于软件版本差异的信息。

提示:提示通知
有用的信息,例如指南或实用建议。
紧凑型通知
其他信息,例如关于软件版本差异的信息。
有用的信息,例如指南或实用建议。
- 1 系统调优通用说明
本手册讨论如何找到性能问题的根源,并提供解决这些问题的手段。在开始调优系统之前,您应该确保已排除常见问题,并找到问题的原因。您还应该有一个详细的计划来调优系统,因为应用随机调优技巧无济于事,甚至可能使情况更糟。
过程 1.1: 调优系统的一般方法 #
指定需要解决的问题。
如果降级是新发生的,则确定系统最近的任何更改。
确定为什么该问题被视为性能问题。
指定可用于分析性能的指标。此指标可以是延迟、吞吐量、同时登录的最大用户数或最大活跃用户数。
使用上一步的指标测量当前性能。
确定应用程序花费时间最多的子系统。
监控系统和/或应用程序。
分析数据,分类时间花费在哪里。
调优上一步中确定的子系统。
使用相同的指标,在不监控的情况下重新测量当前性能。
如果性能仍然不可接受,请从步骤 3 重新开始。
在开始调优系统之前,请尝试尽可能准确地描述问题。诸如“系统很慢!”之类的语句不是一个有用的问题描述。例如,是需要普遍提高系统速度,还是仅在高峰时段提高速度,这可能会有所不同。
此外,请确保您可以对您的问题进行测量,否则您无法验证调优是否成功。您应该始终能够比较“之前”和“之后”。使用哪些指标取决于您正在研究的场景或应用程序。例如,相关的 Web 服务器指标可以用以下术语表示
- 延迟
交付页面所需的时间
- 吞吐量
每秒服务的页面数或每秒传输的兆字节数
- 活跃用户
在可接受的延迟内接收页面的同时,可以下载页面的最大用户数
性能问题通常是由网络或硬件问题、错误或配置问题引起的。在尝试调优系统之前,请务必排除以下问题
检查
systemd日志的输出(请参见《参考》手册,第 11 章“journalctl:查询systemd日志”)是否存在异常条目。检查(使用
top或ps)某个进程是否行为异常,占用了异常数量的 CPU 时间或内存。通过检查
/proc/net/dev检查网络问题。如果物理磁盘出现 I/O 问题,请确保不是由硬件问题(使用
smartmontools检查磁盘)或磁盘已满引起的。确保后台作业在服务器负载较低时执行。这些作业也应以低优先级运行(通过
nice设置)。如果机器使用相同资源运行多个服务,请考虑将服务移动到另一台服务器。
最后,确保您的软件是最新的。
查找瓶颈是调优系统中最困难的部分。openSUSE Leap 提供了许多工具来帮助您完成此任务。有关通用系统监控应用程序和日志文件分析的详细信息,请参见第二部分,“系统监控”。如果问题需要长时间的深入分析,Linux 内核提供了执行此类分析的方法。有关详细信息,请参见第三部分,“内核监控”。
收集数据后,需要对其进行分析。首先,检查服务器的硬件(内存、CPU、总线)及其 I/O 容量(磁盘、网络)是否足够。如果满足这些基本条件,系统可以通过调优获益。
对于所描述的每个命令,都提供了相关输出的示例。在示例中,第一行是命令本身(在 tux > 或 root # 之后)。省略的部分用方括号 ([...]) 表示,必要时会折行。长行的换行符用反斜杠 (\) 表示。
> command -x -y
output line 1
output line 2
output line 3 is annoyingly long, so long that \
we need to break it
output line 4
[...]
output line 98
output line 99描述已尽量简短,以便我们可以包含尽可能多的实用程序。所有命令的更多信息可以在手册页中找到。大多数命令也支持参数 --help,它会生成一个简短的可能参数列表。
虽然大多数 Linux 系统监控工具只监控系统的一个方面,但也有一些工具具有更广泛的范围。要获取概述并找出需要进一步检查的系统部分,请首先使用这些工具。
vmstat 收集有关进程、内存、I/O、中断和 CPU 的信息
vmstat [options] [delay [count]]
在不带延迟和计数参数的情况下调用时,它显示自上次重新启动以来的平均值。在带延迟值(以秒为单位)调用时,它显示给定期间的值(以下示例中为两秒)。计数的值指定 vmstat 应执行的更新次数。如果未指定,它将一直运行直到手动停止。
示例 2.1: 低负载机器上的 vmstat 输出 #
> vmstat 2
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
1 0 44264 81520 424 935736 0 0 12 25 27 34 1 0 98 0 0
0 0 44264 81552 424 935736 0 0 0 0 38 25 0 0 100 0 0
0 0 44264 81520 424 935732 0 0 0 0 23 15 0 0 100 0 0
0 0 44264 81520 424 935732 0 0 0 0 36 24 0 0 100 0 0
0 0 44264 81552 424 935732 0 0 0 0 51 38 0 0 100 0 0示例 2.2: 高负载机器(CPU 绑定)上的 vmstat 输出 #
> vmstat 2
procs -----------memory----------- ---swap-- -----io---- -system-- -----cpu------
r b swpd free buff cache si so bi bo in cs us sy id wa st
32 1 26236 459640 110240 6312648 0 0 9944 2 4552 6597 95 5 0 0 0
23 1 26236 396728 110336 6136224 0 0 9588 0 4468 6273 94 6 0 0 0
35 0 26236 554920 110508 6166508 0 0 7684 27992 4474 4700 95 5 0 0 0
28 0 26236 518184 110516 6039996 0 0 10830 4 4446 4670 94 6 0 0 0
21 5 26236 716468 110684 6074872 0 0 8734 20534 4512 4061 96 4 0 0 0提示:输出的第一行
vmstat 输出的第一行始终显示自上次重新启动以来的平均值。
列显示以下内容
显示处于可运行状态的进程数。这些进程要么正在执行,要么正在等待空闲的 CPU 插槽。如果此列中的进程数持续高于可用的 CPU 数,则可能表明 CPU 功率不足。
显示正在等待 CPU 以外资源的进程数。此列中的高数字可能表示 I/O 问题(网络或磁盘)。
当前使用的交换空间量 (KB)。
未使用的内存量 (KB)。
最近未使用的内存,可以回收。此列仅在调用
vmstat时带参数-a(推荐)时可见。最近使用的内存,通常不会被回收。此列仅在调用
vmstat时带参数-a(推荐)时可见。RAM 中的文件缓冲区缓存 (KB),包含文件系统元数据。此列在调用
vmstat时带参数-a时不可见。RAM 中的页面缓存 (KB),包含文件的实际内容。此列在调用
vmstat时带参数-a时不可见。每秒从交换空间移至 RAM (
si) 或从 RAM 移至交换空间 (so) 的数据量 (KB)。长时间的so值高可能表示应用程序内存泄漏,泄漏的内存正在被换出。长时间的si值高可能表示长时间不活动的应用程序现在又活跃了。长时间同时出现高si和so值是交换颠簸的证据,可能表示系统需要安装更多 RAM,因为没有足够的内存来容纳工作集大小。每秒从块设备接收的块数(例如,磁盘读取)。交换也会影响此处显示的值。块大小可能因文件系统而异,但可以使用 stat 实用程序确定。如果需要吞吐量数据,可以使用 iostat。
每秒发送到块设备的块数(例如,磁盘写入)。交换也会影响此处显示的值。
每秒中断数。高值可能表示高 I/O 级别(网络和/或磁盘),但也可能由其他原因触发,例如由其他活动触发的处理器间中断。务必检查
/proc/interrupts以确定中断源。每秒上下文切换数。这是内核将内存中一个程序的执行代码替换为另一个程序的执行代码的次数。
执行应用程序代码的 CPU 使用率百分比。
执行内核代码的 CPU 使用率百分比。
CPU 空闲时间百分比。如果此值在较长时间内为零,则您的 CPU 正在满负荷工作。这不一定是坏事——请参阅 和 列中的值以确定您的机器是否配备了足够的 CPU 功率。
如果“wa”时间非零,则表示由于等待 I/O 而丢失的吞吐量。这可能是不可避免的,例如,如果文件首次读取,后台回写无法跟上等等。它也可能是硬件瓶颈(网络或硬盘)的指标。最后,它可能表示虚拟内存管理器存在调优潜力(请参阅第 15 章,调优内存管理子系统)。
从虚拟机窃取的 CPU 时间百分比。
有关更多选项,请参见 vmstat --help。
dstat 是 vmstat、iostat、netstat 或 ifstat 等工具的替代品。dstat 实时显示系统资源的信息。例如,您可以将磁盘使用情况与 IDE 控制器的中断相结合进行比较,或者将网络带宽与磁盘吞吐量(在同一时间间隔内)进行比较。
默认情况下,其输出以可读表格的形式呈现。或者,可以生成 CSV 输出,适用于作为电子表格导入格式。
它用 Python 编写,可以通过插件进行增强。
这是通用语法
dstat [-afv] [OPTIONS..] [DELAY [COUNT]]
所有选项和参数都是可选的。不带任何参数时,dstat 显示有关 CPU (-c, --cpu)、磁盘 (-d, --disk)、网络 (-n, --net)、分页 (-g, --page) 以及系统中断和上下文切换 (-y, --sys) 的统计信息;它每秒刷新输出,无限期地
#dstatYou did not select any stats, using -cdngy by default. ----total-cpu-usage---- -dsk/total- -net/total- ---paging-- ---system-- usr sys idl wai hiq siq| read writ| recv send| in out | int csw 0 0 100 0 0 0| 15k 44k| 0 0 | 0 82B| 148 194 0 0 100 0 0 0| 0 0 |5430B 170B| 0 0 | 163 187 0 0 100 0 0 0| 0 0 |6363B 842B| 0 0 | 196 185
-a,--all等同于
-cdngy(默认)-f,--full扩展
-C、-D、-I、-N和-S发现列表-v,--vmstat等同于
-pmgdsc,-D total
- DELAY
每次更新之间的延迟(秒)
- COUNT
退出前要显示的更新次数
默认延迟为 1,计数未指定(无限制)。
有关更多信息,请参阅 dstat 的手册页及其网页:http://dag.wieers.com/home-made/dstat/。
sar 可以生成关于几乎所有重要系统活动的详细报告,其中包括 CPU、内存、IRQ 使用情况、I/O 和网络。它还可以实时生成报告。sar 命令从 /proc 文件系统收集数据。
注意:sysstat 包
sar 命令是 sysstat 软件包的一部分。使用 YaST 或 zypper in sysstat 命令安装它。sysstat.service 默认不启动,必须使用以下命令启用并启动
>sudosystemctl enable --now sysstat
要实时生成报告,请调用带间隔(秒)和计数的 sar。要从文件生成报告,请使用选项 -f 指定文件名,而不是间隔和计数。如果未指定文件名、间隔和计数,sar 会尝试从 /var/log/sa/saDD 生成报告,其中 DD 代表当前日期。这是 sadc(系统活动数据收集器)写入其数据的默认位置。使用多个 -f 选项查询多个文件。
sar 2 10 # real time report, 10 times every 2 seconds sar -f ~/reports/sar_2014_07_17 # queries file sar_2014_07_17 sar # queries file from today in /var/log/sa/ cd /var/log/sa && \ sar -f sa01 -f sa02 # queries files /var/log/sa/0[12]
在下方找到有用的 sar 调用及其解释的示例。有关每列含义的详细信息,请参阅 sar 的 man (1)。
注意:服务停止时的 sysstat 报告
当 sysstat 服务停止时(例如,在重启或关机期间),该工具仍会通过自动运行 /usr/lib64/sa/sa1 -S ALL 1 1 命令来收集最后时刻的统计信息。收集到的二进制数据存储在系统活动数据文件中。
在不带选项调用时,sar 显示关于 CPU 使用率的基本报告。在多处理器机器上,所有 CPU 的结果都会汇总。使用选项 -P ALL 还可以查看单个 CPU 的统计信息。
# sar 10 5
Linux 6.4.0-150600.9-default (jupiter) 03/11/2024 _x86_64_ (2 CPU)
17:51:29 CPU %user %nice %system %iowait %steal %idle
17:51:39 all 57,93 0,00 9,58 1,01 0,00 31,47
17:51:49 all 32,71 0,00 3,79 0,05 0,00 63,45
17:51:59 all 47,23 0,00 3,66 0,00 0,00 49,11
17:52:09 all 53,33 0,00 4,88 0,05 0,00 41,74
17:52:19 all 56,98 0,00 5,65 0,10 0,00 37,27
Average: all 49,62 0,00 5,51 0,24 0,00 44,62显示 CPU 在等待 I/O 请求时空闲的时间百分比。如果此值在很长一段时间内远高于零,则 I/O 系统(网络或硬盘)存在瓶颈。如果 值在很长一段时间内为零,则您的 CPU 正在满负荷工作。
使用选项 -r 生成系统内存 (RAM) 的总体情况
# sar -r 10 5
Linux 6.4.0-150600.9-default (jupiter) 03/11/2024 _x86_64_ (2 CPU)
17:55:27 kbmemfree kbmemused %memused kbbuffers kbcached kbcommit %commit kbactive kbinact kbdirty
17:55:37 104232 1834624 94.62 20 627340 2677656 66.24 802052 828024 1744
17:55:47 98584 1840272 94.92 20 624536 2693936 66.65 808872 826932 2012
17:55:57 87088 1851768 95.51 20 605288 2706392 66.95 827260 821304 1588
17:56:07 86268 1852588 95.55 20 599240 2739224 67.77 829764 820888 3036
17:56:17 104260 1834596 94.62 20 599864 2730688 67.56 811284 821584 3164
Average: 96086 1842770 95.04 20 611254 2709579 67.03 815846 823746 2309和 列显示当前工作负载可能需要的最大内存量(RAM 和交换空间)的近似值。 以千字节为单位显示绝对数字,而 显示百分比。
使用选项 -B 显示内核分页统计信息。
# sar -B 10 5
Linux 6.4.0-150600.9-default (jupiter) 03/11/2024 _x86_64_ (2 CPU)
18:23:01 pgpgin/s pgpgout/s fault/s majflt/s pgfree/s pgscank/s pgscand/s pgsteal/s %vmeff
18:23:11 366.80 11.60 542.50 1.10 4354.80 0.00 0.00 0.00 0.00
18:23:21 0.00 333.30 1522.40 0.00 18132.40 0.00 0.00 0.00 0.00
18:23:31 47.20 127.40 1048.30 0.10 11887.30 0.00 0.00 0.00 0.00
18:23:41 46.40 2.50 336.10 0.10 7945.00 0.00 0.00 0.00 0.00
18:23:51 0.00 583.70 2037.20 0.00 17731.90 0.00 0.00 0.00 0.00
Average: 92.08 211.70 1097.30 0.26 12010.28 0.00 0.00 0.00 0.00(每秒主错误)列显示从磁盘加载到内存的页面数。错误的来源可能是文件访问或错误。有时,许多主错误是正常的。例如,在应用程序启动期间。如果应用程序的整个生命周期都出现主错误,则可能表示主内存不足,特别是如果与大量直接扫描(pgscand/s)结合使用。
列显示扫描的页面数 () 与从主内存缓存或交换缓存重新使用的页面数 () 的关系。它是页面回收效率的度量。健康值要么接近 100(每个换出的非活动页面都被重新使用),要么为 0(没有页面被扫描)。该值不应低于 30。
使用选项 -d 显示块设备(硬盘、光驱、USB 存储设备等)。务必使用附加选项 -p (pretty-print) 以使 列可读。
# sar -d -p 10 5
Linux 6.4.0-150600.9-default (jupiter) 03/11/2024 _x86_64_ (2 CPU)
18:46:09 DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util
18:46:19 sda 1.70 33.60 0.00 19.76 0.00 0.47 0.47 0.08
18:46:19 sr0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
18:46:19 DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util
18:46:29 sda 8.60 114.40 518.10 73.55 0.06 7.12 0.93 0.80
18:46:29 sr0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
18:46:29 DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util
18:46:39 sda 40.50 3800.80 454.90 105.08 0.36 8.86 0.69 2.80
18:46:39 sr0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
18:46:39 DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util
18:46:49 sda 1.40 0.00 204.90 146.36 0.00 0.29 0.29 0.04
18:46:49 sr0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
18:46:49 DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util
18:46:59 sda 3.30 0.00 503.80 152.67 0.03 8.12 1.70 0.56
18:46:59 sr0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
Average: DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util
Average: sda 11.10 789.76 336.34 101.45 0.09 8.07 0.77 0.86
Average: sr0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00比较所有磁盘的 、 和 的值。 和 列中持续高企的值可能表明 I/O 子系统是瓶颈。
如果机器使用多个磁盘,那么最好在速度和容量相同的磁盘之间均匀交错 I/O。需要考虑存储是否具有多层。此外,如果存储有多个路径,那么在平衡存储使用方式时,要考虑链路饱和的程度。
sar 报告对于人类来说并不总是容易解析的。kSar 是一个 Java 应用程序,它可视化您的 sar 数据,创建易于阅读的图表。它甚至可以生成 PDF 报告。kSar 接收实时生成的数据以及文件中的历史数据。kSar 在 BSD 许可证下获得许可,可从 https://sourceforge.net/projects/ksar/ 获取。
要监控系统设备负载,请使用 iostat。它会生成报告,有助于更好地平衡连接到系统的物理磁盘之间的负载。
要使用 iostat,请安装 sysstat 软件包。
第一个 iostat 报告显示自系统启动以来收集的统计信息。随后的报告涵盖自上次报告以来的时间。
> iostat
Linux 6.4.0-150600.9-default (jupiter) 03/11/2024 _x86_64_ (4 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
17.68 4.49 4.24 0.29 0.00 73.31
Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
sdb 2.02 36.74 45.73 3544894 4412392
sda 1.05 5.12 13.47 493753 1300276
sdc 0.02 0.14 0.00 13641 37以这种方式调用 iostat 有助于您找出吞吐量是否与您的预期不同,但不能说明原因。通过调用 iostat -x 生成扩展报告可以更好地回答此类问题。扩展报告还包括例如平均队列大小和平均等待时间的信息。如果使用 -z 开关排除空闲块设备,评估数据也可能更容易。在 iostat 的手册页(man 1 iostat)中查找每个显示列标题的定义。
您还可以指定在指定间隔监控某个设备。例如,要为设备 sda 在三秒间隔内生成五个报告,请使用
>iostat-p sda 3 5
要显示网络文件系统 (NFS) 的统计信息,有两个类似的实用程序
nfsiostat-sysstat包含在 sysstat 软件包中。nfsiostat包含在 nfs-client 软件包中。
注意:在多路径设置中使用 iostat
iostat 命令可能不会显示 nvme list-subsys 列出的所有控制器。默认情况下,iostat 会过滤掉所有没有 I/O 的块设备。要使 iostat 显示所有设备,请使用以下命令
> iostat -p ALL实用程序 mpstat 检查每个可用处理器的活动。如果您的系统只有一个处理器,则报告全局平均统计信息。
计时参数的工作方式与 iostat 命令相同。输入 mpstat 2 5 将在两秒间隔内为所有处理器打印五个报告。
# mpstat 2 5
Linux 6.4.0-150600.9-default (jupiter) 03/11/2024 _x86_64_ (2 CPU)
13:51:10 CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
13:51:12 all 8,27 0,00 0,50 0,00 0,00 0,00 0,00 0,00 0,00 91,23
13:51:14 all 46,62 0,00 3,01 0,00 0,00 0,25 0,00 0,00 0,00 50,13
13:51:16 all 54,71 0,00 3,82 0,00 0,00 0,51 0,00 0,00 0,00 40,97
13:51:18 all 78,77 0,00 5,12 0,00 0,00 0,77 0,00 0,00 0,00 15,35
13:51:20 all 51,65 0,00 4,30 0,00 0,00 0,51 0,00 0,00 0,00 43,54
Average: all 47,85 0,00 3,34 0,00 0,00 0,40 0,00 0,00 0,00 48,41从 mpstat 数据中,您可以看到
和 之间的比率。例如,10:1 的比率表明工作负载主要运行应用程序代码,分析应侧重于应用程序。1:10 的比率表明工作负载主要受内核限制,值得考虑调优内核。或者,确定应用程序受内核限制的原因,并查看是否可以缓解。
即使系统总体负载较轻,是否存在一部分 CPU 几乎完全利用。少数热 CPU 可能表明工作负载未并行化,并且可以通过在具有较少数量更快处理器的机器上执行而受益。
turbostat 显示 AMD64/Intel 64 处理器的频率、负载、温度和功耗。它可以在两种模式下运行:如果带命令调用,则分叉命令进程,并在命令完成后显示统计信息。如果无命令运行,则每五秒显示更新的统计信息。turbostat 需要加载内核模块 msr。
>sudoturbostat find /etc -type d -exec true {} \; 0.546880 sec CPU Avg_MHz Busy% Bzy_MHz TSC_MHz - 416 28.43 1465 3215 0 631 37.29 1691 3215 1 416 27.14 1534 3215 2 270 24.30 1113 3215 3 406 26.57 1530 3214 4 505 32.46 1556 3214 5 270 22.79 1184 3214
输出取决于 CPU 类型,并且可能会有所不同。要显示更多详细信息,例如温度和功耗,请使用 --debug 选项。有关更多命令行选项和字段说明,请参阅 man 8 turbostat。
如果您需要查看特定任务对系统造成的负载,请使用 pidstat 命令。它打印每个选定任务或如果未指定任务则打印 Linux 内核管理的所有任务的活动。您还可以设置要显示的报告数量以及它们之间的时间间隔。
例如,pidstat -C firefox 2 3 打印命令名称包含字符串“firefox”的任务的负载统计信息。每两秒打印三个报告。
# pidstat -C firefox 2 3
Linux 6.4.0-150600.9-default (jupiter) 03/11/2024 _x86_64_ (2 CPU)
14:09:11 UID PID %usr %system %guest %CPU CPU Command
14:09:13 1000 387 22,77 0,99 0,00 23,76 1 firefox
14:09:13 UID PID %usr %system %guest %CPU CPU Command
14:09:15 1000 387 46,50 3,00 0,00 49,50 1 firefox
14:09:15 UID PID %usr %system %guest %CPU CPU Command
14:09:17 1000 387 60,50 7,00 0,00 67,50 1 firefox
Average: UID PID %usr %system %guest %CPU CPU Command
Average: 1000 387 43,19 3,65 0,00 46,84 - firefox同样,pidstat -d 可用于估计 I/O 任务正在进行多少 I/O,它们是否正在该 I/O 上休眠,以及任务停滞了多少时钟周期。
Linux 内核将某些消息保存在环形缓冲区中。要查看这些消息,请输入命令 dmesg -T。
较旧的事件记录在 systemd 日志中。有关日志的更多信息,请参见《参考》手册,第 11 章“journalctl:查询 systemd 日志”。
要查看进程 ID 为 PID 的进程的所有打开文件列表,请使用 -p。例如,要查看当前 shell 使用的所有文件,请输入
# lsof -p $$
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
bash 8842 root cwd DIR 0,32 222 6772 /root
bash 8842 root rtd DIR 0,32 166 256 /
bash 8842 root txt REG 0,32 656584 31066 /bin/bash
bash 8842 root mem REG 0,32 1978832 22993 /lib64/libc-2.19.so
[...]
bash 8842 root 2u CHR 136,2 0t0 5 /dev/pts/2
bash 8842 root 255u CHR 136,2 0t0 5 /dev/pts/2已使用特殊的 shell 变量 $$,其值为 shell 的进程 ID。
与 -i 结合使用时,lsof 还会列出当前打开的 Internet 文件
# lsof -i
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
wickedd-d 917 root 8u IPv4 16627 0t0 UDP *:bootpc
wickedd-d 918 root 8u IPv6 20752 0t0 UDP [fe80::5054:ff:fe72:5ead]:dhcpv6-client
sshd 3152 root 3u IPv4 18618 0t0 TCP *:ssh (LISTEN)
sshd 3152 root 4u IPv6 18620 0t0 TCP *:ssh (LISTEN)
master 4746 root 13u IPv4 20588 0t0 TCP localhost:smtp (LISTEN)
master 4746 root 14u IPv6 20589 0t0 TCP localhost:smtp (LISTEN)
sshd 8837 root 5u IPv4 293709 0t0 TCP jupiter.suse.de:ssh->venus.suse.de:33619 (ESTABLISHED)
sshd 8837 root 9u IPv6 294830 0t0 TCP localhost:x11 (LISTEN)
sshd 8837 root 10u IPv4 294831 0t0 TCP localhost:x11 (LISTEN)
udevadm monitor 侦听内核 uevents 和 udev 规则发送的事件,并将事件的设备路径 (DEVPATH) 打印到控制台。这是连接 USB 记忆棒时的一系列事件
注意:监控 udev 事件
只有 root 用户被允许通过运行 udevadm 命令来监控 udev 事件。
UEVENT[1138806687] add@/devices/pci0000:00/0000:00:1d.7/usb4/4-2/4-2.2 UEVENT[1138806687] add@/devices/pci0000:00/0000:00:1d.7/usb4/4-2/4-2.2/4-2.2 UEVENT[1138806687] add@/class/scsi_host/host4 UEVENT[1138806687] add@/class/usb_device/usbdev4.10 UDEV [1138806687] add@/devices/pci0000:00/0000:00:1d.7/usb4/4-2/4-2.2 UDEV [1138806687] add@/devices/pci0000:00/0000:00:1d.7/usb4/4-2/4-2.2/4-2.2 UDEV [1138806687] add@/class/scsi_host/host4 UDEV [1138806687] add@/class/usb_device/usbdev4.10 UEVENT[1138806692] add@/devices/pci0000:00/0000:00:1d.7/usb4/4-2/4-2.2/4-2.2 UEVENT[1138806692] add@/block/sdb UEVENT[1138806692] add@/class/scsi_generic/sg1 UEVENT[1138806692] add@/class/scsi_device/4:0:0:0 UDEV [1138806693] add@/devices/pci0000:00/0000:00:1d.7/usb4/4-2/4-2.2/4-2.2 UDEV [1138806693] add@/class/scsi_generic/sg1 UDEV [1138806693] add@/class/scsi_device/4:0:0:0 UDEV [1138806693] add@/block/sdb UEVENT[1138806694] add@/block/sdb/sdb1 UDEV [1138806694] add@/block/sdb/sdb1 UEVENT[1138806694] mount@/block/sdb/sdb1 UEVENT[1138806697] umount@/block/sdb/sdb1
命令 ipcs 生成当前正在使用的 IPC 资源列表
# ipcs
------ Message Queues --------
key msqid owner perms used-bytes messages
------ Shared Memory Segments --------
key shmid owner perms bytes nattch status
0x00000000 65536 tux 600 524288 2 dest
0x00000000 98305 tux 600 4194304 2 dest
0x00000000 884738 root 600 524288 2 dest
0x00000000 786435 tux 600 4194304 2 dest
0x00000000 12058628 tux 600 524288 2 dest
0x00000000 917509 root 600 524288 2 dest
0x00000000 12353542 tux 600 196608 2 dest
0x00000000 12451847 tux 600 524288 2 dest
0x00000000 11567114 root 600 262144 1 dest
0x00000000 10911763 tux 600 2097152 2 dest
0x00000000 11665429 root 600 2336768 2 dest
0x00000000 11698198 root 600 196608 2 dest
0x00000000 11730967 root 600 524288 2 dest
------ Semaphore Arrays --------
key semid owner perms nsems
0xa12e0919 32768 tux 666 2命令 ps 生成进程列表。大多数参数必须不带减号写入。有关简要帮助,请参阅 ps --help,或有关详细帮助,请参阅手册页。
要列出所有带有用户和命令行信息的进程,请使用 ps axu
> ps axu
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.3 34376 4608 ? Ss Jul24 0:02 /usr/lib/systemd/systemd
root 2 0.0 0.0 0 0 ? S Jul24 0:00 [kthreadd]
root 3 0.0 0.0 0 0 ? S Jul24 0:00 [ksoftirqd/0]
root 5 0.0 0.0 0 0 ? S< Jul24 0:00 [kworker/0:0H]
root 6 0.0 0.0 0 0 ? S Jul24 0:00 [kworker/u2:0]
root 7 0.0 0.0 0 0 ? S Jul24 0:00 [migration/0]
[...]
tux 12583 0.0 0.1 185980 2720 ? Sl 10:12 0:00 /usr/lib/gvfs/gvfs-mtp-volume-monitor
tux 12587 0.0 0.1 198132 3044 ? Sl 10:12 0:00 /usr/lib/gvfs/gvfs-gphoto2-volume-monitor
tux 12591 0.0 0.1 181940 2700 ? Sl 10:12 0:00 /usr/lib/gvfs/gvfs-goa-volume-monitor
tux 12594 8.1 10.6 1418216 163564 ? Sl 10:12 0:03 /usr/bin/gnome-shell
tux 12600 0.0 0.3 393448 5972 ? Sl 10:12 0:00 /usr/lib/gnome-settings-daemon-3.0/gsd-printer
tux 12625 0.0 0.6 227776 10112 ? Sl 10:12 0:00 /usr/lib/gnome-control-center-search-provider
tux 12626 0.5 1.5 890972 23540 ? Sl 10:12 0:00 /usr/bin/nautilus --no-default-window
[...]要检查有多少 sshd 进程正在运行,请将选项 -p 与命令 pidof 一起使用,该命令列出给定进程的进程 ID。
> ps -p $(pidof sshd)
PID TTY STAT TIME COMMAND
1545 ? Ss 0:00 /usr/sbin/sshd -D
4608 ? Ss 0:00 sshd: root@pts/0进程列表可以根据您的需要进行格式化。选项 L 返回所有关键字的列表。输入以下命令以发出按内存使用情况排序的所有进程列表
> ps ax --format pid,rss,cmd --sort rss
PID RSS CMD
PID RSS CMD
2 0 [kthreadd]
3 0 [ksoftirqd/0]
4 0 [kworker/0:0]
5 0 [kworker/0:0H]
6 0 [kworker/u2:0]
7 0 [migration/0]
8 0 [rcu_bh]
[...]
12518 22996 /usr/lib/gnome-settings-daemon-3.0/gnome-settings-daemon
12626 23540 /usr/bin/nautilus --no-default-window
12305 32188 /usr/bin/Xorg :0 -background none -verbose
12594 164900 /usr/bin/gnome-shell有用的 ps 调用 #
ps aux--sort COLUMN按 COLUMN 排序输出。将 COLUMN 替换为
pmem表示物理内存比率pcpu表示 CPU 比率rss表示常驻集大小(未交换的物理内存)ps axo pid,%cpu,rss,vsz,args,wchan显示每个进程、其 PID、CPU 使用率、内存大小(常驻和虚拟)、名称及其系统调用。
ps axfo pid,args显示进程树。
命令 pstree 生成树形进程列表
> pstree
systemd---accounts-daemon---{gdbus}
| |-{gmain}
|-at-spi-bus-laun---dbus-daemon
| |-{dconf worker}
| |-{gdbus}
| |-{gmain}
|-at-spi2-registr---{gdbus}
|-cron
|-2*[dbus-daemon]
|-dbus-launch
|-dconf-service---{gdbus}
| |-{gmain}
|-gconfd-2
|-gdm---gdm-simple-slav---Xorg
| | |-gdm-session-wor---gnome-session---gnome-setti+
| | | | |-gnome-shell+++
| | | | |-{dconf work+
| | | | |-{gdbus}
| | | | |-{gmain}
| | | |-{gdbus}
| | | |-{gmain}
| | |-{gdbus}
| | |-{gmain}
| |-{gdbus}
| |-{gmain}
[...]参数 -p 将进程 ID 添加到给定名称。要同时显示命令行,请使用参数 -a
命令 top(“进程表”的缩写)显示进程列表,每两秒刷新一次。要停止程序,请按 Q。参数 -n 1 在显示一次进程列表后停止程序。以下是命令 top -n 1 的示例输出
> top -n 1
Tasks: 128 total, 1 running, 127 sleeping, 0 stopped, 0 zombie
%Cpu(s): 2.4 us, 1.2 sy, 0.0 ni, 96.3 id, 0.1 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem: 1535508 total, 699948 used, 835560 free, 880 buffers
KiB Swap: 1541116 total, 0 used, 1541116 free. 377000 cached Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
1 root 20 0 116292 4660 2028 S 0.000 0.303 0:04.45 systemd
2 root 20 0 0 0 0 S 0.000 0.000 0:00.00 kthreadd
3 root 20 0 0 0 0 S 0.000 0.000 0:00.07 ksoftirqd+
5 root 0 -20 0 0 0 S 0.000 0.000 0:00.00 kworker/0+
6 root 20 0 0 0 0 S 0.000 0.000 0:00.00 kworker/u+
7 root rt 0 0 0 0 S 0.000 0.000 0:00.00 migration+
8 root 20 0 0 0 0 S 0.000 0.000 0:00.00 rcu_bh
9 root 20 0 0 0 0 S 0.000 0.000 0:00.24 rcu_sched
10 root rt 0 0 0 0 S 0.000 0.000 0:00.01 watchdog/0
11 root 0 -20 0 0 0 S 0.000 0.000 0:00.00 khelper
12 root 20 0 0 0 0 S 0.000 0.000 0:00.00 kdevtmpfs
13 root 0 -20 0 0 0 S 0.000 0.000 0:00.00 netns
14 root 0 -20 0 0 0 S 0.000 0.000 0:00.00 writeback
15 root 0 -20 0 0 0 S 0.000 0.000 0:00.00 kintegrit+
16 root 0 -20 0 0 0 S 0.000 0.000 0:00.00 bioset
17 root 0 -20 0 0 0 S 0.000 0.000 0:00.00 crypto
18 root 0 -20 0 0 0 S 0.000 0.000 0:00.00 kblockd默认情况下,输出按 CPU 使用率( 列,快捷键 Shift–P)排序。使用以下组合键更改排序字段
| Shift–M:常驻内存 () |
| Shift–N:进程 ID () |
| Shift–T:时间 () |
要使用任何其他字段进行排序,请按 F 并从列表中选择一个字段。要切换排序顺序,请使用 Shift–R。
参数 -U UID 仅监控与特定用户关联的进程。将 UID 替换为用户的用户 ID。使用 top -U $(id -u) 显示当前用户的进程
iotop 实用程序显示进程或线程的 I/O 使用情况表。
注意:安装 iotop
iotop 默认未安装。您需要以 root 身份使用 zypper in iotop 手动安装。
iotop 显示采样期间每个进程读取和写入的 I/O 带宽列。它还显示进程在交换和等待 I/O 期间花费的时间百分比。对于每个进程,都会显示其 I/O 优先级(类/级别)。此外,采样期间读取和写入的总 I/O 带宽显示在界面的顶部。
← 和 → 键更改排序。
R 反转排序顺序。
O 在显示所有进程和线程(默认视图)和仅显示正在执行 I/O 的进程之间切换。(此功能类似于在命令行上添加
--only。)P 在显示线程(默认视图)和进程之间切换。(此功能类似于
--only。)A 在显示当前 I/O 带宽(默认视图)和
iotop启动以来累积的 I/O 操作之间切换。(此功能类似于--accumulated。)I 允许您更改线程或进程线程的优先级。
Q 退出
iotop。按任何其他键强制刷新。
以下是 iotop --only 命令的示例输出,同时 find 和 emacs 正在运行
# iotop --only
Total DISK READ: 50.61 K/s | Total DISK WRITE: 11.68 K/s
TID PRIO USER DISK READ DISK WRITE SWAPIN IO> COMMAND
3416 be/4 tux 50.61 K/s 0.00 B/s 0.00 % 4.05 % find /
275 be/3 root 0.00 B/s 3.89 K/s 0.00 % 2.34 % [jbd2/sda2-8]
5055 be/4 tux 0.00 B/s 3.89 K/s 0.00 % 0.04 % emacs
iotop 也可以在批处理模式 (-b) 下使用,其输出可以存储在文件中以供以后分析。有关完整的选项集,请参阅手册页 (man 8 iotop)。
内核通过进程的 nice 级别(也称为 niceness)来确定哪些进程需要比其他进程更多的 CPU 时间。进程的“nice”级别越高,它从其他进程占用的 CPU 时间就越少。Nice 级别范围从 -20(最“不nice”的级别)到 19。负值只能由 root 设置。
当运行一个不重要的、持续时间长且使用大量 CPU 时间的进程时,调整 niceness 级别很有用。例如,在同时执行其他任务的系统上编译内核。使此类进程“更nice”可确保其他任务(例如 Web 服务器)具有更高的优先级。
不带任何参数调用 nice 会打印当前 niceness
> nice
0运行 nice COMMAND 会将给定命令的当前 nice 级别增加 10。使用 nice -n LEVEL COMMAND 允许您指定相对于当前级别的新 nice 级别。
要更改正在运行的进程的 niceness,请使用 renice PRIORITY -p PROCESS_ID,例如
> renice +5 3266要恢复特定用户拥有的所有进程的 niceness,请使用选项 -u USER。进程组通过选项 -g PROCESS_GROUP_ID 进行 renice。
实用程序 free 检查 RAM 和交换空间使用情况。显示了空闲和已用内存以及交换区域的详细信息
> free
total used free shared buffers cached
Mem: 32900500 32703448 197052 0 255668 5787364
-/+ buffers/cache: 26660416 6240084
Swap: 2046972 304680 1742292选项 -b、-k、-m、-g 分别以字节、KB、MB 或 GB 显示输出。参数 -s delay 确保显示每 DELAY 秒刷新一次。例如,free -s 1.5 每 1.5 秒更新一次。
使用 /proc/meminfo 获取比 free 更详细的内存使用信息。实际上,free 使用此文件中的某些数据。以下是 64 位系统的示例输出,它在 32 位系统上因内存管理不同而略有不同
MemTotal: 1942636 kB MemFree: 1294352 kB MemAvailable: 1458744 kB Buffers: 876 kB Cached: 278476 kB SwapCached: 0 kB Active: 368328 kB Inactive: 199368 kB Active(anon): 288968 kB Inactive(anon): 10568 kB Active(file): 79360 kB Inactive(file): 188800 kB Unevictable: 80 kB Mlocked: 80 kB SwapTotal: 2103292 kB SwapFree: 2103292 kB Dirty: 44 kB Writeback: 0 kB AnonPages: 288592 kB Mapped: 70444 kB Shmem: 11192 kB Slab: 40916 kB SReclaimable: 17712 kB SUnreclaim: 23204 kB KernelStack: 2000 kB PageTables: 10996 kB NFS_Unstable: 0 kB Bounce: 0 kB WritebackTmp: 0 kB CommitLimit: 3074608 kB Committed_AS: 1407208 kB VmallocTotal: 34359738367 kB VmallocUsed: 145996 kB VmallocChunk: 34359588844 kB HardwareCorrupted: 0 kB AnonHugePages: 86016 kB HugePages_Total: 0 HugePages_Free: 0 HugePages_Rsvd: 0 HugePages_Surp: 0 Hugepagesize: 2048 kB DirectMap4k: 79744 kB DirectMap2M: 2017280 kB
这些条目代表以下内容
RAM 总量。
未使用的 RAM 量。
不进行交换即可启动新应用程序的可用内存估计值。
RAM 中的文件缓冲区缓存,包含文件系统元数据。
RAM 中的页面缓存。这不包括缓冲区缓存和交换缓存,但包括 内存。
已换出内存的页面缓存。
- , ,
最近使用的内存,除非必要或显式请求,否则不会回收。 是 和 的总和
跟踪交换支持的内存。这包括私有和共享匿名映射以及写时复制后的私有文件页面。
跟踪其他文件系统支持的内存。
- , ,
较少使用的内存,通常会首先回收。 是 和 的总和
跟踪交换支持的内存。这包括私有和共享匿名映射以及写时复制后的私有文件页面。
跟踪其他文件系统支持的内存。
无法回收的内存量(例如,因为它已 或用作 RAM 磁盘)。
由
mlock系统调用支持的内存量。mlock允许进程定义其虚拟内存应映射到物理 RAM 的哪个部分。但是,mlock不保证此放置。交换空间量。
未使用的交换空间量。
等待写入磁盘的内存量,因为它包含与后端存储相比的更改。脏数据可以通过应用程序或内核在短时间延迟后显式同步。大量的脏数据可能需要相当长的时间才能写入磁盘,从而导致停滞。任何时候可以存在的脏数据总量可以通过
sysctl参数vm.dirty_ratio或vm.dirty_bytes进行控制(有关更多详细信息,请参阅第 15.1.5 节,“回写”)。当前正在写入磁盘的内存量。
使用
mmap系统调用声明的内存。进程组之间共享的内存,例如 IPC 数据、
tmpfs数据和共享匿名内存。用于内核内部数据结构的内存分配。
可以回收的 Slab 部分,例如缓存(inode、dentry 等)。
无法回收的 Slab 部分。
应用程序通过系统调用使用的内核空间内存量。
所有进程的页表专用内存量。
已发送到服务器但尚未提交的 NFS 页面。
用于块设备的跳板缓冲区内存。
FUSE 用于临时回写缓冲区的内存。
根据过量提交比率设置,系统可用的内存量。仅在启用严格过量提交记账时才强制执行。
在最坏情况下,当前工作负载所需的内存总量(RAM 和交换空间)的近似值。
分配的内核虚拟地址空间量。
已使用的内核虚拟地址空间量。
可用内核虚拟地址空间中最大的连续块。
故障内存量(只能在使用 ECC RAM 时检测到)。
映射到用户空间页表的匿名大页。这些是为进程透明分配的,无需专门请求,因此也称为透明大页 (THP)。
为
SHM_HUGETLB和MAP_HUGETLB或通过hugetlbfs文件系统预分配的大页数量,如/proc/sys/vm/nr_hugepages中定义。可用大页的数量。
已提交大页的数量。
超出 的可用大页数量(“过剩”),如
/proc/sys/vm/nr_overcommit_hugepages中定义。大页的大小——在 AMD64/Intel 64 上,默认值为 2048 KB。
- 等
映射到给定大小页面(在本例中:4 kB)的内核内存量。
使用 top 或 ps 等标准工具无法精确确定某个进程正在消耗多少内存。如果需要精确数据,请使用内核 2.6.14 中引入的 smaps 子系统。它位于 /proc/PID/smaps,它会显示 ID 为 PID 的进程当时正在使用的干净和脏内存页数。它区分共享内存和私有内存,因此您可以查看进程正在使用的内存量,而不包括与其他进程共享的内存。有关更多信息,请参阅 /usr/src/linux/Documentation/filesystems/proc.txt(需要安装 kernel-source 软件包)。
smaps 读取起来开销很大。因此,不建议定期监控它,而只在密切监控某个进程时使用。
numaTOP 是 NUMA(非统一内存访问)系统的一个工具。该工具通过提供 NUMA 系统的实时分析来帮助识别 NUMA 相关的性能瓶颈。
一般来说,numaTOP 允许您通过分析远程内存访问 (RMA) 的数量、本地内存访问 (LMA) 的数量以及 RMA/LMA 比率来识别和调查局部性差(即本地与远程内存使用率低)的进程和线程。
numaTOP 支持 PowerPC 和以下 Intel Xeon 处理器:5500 系列、6500/7500 系列、5600 系列、E7-x8xx 系列和 E5-16xx/24xx/26xx/46xx 系列。
numaTOP 在官方软件仓库中提供,您可以使用 sudo zypper in numatop 命令安装该工具。要启动 numaTOP,请运行 numatop 命令。要获取 numaTOP 功能和用法的概述,请使用 man numatop 命令。
提示:流量整形
如果网络带宽低于预期,您应该首先检查您的网络段是否激活了任何流量整形规则。
ip 是一个功能强大的工具,用于设置和控制网络接口。您还可以使用它快速查看有关系统网络接口的基本统计信息。例如,接口是否已启动,或者有多少错误、丢弃的数据包或数据包冲突。
如果您不带附加参数运行 ip,它会显示帮助输出。要列出所有网络接口,请输入 ip addr show(或缩写为 ip a)。ip addr show up 仅列出正在运行的网络接口。ip -s link show DEVICE 仅列出指定接口的统计信息
# ip -s link show br0
6: br0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT
link/ether 00:19:d1:72:d4:30 brd ff:ff:ff:ff:ff:ff
RX: bytes packets errors dropped overrun mcast
6346104756 9265517 0 10860 0 0
TX: bytes packets errors dropped carrier collsns
3996204683 3655523 0 0 0 0
ip 还可以显示接口 (link)、路由表 (route) 以及更多内容——有关详细信息,请参阅 man 8 ip。
# ip route
default via 192.168.2.1 dev eth1
192.168.2.0/24 dev eth0 proto kernel scope link src 192.168.2.100
192.168.2.0/24 dev eth1 proto kernel scope link src 192.168.2.101
192.168.2.0/24 dev eth2 proto kernel scope link src 192.168.2.102# ip link
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP mode DEFAULT group default qlen 1000
link/ether 52:54:00:44:30:51 brd ff:ff:ff:ff:ff:ff
3: eth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP mode DEFAULT group default qlen 1000
link/ether 52:54:00:a3:c1:fb brd ff:ff:ff:ff:ff:ff
4: eth2: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP mode DEFAULT group default qlen 1000
link/ether 52:54:00:32:a4:09 brd ff:ff:ff:ff:ff:ff在某些情况下,例如网络流量突然变得过高时,希望快速找出哪些应用程序正在导致流量。nethogs 是一个设计类似于 top 的工具,显示所有相关进程的传入和传出流量
PID USER PROGRAM DEV SENT RECEIVED 27145 root zypper eth0 5.719 391.749 KB/sec ? root ..0:113:80c0:8080:10:160:0:100:30015 0.102 2.326 KB/sec 26635 tux /usr/lib64/firefox/firefox eth0 0.026 0.026 KB/sec ? root ..0:113:80c0:8080:10:160:0:100:30045 0.000 0.021 KB/sec ? root ..0:113:80c0:8080:10:160:0:100:30045 0.000 0.018 KB/sec ? root ..0:113:80c0:8080:10:160:0:100:30015 0.000 0.018 KB/sec ? root ..0:113:80c0:8080:10:160:0:100:30045 0.000 0.017 KB/sec ? root ..0:113:80c0:8080:10:160:0:100:30045 0.000 0.017 KB/sec ? root ..0:113:80c0:8080:10:160:0:100:30045 0.069 0.000 KB/sec ? root unknown TCP 0.000 0.000 KB/sec TOTAL 5.916 394.192 KB/sec
与 top 一样,nethogs 具有交互式命令
| M:在显示模式之间切换(kb/s、kb、b、mb) |
| R:按排序 |
| S:按排序 |
| Q:退出 |
ethtool 可以显示和更改您的以太网网络设备的详细方面。默认情况下,它会打印指定设备的当前设置。
# ethtool eth0
Settings for eth0:
Supported ports: [ TP ]
Supported link modes: 10baseT/Half 10baseT/Full
100baseT/Half 100baseT/Full
1000baseT/Full
Supports auto-negotiation: Yes
Advertised link modes: 10baseT/Half 10baseT/Full
100baseT/Half 100baseT/Full
1000baseT/Full
Advertised pause frame use: No
[...]
Link detected: yes下表显示了您可以用来查询设备的特定信息的 ethtool 选项
表 2.1: ethtool 的查询选项列表 #
|
|
它查询设备以获取 |
|---|---|
|
-a |
暂停参数信息 |
|
-c |
中断合并信息 |
|
-g |
Rx/Tx(接收/发送)环参数信息 |
|
-i |
相关驱动程序信息 |
|
-k |
卸载信息 |
|
-S |
NIC 和驱动程序特定统计信息 |
ss 是一个用于转储套接字统计信息的工具,它取代了 netstat 命令。要列出所有连接,请不带参数使用 ss
# ss
Netid State Recv-Q Send-Q Local Address:Port Peer Address:Port
u_str ESTAB 0 0 * 14082 * 14083
u_str ESTAB 0 0 * 18582 * 18583
u_str ESTAB 0 0 * 19449 * 19450
u_str ESTAB 0 0 @/tmp/dbus-gmUUwXABPV 18784 * 18783
u_str ESTAB 0 0 /var/run/dbus/system_bus_socket 19383 * 19382
u_str ESTAB 0 0 @/tmp/dbus-gmUUwXABPV 18617 * 18616
u_str ESTAB 0 0 @/tmp/dbus-58TPPDv8qv 19352 * 19351
u_str ESTAB 0 0 * 17658 * 17657
u_str ESTAB 0 0 * 17693 * 17694
[..]要显示当前所有打开的网络端口,请使用以下命令
# ss -l
Netid State Recv-Q Send-Q Local Address:Port Peer Address:Port
nl UNCONN 0 0 rtnl:4195117 *
nl UNCONN 0 0 rtnl:wickedd-auto4/811 *
nl UNCONN 0 0 rtnl:wickedd-dhcp4/813 *
nl UNCONN 0 0 rtnl:4195121 *
nl UNCONN 0 0 rtnl:4195115 *
nl UNCONN 0 0 rtnl:wickedd-dhcp6/814 *
nl UNCONN 0 0 rtnl:kernel *
nl UNCONN 0 0 rtnl:wickedd/817 *
nl UNCONN 0 0 rtnl:4195118 *
nl UNCONN 0 0 rtnl:nscd/706 *
nl UNCONN 4352 0 tcpdiag:ss/2381 *
[...]显示网络连接时,您可以指定要显示的套接字类型:例如 TCP (-t) 或 UDP (-u)。-p 选项显示每个套接字所属程序的 PID 和名称。
以下示例列出所有 TCP 连接以及使用这些连接的程序。-a 选项确保显示所有已建立的连接(监听和非监听)。-p 选项显示每个套接字所属程序的 PID 和名称。
# ss -t -a -p
State Recv-Q Send-Q Local Address:Port Peer Address:Port
LISTEN 0 128 *:ssh *:* users:(("sshd",1551,3))
LISTEN 0 100 127.0.0.1:smtp *:* users:(("master",1704,13))
ESTAB 0 132 10.120.65.198:ssh 10.120.4.150:55715 users:(("sshd",2103,5))
LISTEN 0 128 :::ssh :::* users:(("sshd",1551,4))
LISTEN 0 100 ::1:smtp :::* users:(("master",1704,14))/proc 文件系统是一个伪文件系统,内核以虚拟文件的形式在其中保留重要信息。例如,使用此命令显示 CPU 类型
> cat /proc/cpuinfo
processor : 0
vendor_id : GenuineIntel
cpu family : 6
model : 30
model name : Intel(R) Core(TM) i5 CPU 750 @ 2.67GHz
stepping : 5
microcode : 0x6
cpu MHz : 1197.000
cache size : 8192 KB
physical id : 0
siblings : 4
core id : 0
cpu cores : 4
apicid : 0
initial apicid : 0
fpu : yes
fpu_exception : yes
cpuid level : 11
wp : yes
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx rdtscp lm constant_tsc arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc aperfmperf pni dtes64 monitor ds_cpl vmx smx est tm2 ssse3 cx16 xtpr pdcm sse4_1 sse4_2 popcnt lahf_lm ida dtherm tpr_shadow vnmi flexpriority ept vpid
bogomips : 5333.85
clflush size : 64
cache_alignment : 64
address sizes : 36 bits physical, 48 bits virtual
power management:
[...]提示:详细处理器信息
关于 AMD64/Intel 64 架构上处理器的详细信息也可以通过运行 x86info 获得。
使用以下命令查询中断的分配和使用
> cat /proc/interrupts
CPU0 CPU1 CPU2 CPU3
0: 121 0 0 0 IO-APIC-edge timer
8: 0 0 0 1 IO-APIC-edge rtc0
9: 0 0 0 0 IO-APIC-fasteoi acpi
16: 0 11933 0 0 IO-APIC-fasteoi ehci_hcd:+
18: 0 0 0 0 IO-APIC-fasteoi i801_smbus
19: 0 117978 0 0 IO-APIC-fasteoi ata_piix,+
22: 0 0 3275185 0 IO-APIC-fasteoi enp5s1
23: 417927 0 0 0 IO-APIC-fasteoi ehci_hcd:+
40: 2727916 0 0 0 HPET_MSI-edge hpet2
41: 0 2749134 0 0 HPET_MSI-edge hpet3
42: 0 0 2759148 0 HPET_MSI-edge hpet4
43: 0 0 0 2678206 HPET_MSI-edge hpet5
45: 0 0 0 0 PCI-MSI-edge aerdrv, P+
46: 0 0 0 0 PCI-MSI-edge PCIe PME,+
47: 0 0 0 0 PCI-MSI-edge PCIe PME,+
48: 0 0 0 0 PCI-MSI-edge PCIe PME,+
49: 0 0 0 387 PCI-MSI-edge snd_hda_i+
50: 933117 0 0 0 PCI-MSI-edge nvidia
NMI: 2102 2023 2031 1920 Non-maskable interrupts
LOC: 92 71 57 41 Local timer interrupts
SPU: 0 0 0 0 Spurious interrupts
PMI: 2102 2023 2031 1920 Performance monitoring int+
IWI: 47331 45725 52464 46775 IRQ work interrupts
RTR: 2 0 0 0 APIC ICR read retries
RES: 472911 396463 339792 323820 Rescheduling interrupts
CAL: 48389 47345 54113 50478 Function call interrupts
TLB: 28410 26804 24389 26157 TLB shootdowns
TRM: 0 0 0 0 Thermal event interrupts
THR: 0 0 0 0 Threshold APIC interrupts
MCE: 0 0 0 0 Machine check exceptions
MCP: 40 40 40 40 Machine check polls
ERR: 0
MIS: 0可执行文件和库的地址分配包含在 maps 文件中
> cat /proc/self/maps
08048000-0804c000 r-xp 00000000 03:03 17753 /bin/cat
0804c000-0804d000 rw-p 00004000 03:03 17753 /bin/cat
0804d000-0806e000 rw-p 0804d000 00:00 0 [heap]
b7d27000-b7d5a000 r--p 00000000 03:03 11867 /usr/lib/locale/en_GB.utf8/
b7d5a000-b7e32000 r--p 00000000 03:03 11868 /usr/lib/locale/en_GB.utf8/
b7e32000-b7e33000 rw-p b7e32000 00:00 0
b7e33000-b7f45000 r-xp 00000000 03:03 8837 /lib/libc-2.3.6.so
b7f45000-b7f46000 r--p 00112000 03:03 8837 /lib/libc-2.3.6.so
b7f46000-b7f48000 rw-p 00113000 03:03 8837 /lib/libc-2.3.6.so
b7f48000-b7f4c000 rw-p b7f48000 00:00 0
b7f52000-b7f53000 r--p 00000000 03:03 11842 /usr/lib/locale/en_GB.utf8/
[...]
b7f5b000-b7f61000 r--s 00000000 03:03 9109 /usr/lib/gconv/gconv-module
b7f61000-b7f62000 r--p 00000000 03:03 9720 /usr/lib/locale/en_GB.utf8/
b7f62000-b7f76000 r-xp 00000000 03:03 8828 /lib/ld-2.3.6.so
b7f76000-b7f78000 rw-p 00013000 03:03 8828 /lib/ld-2.3.6.so
bfd61000-bfd76000 rw-p bfd61000 00:00 0 [stack]
ffffe000-fffff000 ---p 00000000 00:00 0 [vdso]可以从 /proc 文件系统获取更多信息。一些重要的文件及其内容是
/proc/devices可用设备
/proc/modules已加载的内核模块
/proc/cmdline内核命令行
/proc/meminfo内存使用情况的详细信息
/proc/config.gz当前运行的内核的
gzip压缩配置文件- /proc/PID/
在
/proc/NNN 目录中查找有关当前运行进程的信息,其中 NNN 是相关进程的进程 ID (PID)。每个进程都可以在/proc/self/中找到自己的特性。
更多信息可在文本文件 /usr/src/linux/Documentation/filesystems/proc.txt 中获得(安装 kernel-source 软件包时此文件可用)。
procinfo 命令总结了 /proc 文件系统中的重要信息
> procinfo
Linux 3.11.10-17-desktop (geeko@buildhost) (gcc 4.8.1 20130909) #1 4CPU [jupiter.example.com]
Memory: Total Used Free Shared Buffers Cached
Mem: 8181908 8000632 181276 0 85472 2850872
Swap: 10481660 1576 10480084
Bootup: Mon Jul 28 09:54:13 2014 Load average: 1.61 0.85 0.74 2/904 25949
user : 1:54:41.84 12.7% page in : 2107312 disk 1: 52212r 20199w
nice : 0:00:00.46 0.0% page out: 1714461 disk 2: 19387r 10928w
system: 0:25:38.00 2.8% page act: 466673 disk 3: 548r 10w
IOwait: 0:04:16.45 0.4% page dea: 272297
hw irq: 0:00:00.42 0.0% page flt: 105754526
sw irq: 0:01:26.48 0.1% swap in : 0
idle : 12:14:43.65 81.5% swap out: 394
guest : 0:02:18.59 0.2%
uptime: 3:45:22.24 context : 99809844
irq 0: 121 timer irq 41: 3238224 hpet3
irq 8: 1 rtc0 irq 42: 3251898 hpet4
irq 9: 0 acpi irq 43: 3156368 hpet5
irq 16: 14589 ehci_hcd:usb1 irq 45: 0 aerdrv, PCIe PME
irq 18: 0 i801_smbus irq 46: 0 PCIe PME, pciehp
irq 19: 124861 ata_piix, ata_piix, f irq 47: 0 PCIe PME, pciehp
irq 22: 3742817 enp5s1 irq 48: 0 PCIe PME, pciehp
irq 23: 479248 ehci_hcd:usb2 irq 49: 387 snd_hda_intel
irq 40: 3216894 hpet2 irq 50: 1088673 nvidia要查看所有信息,请使用参数 -a。参数 -nN 会每 N 秒更新一次信息。在这种情况下,按 Q 停止程序。
默认情况下,显示累积值。参数 -d 生成差分值。procinfo -dn5 显示过去五秒内更改的值
系统控制参数用于在运行时修改 Linux 内核参数。它们位于 /proc/sys/ 中,可以使用 sysctl 命令进行查看和修改。要列出所有参数,请运行 sysctl -a。可以使用 sysctl PARAMETER_NAME 列出单个参数。
参数按类别分组,可以使用 sysctl CATEGORY 或列出相应目录的内容来列出。下面列出了最重要的类别。要查看进一步阅读的链接,需要安装 kernel-source 软件包。
sysctl dev(/proc/sys/dev/)设备特定信息。
sysctl fs(/proc/sys/fs/)使用的文件句柄、配额和其他面向文件系统的参数。有关详细信息,请参阅
/usr/src/linux/Documentation/sysctl/fs.txt。sysctl kernel(/proc/sys/kernel/)有关任务调度程序、系统共享内存和其他内核相关参数的信息。有关详细信息,请参阅
/usr/src/linux/Documentation/sysctl/kernel.txtsysctl net(/proc/sys/net/)有关网络桥接器和通用网络参数的信息(主要是
ipv4/子目录)。有关详细信息,请参阅/usr/src/linux/Documentation/sysctl/net.txtsysctl vm(/proc/sys/vm/)此路径中的条目与虚拟内存、交换和缓存的信息相关。有关详细信息,请参阅
/usr/src/linux/Documentation/sysctl/vm.txt
要设置或更改当前会话的参数,请使用命令 sysctl -w PARAMETER=VALUE。要永久更改设置,请将一行 PARAMETER=VALUE 添加到 /etc/sysctl.conf。
注意:访问 PCI 配置。
大多数操作系统要求 root 用户权限才能授予对计算机 PCI 配置的访问权限。
命令 lspci 列出 PCI 资源
# lspci
00:00.0 Host bridge: Intel Corporation 82845G/GL[Brookdale-G]/GE/PE \
DRAM Controller/Host-Hub Interface (rev 01)
00:01.0 PCI bridge: Intel Corporation 82845G/GL[Brookdale-G]/GE/PE \
Host-to-AGP Bridge (rev 01)
00:1d.0 USB Controller: Intel Corporation 82801DB/DBL/DBM \
(ICH4/ICH4-L/ICH4-M) USB UHCI Controller #1 (rev 01)
00:1d.1 USB Controller: Intel Corporation 82801DB/DBL/DBM \
(ICH4/ICH4-L/ICH4-M) USB UHCI Controller #2 (rev 01)
00:1d.2 USB Controller: Intel Corporation 82801DB/DBL/DBM \
(ICH4/ICH4-L/ICH4-M) USB UHCI Controller #3 (rev 01)
00:1d.7 USB Controller: Intel Corporation 82801DB/DBM \
(ICH4/ICH4-M) USB2 EHCI Controller (rev 01)
00:1e.0 PCI bridge: Intel Corporation 82801 PCI Bridge (rev 81)
00:1f.0 ISA bridge: Intel Corporation 82801DB/DBL (ICH4/ICH4-L) \
LPC Interface Bridge (rev 01)
00:1f.1 IDE interface: Intel Corporation 82801DB (ICH4) IDE \
Controller (rev 01)
00:1f.3 SMBus: Intel Corporation 82801DB/DBL/DBM (ICH4/ICH4-L/ICH4-M) \
SMBus Controller (rev 01)
00:1f.5 Multimedia audio controller: Intel Corporation 82801DB/DBL/DBM \
(ICH4/ICH4-L/ICH4-M) AC'97 Audio Controller (rev 01)
01:00.0 VGA compatible controller: Matrox Graphics, Inc. G400/G450 (rev 85)
02:08.0 Ethernet controller: Intel Corporation 82801DB PRO/100 VE (LOM) \
Ethernet Controller (rev 81)使用 -v 会生成更详细的列表
# lspci -v
[...]
00:03.0 Ethernet controller: Intel Corporation 82540EM Gigabit Ethernet \
Controller (rev 02)
Subsystem: Intel Corporation PRO/1000 MT Desktop Adapter
Flags: bus master, 66MHz, medium devsel, latency 64, IRQ 19
Memory at f0000000 (32-bit, non-prefetchable) [size=128K]
I/O ports at d010 [size=8]
Capabilities: [dc] Power Management version 2
Capabilities: [e4] PCI-X non-bridge device
Kernel driver in use: e1000
Kernel modules: e1000设备名称解析的信息从文件 /usr/share/pci.ids 中获取。未在此文件中列出的 PCI ID 被标记为“未知设备”。
参数 -vv 生成程序可以查询的所有信息。要查看纯数字值,请使用参数 -n。
命令 lsusb 列出所有 USB 设备。使用选项 -v,打印更详细的列表。详细信息从目录 /proc/bus/usb/ 读取。以下是 lsusb 在连接了这些 USB 设备(集线器、记忆棒、硬盘和鼠标)时的输出。
# lsusb
Bus 004 Device 007: ID 0ea0:2168 Ours Technology, Inc. Transcend JetFlash \
2.0 / Astone USB Drive
Bus 004 Device 006: ID 04b4:6830 Cypress Semiconductor Corp. USB-2.0 IDE \
Adapter
Bus 004 Device 005: ID 05e3:0605 Genesys Logic, Inc.
Bus 004 Device 001: ID 0000:0000
Bus 003 Device 001: ID 0000:0000
Bus 002 Device 001: ID 0000:0000
Bus 001 Device 005: ID 046d:c012 Logitech, Inc. Optical Mouse
Bus 001 Device 001: ID 0000:0000
tmon 是一个工具,用于帮助可视化、调优和测试复杂的热子系统。不带参数启动时,tmon 以监控模式运行
┌──────THERMAL ZONES(SENSORS)──────────────────────────────┐ │Thermal Zones: acpitz00 │ │Trip Points: PC │ └──────────────────────────────────────────────────────────┘ ┌─────────── COOLING DEVICES ──────────────────────────────┐ │ID Cooling Dev Cur Max Thermal Zone Binding │ │00 Processor 0 3 ││││││││││││ │ │01 Processor 0 3 ││││││││││││ │ │02 Processor 0 3 ││││││││││││ │ │03 Processor 0 3 ││││││││││││ │ │04 intel_powerc -1 50 ││││││││││││ │ └──────────────────────────────────────────────────────────┘ ┌──────────────────────────────────────────────────────────┐ │ 10 20 30 40 │ │acpitz 0:[ 8][>>>>>>>>>P9 C31 │ └──────────────────────────────────────────────────────────┘ ┌────────────────── CONTROLS ──────────────────────────────┐ │PID gain: kp=0.36 ki=5.00 kd=0.19 Output 0.00 │ │Target Temp: 65.0C, Zone: 0, Control Device: None │ └──────────────────────────────────────────────────────────┘ Ctrl-c - Quit TAB - Tuning
有关如何解释数据、如何记录热数据以及如何使用 tmon 测试和调优冷却设备和传感器的详细信息,请参阅手册页:man 8 tmon。tmon 软件包默认不安装。
注意:可用性
此工具仅在 AMD64/Intel 64 系统上可用。
mcelog 软件包可记录并解析/转换硬件错误(包括 I/O、CPU 和内存错误)导致的机器检查异常 (MCE)。此外,mcelog 还会处理预测性坏页脱机和发生缓存错误时的自动核心脱机。以前,这些功能通过每小时执行一次的 cron 作业来管理。现在,硬件错误由 mcelog 守护进程立即处理。
注:支持 AMD 可扩展 MCA
openSUSE Leap 支持 AMD 的可扩展机器检查架构 (Scalable MCA)。Scalable MCA 改进了 AMD Zen 处理器中的硬件错误报告。它扩展了 MCA 库中记录的信息,以改进错误处理和诊断能力。
mcelog 捕获 MCA 消息(rasdaemon 和 dmesg 也会捕获 MCA 消息)。有关详细信息,请参阅《适用于 AMD Family 17h Model 01h, Revision B1 处理器的处理器编程参考 (PPR)》第 3.1 节“机器检查架构”,https://developer.amd.com/wordpress/media/2017/11/54945_PPR_Family_17h_Models_00h-0Fh.pdf。
mcelog 在 /etc/mcelog/mcelog.conf 中配置。配置选项在 man mcelog 和 https://mcelog.org/ 中有说明。以下示例仅显示对默认文件的更改
daemon = yes filter = yes filter-memory-errors = yes no-syslog = yes logfile = /var/log/mcelog run-credentials-user = root run-credentials-group = nobody client-group = root socket-path = /var/run/mcelog-client
mcelog 服务默认未启用。该服务可以通过 YaST 系统服务编辑器启用和启动,也可以通过命令行启用和启动
#systemctl enable mcelog#systemctl start mcelog
dmidecode 显示机器的 DMI 表,其中包含硬件的序列号和 BIOS 修订版等信息。
# dmidecode
# dmidecode 2.12
SMBIOS 2.5 present.
27 structures occupying 1298 bytes.
Table at 0x000EB250.
Handle 0x0000, DMI type 4, 35 bytes
Processor Information
Socket Designation: J1PR
Type: Central Processor
Family: Other
Manufacturer: Intel(R) Corporation
ID: E5 06 01 00 FF FB EB BF
Version: Intel(R) Core(TM) i5 CPU 750 @ 2.67GHz
Voltage: 1.1 V
External Clock: 133 MHz
Max Speed: 4000 MHz
Current Speed: 2667 MHz
Status: Populated, Enabled
Upgrade: Other
L1 Cache Handle: 0x0004
L2 Cache Handle: 0x0003
L3 Cache Handle: 0x0001
Serial Number: Not Specified
Asset Tag: Not Specified
Part Number: Not Specified
[..]file 命令通过检查 /usr/share/misc/magic 来确定文件或文件列表的类型。
> file /usr/bin/file
/usr/bin/file: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), \
for GNU/Linux 2.6.4, dynamically linked (uses shared libs), stripped参数 -f LIST 指定一个包含要检查的文件名列表的文件。-z 允许 file 查看压缩文件
>file /usr/share/man/man1/file.1.gz /usr/share/man/man1/file.1.gz: gzip compressed data, from Unix, max compression>file -z /usr/share/man/man1/file.1.gz /usr/share/man/man1/file.1.gz: troff or preprocessor input text \ (gzip compressed data, from Unix, max compression)
参数 -i 输出 MIME 类型字符串而不是传统描述。
> file -i /usr/share/misc/magic
/usr/share/misc/magic: text/plain charset=utf-8mount 命令显示哪个文件系统(设备和类型)挂载在哪个挂载点上
# mount
/dev/sda2 on / type ext4 (rw,acl,user_xattr)
proc on /proc type proc (rw)
sysfs on /sys type sysfs (rw)
debugfs on /sys/kernel/debug type debugfs (rw)
devtmpfs on /dev type devtmpfs (rw,mode=0755)
tmpfs on /dev/shm type tmpfs (rw,mode=1777)
devpts on /dev/pts type devpts (rw,mode=0620,gid=5)
/dev/sda3 on /home type ext3 (rw)
securityfs on /sys/kernel/security type securityfs (rw)
fusectl on /sys/fs/fuse/connections type fusectl (rw)
gvfs-fuse-daemon on /home/tux/.gvfs type fuse.gvfs-fuse-daemon \
(rw,nosuid,nodev,user=tux)使用 df 命令获取有关文件系统总使用情况的信息。参数 -h(或 --human-readable)将输出转换为普通用户可理解的形式。
> df -h
Filesystem Size Used Avail Use% Mounted on
/dev/sda2 20G 5,9G 13G 32% /
devtmpfs 1,6G 236K 1,6G 1% /dev
tmpfs 1,6G 668K 1,6G 1% /dev/shm
/dev/sda3 208G 40G 159G 20% /home使用 du 命令显示给定目录及其子目录中所有文件的总大小。参数 -s 抑制详细信息的输出,只给出每个参数的总大小。-h 再次将输出转换为人类可读的形式
> du -sh /opt
192M /opt使用 readelf 实用程序读取二进制文件的内容。即使是为其他硬件架构构建的 ELF 文件也适用
> readelf --file-header /bin/ls
ELF Header:
Magic: 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00
Class: ELF64
Data: 2's complement, little endian
Version: 1 (current)
OS/ABI: UNIX - System V
ABI Version: 0
Type: EXEC (Executable file)
Machine: Advanced Micro Devices X86-64
Version: 0x1
Entry point address: 0x402540
Start of program headers: 64 (bytes into file)
Start of section headers: 95720 (bytes into file)
Flags: 0x0
Size of this header: 64 (bytes)
Size of program headers: 56 (bytes)
Number of program headers: 9
Size of section headers: 64 (bytes)
Number of section headers: 32
Section header string table index: 31stat 命令显示文件属性
> stat /etc/profile
File: `/etc/profile'
Size: 9662 Blocks: 24 IO Block: 4096 regular file
Device: 802h/2050d Inode: 132349 Links: 1
Access: (0644/-rw-r--r--) Uid: ( 0/ root) Gid: ( 0/ root)
Access: 2009-03-20 07:51:17.000000000 +0100
Modify: 2009-01-08 19:21:14.000000000 +0100
Change: 2009-03-18 12:55:31.000000000 +0100参数 --file-system 生成指定文件所在文件系统属性的详细信息
> stat /etc/profile --file-system
File: "/etc/profile"
ID: d4fb76e70b4d1746 Namelen: 255 Type: ext2/ext3
Block size: 4096 Fundamental block size: 4096
Blocks: Total: 2581445 Free: 1717327 Available: 1586197
Inodes: Total: 655776 Free: 490312确定哪些进程或用户当前正在访问某些文件可能很有用。例如,假设您想要卸载挂载在 /mnt 上的文件系统。umount 返回“device is busy”。然后可以使用 fuser 命令来确定哪些进程正在访问该设备
> fuser -v /mnt/*
USER PID ACCESS COMMAND
/mnt/notes.txt tux 26597 f.... less在终止在另一个终端上运行的 less 进程后,文件系统可以成功卸载。当与 -k 选项一起使用时,fuser 也会停止访问该文件的进程。
使用 w 命令,查明谁登录到系统以及每个用户正在做什么。例如
> w
16:00:59 up 1 day, 2:41, 3 users, load average: 0.00, 0.01, 0.05
USER TTY FROM LOGIN@ IDLE JCPU PCPU WHAT
tux :0 console Wed13 ?xdm? 8:15 0.03s /usr/lib/gdm/gd
tux console :0 Wed13 26:41m 0.00s 0.03s /usr/lib/gdm/gd
tux pts/0 :0 Wed13 20:11 0.10s 2.89s /usr/lib/gnome-如果有其他系统的用户远程登录,参数 -f 显示他们建立连接的计算机。
使用 time 实用程序确定命令花费的时间。此实用程序有两个版本:作为 Bash 内置命令和作为程序 (/usr/bin/time)。
> time find . > /dev/null
real 0m4.051s1
user 0m0.042s2
sys 0m0.205s3/usr/bin/time 的输出要详细得多。建议使用 -v 开关运行它以生成人类可读的输出。
/usr/bin/time -v find . > /dev/null
Command being timed: "find ."
User time (seconds): 0.24
System time (seconds): 2.08
Percent of CPU this job got: 25%
Elapsed (wall clock) time (h:mm:ss or m:ss): 0:09.03
Average shared text size (kbytes): 0
Average unshared data size (kbytes): 0
Average stack size (kbytes): 0
Average total size (kbytes): 0
Maximum resident set size (kbytes): 2516
Average resident set size (kbytes): 0
Major (requiring I/O) page faults: 0
Minor (reclaiming a frame) page faults: 1564
Voluntary context switches: 36660
Involuntary context switches: 496
Swaps: 0
File system inputs: 0
File system outputs: 0
Socket messages sent: 0
Socket messages received: 0
Signals delivered: 0
Page size (bytes): 4096
Exit status: 0您周围有很多数据可以轻松地随时间测量。例如,温度变化,或者计算机网络接口发送或接收的数据量。RRDtool 可以帮助您将此类数据存储并可视化为详细且可自定义的图表。
RRDtool 适用于大多数 Unix 平台和 Linux 发行版。openSUSE® Leap 也附带 RRDtool。您可以使用 YaST 安装它,或者在命令行中以 root 身份输入
zypper install rrdtool。
提示:绑定
RRDtool 提供了 Perl、Python、Ruby 和 PHP 绑定,因此您可以使用自己喜欢的脚本语言编写自己的监控脚本。
RRDtool 是 Round Robin Database tool 的缩写。Round Robin 是一种处理恒定数据量的方法。它使用循环缓冲区的原理,其中正在读取的数据行没有结束也没有开始。RRDtool 使用 Round Robin 数据库来存储和读取其数据。
如上所述,RRDtool 旨在处理随时间变化的数据。理想情况是传感器以恒定的时间周期重复读取测量数据(如温度、速度等),然后以给定格式导出。此类数据非常适合 RRDtool,并且易于处理并创建所需的输出。
有时无法自动定期获取数据。在将其提供给 RRDtool 之前,需要对其格式进行预处理,并且通常您需要手动操作 RRDtool。
以下是 RRDtool 基本用法的简单示例。它说明了通常 RRDtool 工作流程的所有三个重要阶段:创建数据库、更新测量值以及查看输出。
假设我们想要收集和查看 Linux 系统中内存使用情况随时间变化的信息。为了使示例更生动,我们以 4 秒的间隔测量 40 秒内当前可用内存。启动并关闭了通常会消耗大量系统内存的三个应用程序:Firefox Web 浏览器、Evolution 电子邮件客户端和 Eclipse 开发框架。
RRDtool 经常用于测量和可视化网络流量。在这种情况下,使用简单网络管理协议 (SNMP)。该协议可以查询网络设备的相关内部计数器值。正是这些值要用 RRDtool 存储。有关 SNMP 的更多信息,请参阅 http://www.net-snmp.org/。
我们的情况不同——我们需要手动获取数据。一个辅助脚本 free_mem.sh 重复读取当前可用内存的状态并将其写入标准输出。
> cat free_mem.sh
INTERVAL=4
for steps in {1..10}
do
DATE=`date +%s`
FREEMEM=`free -b | grep "Mem" | awk '{ print $4 }'`
sleep $INTERVAL
echo "rrdtool update free_mem.rrd $DATE:$FREEMEM"
done时间间隔设置为 4 秒,并使用
sleep命令实现。RRDtool 接受特殊格式的时间信息——即所谓的Unix 时间。它定义为自 1970 年 1 月 1 日午夜 (UTC) 以来的秒数。例如,1272907114 表示 2010-05-03 17:18:34。
可用内存信息以字节为单位报告,使用
free-b。首选提供基本单位(字节)而不是多个单位(如千字节)。带有
echo ...命令的行包含数据库文件的未来名称 (free_mem.rrd),并一起创建用于更新 RRDtool 值的命令行。
运行 free_mem.sh 后,您会看到类似于此的输出
> sh free_mem.sh
rrdtool update free_mem.rrd 1272974835:1182994432
rrdtool update free_mem.rrd 1272974839:1162817536
rrdtool update free_mem.rrd 1272974843:1096269824
rrdtool update free_mem.rrd 1272974847:1034219520
rrdtool update free_mem.rrd 1272974851:909438976
rrdtool update free_mem.rrd 1272974855:832454656
rrdtool update free_mem.rrd 1272974859:829120512
rrdtool update free_mem.rrd 1272974863:1180377088
rrdtool update free_mem.rrd 1272974867:1179369472
rrdtool update free_mem.rrd 1272974871:1181806592方便地将命令的输出重定向到文件,如下所示
sh free_mem.sh > free_mem_updates.log
以简化其未来的执行。
使用以下命令为我们的示例创建初始 Round Robin 数据库
> rrdtool create free_mem.rrd --start 1272974834 --step=4 \
DS:memory:GAUGE:600:U:U RRA:AVERAGE:0.5:1:24需要注意的地方 #
此命令创建名为
free_mem.rrd的文件,用于将测量值存储在 Round Robin 类型数据库中。--start选项指定将第一个值添加到数据库的时间(以 Unix 时间表示)。在此示例中,它比free_mem.sh输出的第一个时间值 (1272974835) 少一。--step指定将测量数据提供给数据库的时间间隔(以秒为单位)。DS:memory:GAUGE:600:U:U部分为数据库引入了一个新的数据源。它名为memory,类型为gauge,两次更新之间的最大秒数为 600 秒,测量范围内的最小值和最大值未知 (U)。RRA:AVERAGE:0.5:1:24创建 Round Robin 档案 (RRA),其存储数据通过合并函数 (CF) 处理,该函数计算数据点的平均值。合并函数的 3 个参数附加到行尾。
如果没有显示错误消息,则会在当前目录中创建 free_mem.rrd 数据库
> ls -l free_mem.rrd
-rw-r--r-- 1 tux users 776 May 5 12:50 free_mem.rrd创建数据库后,需要用测量数据填充它。在第 2.11.2.1 节 “收集数据”中,我们已经准备好了文件 free_mem_updates.log,它由 rrdtool update 命令组成。这些命令为我们更新数据库值。
> sh free_mem_updates.log; ls -l free_mem.rrd
-rw-r--r-- 1 tux users 776 May 5 13:29 free_mem.rrd如您所见,即使更新了数据,free_mem.rrd 的大小也保持不变。
我们已经测量了值,创建了数据库,并将测量值存储在其中。现在我们可以使用数据库,并检索或查看其值。
要从数据库中检索所有值,请在命令行中输入以下内容
> rrdtool fetch free_mem.rrd AVERAGE --start 1272974830 \
--end 1272974871
memory
1272974832: nan
1272974836: 1.1729059840e+09
1272974840: 1.1461806080e+09
1272974844: 1.0807572480e+09
1272974848: 1.0030243840e+09
1272974852: 8.9019289600e+08
1272974856: 8.3162112000e+08
1272974860: 9.1693465600e+08
1272974864: 1.1801251840e+09
1272974868: 1.1799787520e+09
1272974872: nan需要注意的地方 #
AVERAGE从数据库中获取平均值点,因为只定义了一个数据源(第 2.11.2.2 节 “创建数据库”)并使用AVERAGE处理,没有其他函数可用。输出的第一行打印在第 2.11.2.2 节 “创建数据库”中定义的数据源名称。
左侧结果列表示单个时间点,而右侧结果列表示科学记数法中相应的测量平均值。
最后一行的
nan表示“非数字”。
现在绘制表示数据库中存储值的图表
> rrdtool graph free_mem.png \
--start 1272974830 \
--end 1272974871 \
--step=4 \
DEF:free_memory=free_mem.rrd:memory:AVERAGE \
LINE2:free_memory#FF0000 \
--vertical-label "GB" \
--title "Free System Memory in Time" \
--zoom 1.5 \
--x-grid SECOND:1:SECOND:4:SECOND:10:0:%X需要注意的地方 #
free_mem.png是要创建的图表的文件名。--start和--end限制绘制图表的时间范围。--step指定图表的时间分辨率(以秒为单位)。DEF:...部分是名为free_memory的数据定义。其数据从free_mem.rrd数据库及其名为memory的数据源读取。平均值点已计算,因为在第 2.11.2.2 节 “创建数据库”中未定义其他值。LINE...部分指定要绘制到图表中的线的属性。它宽 2 像素,其数据来自free_memory定义,颜色为红色。--vertical-label设置沿y轴打印的标签,--title设置整个图表的主标签。--zoom指定图表的缩放因子。此值必须大于零。--x-grid指定如何在图表中绘制网格线及其标签。我们的示例将其每秒放置一次,而主要网格线每 4 秒放置一次。标签每 10 秒放置一次在主要网格线下方。

图 2.1: 使用 RRDtool 创建的示例图表 #
RRDtool 是一个复杂的工具,包含许多子命令和命令行选项。有些很容易理解,但要使它们产生您想要的结果并根据您的喜好进行微调可能需要付出很多努力。
除了 RRDtool 的手册页 (man 1 rrdtool) 仅提供基本信息外,您还应该查看 RRDtool 主页。那里有关于 rrdtool 命令及其所有子命令的详细文档。还有几个教程可以帮助您了解常见的 RRDtool 工作流程。
如果您对监控网络流量感兴趣,请查看 MRTG (Multi Router Traffic Grapher)。MRTG 可以绘制许多网络设备的活动图。它可以使用 RRDtool。
系统日志文件分析是分析系统最重要的任务之一。实际上,在维护或排除系统故障时,查看系统日志文件应该是首要任务。openSUSE Leap 会自动详细记录系统上发生的所有事件。自迁移到 systemd 以来,内核消息和使用 systemd 注册的系统服务的消息都记录在 systemd 日志中(请参阅《参考》一书,第 11 章“journalctl:查询 systemd 日志”)。其他日志文件(主要是系统应用程序的日志文件)以纯文本形式写入,可以使用编辑器或分页器轻松读取。也可以使用脚本解析它们。这允许您过滤其内容。
系统日志文件始终位于 /var/log 目录下。以下列表概述了默认安装后 openSUSE Leap 中的所有系统日志文件。根据您的安装范围,/var/log 还包含此处未列出的其他服务和应用程序的日志文件。下面描述的一些文件和目录是“占位符”,仅在安装相应应用程序时使用。大多数日志文件只对 root 用户可见。
apparmor/AppArmor 日志文件。有关 AppArmor 的更多信息,请参阅《安全和强化指南》。
audit/审计框架的日志。有关详细信息,请参阅《安全和强化指南》。
ConsoleKit/ConsoleKit守护进程的日志(用于跟踪哪些用户已登录以及他们如何与计算机交互的守护进程)。cups/通用 Unix 打印系统 (
cups) 的访问和错误日志。firewall防火墙日志。
gdm/GNOME 显示管理器中的日志文件。
krb5/Kerberos 网络认证系统中的日志文件。
lastlog包含每个用户上次登录信息的数据库。使用
lastlog命令查看。有关更多信息,请参阅man 8 lastlog。localmessages某些启动脚本的日志消息,例如 DHCP 客户端的日志。
mail*邮件服务器 (
postfix,sendmail) 日志。messages这是所有内核和系统日志消息的默认存放位置,在出现问题时应首先查看此处(以及
/var/log/warn)。NetworkManagerNetworkManager 日志文件。
news/新闻服务器的日志消息。
chrony/网络时间协议守护进程 (
chrony) 的日志。pk_backend_zypp*PackageKit(带有
libzypp后端)日志文件。samba/Samba(Windows SMB/CIFS 文件服务器)的日志文件。
warn所有系统警告和错误的日志。在出现问题时,此处(以及
systemd日志的输出)应该是首先查看的地方。wtmp所有登录/注销活动和远程连接的数据库。使用
last命令查看。有关更多信息,请参阅man 1 last。Xorg.NUMBER.logX.Org 启动日志文件。如果启动 X.Org 时遇到问题,请查阅这些文件。
文件名中的 NUMBER 是显示器编号。例如,默认的
Xorg.0.log是显示器编号0的日志,Xorg.1.log是显示器编号1的日志。先前 X.Org 启动的副本命名为Xorg.NUMBER.log.old。注意
X.Org 日志文件仅在您以
root身份启动 X.Org 会话时才在/var/log/目录中可用。如果您以任何其他用户身份启动 X.Org 会话,则可以在~/.local/share/xorg/目录中找到日志文件。YaST2/所有 YaST 日志文件。
zypp/libzypp日志文件。有关软件包安装历史记录,请参阅这些文件。zypper.log命令行安装程序
zypper的日志。
要查看日志文件,您可以使用任何文本编辑器。YaST 控制中心中的 › 下也提供了一个用于查看系统日志的简单 YaST 模块。
要在文本控制台中查看日志文件,请使用 less 或 more 命令。使用 head 和 tail 查看日志文件的开头或结尾。要实时查看附加到日志文件的条目,请使用 tail -f。有关如何使用这些工具的信息,请参阅其手册页。
要在日志文件中搜索字符串或正则表达式,请使用 grep。awk 对于解析和重写日志文件很有用。
/var/log 下的日志文件每天都会增长,并很快变得很大。logrotate 是一个帮助您管理日志文件及其增长的工具。它允许自动轮换、删除、压缩和邮寄日志文件。日志文件可以定期处理(每日、每周或每月)或在超过特定大小时处理。
logrotate 每天由 systemd 运行,因此每天只修改日志文件一次。但是,如果日志文件因其大小而修改,或者 logrotate 每天运行多次,或者启用 --force,则会发生例外。使用 /var/lib/misc/logrotate.status 查找特定文件上次轮换的时间。
logrotate 的主配置文件是 /etc/logrotate.conf。生成日志文件的系统软件包和程序(例如,apache2)将其自己的配置文件放在 /etc/logrotate.d/ 目录中。/etc/logrotate.d/ 的内容通过 /etc/logrotate.conf 包含。
示例 3.1: /etc/logrotate.conf 示例 #
# see "man logrotate" for details # rotate log files weekly weekly # keep 4 weeks worth of backlogs rotate 4 # create new (empty) log files after rotating old ones create # use date as a suffix of the rotated file dateext # uncomment this if you want your log files compressed #compress # comment these to switch compression to use gzip or another # compression scheme compresscmd /usr/bin/bzip2 uncompresscmd /usr/bin/bunzip2 # RPM packages drop log rotation information into this directory include /etc/logrotate.d
重要:避免权限冲突
create 选项会考虑 /etc/permissions* 中指定的文件模式和所有权。如果您修改这些设置,请确保不会出现冲突。
logwatch 是一个可自定义、可插拔的日志监控脚本。它解析系统日志,提取重要信息并以人类可读的方式呈现。要使用 logwatch,请安装 logwatch 软件包。
logwatch 可以在命令行上用于即时生成报告,也可以通过 cron 定期创建自定义报告。报告可以打印在屏幕上,保存到文件,或邮寄到指定地址。后者在使用 cron 自动生成报告时特别有用。
在命令行上,您可以告诉 logwatch 为哪个服务和时间范围生成报告,以及应包含多少细节
# Detailed report on all kernel messages from yesterday logwatch --service kernel --detail High --range Yesterday --print # Low detail report on all sshd events recorded (incl. archived logs) logwatch --service sshd --detail Low --range All --archives --print # Mail a report on all smartd messages from May 5th to May 7th to root@localhost logwatch --service smartd --range 'between 5/5/2005 and 5/7/2005' \ --mailto root@localhost --print
--range 选项具有复杂的语法——有关详细信息,请参阅 logwatch --range help。可以使用以下命令获取可查询的所有服务列表
> ls /usr/share/logwatch/default.conf/services/ | sed 's/\.conf//g'
logwatch 可以进行非常详细的自定义。但是,默认配置应该足够了。默认配置文件位于 /usr/share/logwatch/default.conf/。切勿更改它们,因为它们会在下次更新时被覆盖。相反,将自定义配置放置在 /etc/logwatch/conf/ 中(您可以使用默认配置文件作为模板)。有关自定义 logwatch 的详细操作方法可在 /usr/share/doc/packages/logwatch/HOWTO-Customize-LogWatch 中找到。存在以下配置文件
logwatch.conf主配置文件。默认版本注释详细。每个配置选项都可以在命令行上覆盖。
ignore.conf过滤掉
logwatch应全局忽略的所有行。services/*.conf服务目录包含每个可以生成报告的服务的配置文件。
logfiles/*.conf指定每个服务应解析的日志文件。
系统守护程序、cron 作业、systemd 计时器和其他应用程序可以生成消息并将其发送给系统的 root 用户。默认情况下,每个用户帐户都拥有一个本地邮箱,并在登录时收到新邮件消息的通知。
这些消息可能包含与安全相关的报告和事件,需要系统管理员快速响应。为了及时收到这些消息的通知,强烈建议将这些邮件转发到定期检查的专用远程电子邮件帐户。
过程 3.1: 为 root 用户配置邮件转发 #
要转发 root 用户的邮件,请执行以下步骤
安装 yast2-mail 软件包
#zypper in yast2-mail运行交互式 YaST 邮件配置
#yast mail选择作为,然后继续。
输入的地址。如有必要,配置。强烈建议以防止潜在的敏感系统数据通过网络未加密发送。继续。
输入要的电子邮件地址,然后配置。
重要提示:不要接受远程 SMTP 连接
不要启用,否则本地机器将充当邮件中继。
发送消息以测试邮件转发是否正常工作
>mail rootsubject: test test .使用
mailq命令验证测试消息是否已发送。成功后,队列应为空。消息应由先前配置的专用邮件地址接收。
根据管理机器的数量和需要通知系统事件的人员数量,可以建立不同的电子邮件地址模型
将不同系统中的消息收集到一个电子邮件帐户中,该帐户仅由一个人访问。
将不同系统中的消息收集到可以由所有相关人员访问的群组电子邮件帐户(别名或邮件列表)中。
为每个系统创建单独的电子邮件帐户。
管理员定期检查相关电子邮件帐户至关重要。为方便此项工作并识别重要事件,请避免发送不必要的信息。配置应用程序仅发送相关信息。
系统日志数据可以从各个系统转发到网络上的中央 syslog 服务器。这允许管理员全面了解所有主机上的事件,并防止成功控制系统的攻击者操纵系统日志以掩盖他们的踪迹。
设置中央 syslog 服务器包括两个部分。首先配置中央日志服务器,然后配置客户端进行远程日志记录。
过程 3.2: 配置中央 rsyslog 服务器 #
要设置中央 syslog 服务器,请执行以下步骤
编辑配置文件
/etc/rsyslog.d/remote.conf。取消注释配置文件中
UDP Syslog Server或TCP Syslog Server部分的以下行。为rsyslogd分配 IP 地址和端口。TCP 示例
$ModLoad imtcp.so $UDPServerAddress IP1 $InputTCPServerRun PORT2
UDP 示例
重要:TCP 与 UDP 协议
传统上,syslog 使用 UDP 协议通过网络传输日志消息。这涉及的开销较小,但缺乏可靠性。在高负载下,日志消息可能会丢失。
TCP 协议更可靠,应优先于 UDP。
注意:带 TCP 的
UDPServerAddressTCP 示例中的
$UDPServerAddress配置参数没有错误。尽管其名称如此,但它同时用于 TCP 和 UDP。保存文件。
重启
rsyslog服务>sudosystemctl restart rsyslog.service在防火墙中打开相应的端口。对于在端口 514 上使用 TCP 的
firewalld,运行>sudofirewall-cmd --add-port 514/tcp --permanent>sudofirewall-cmd --reload
您现在已配置中央 syslog 服务器。接下来,配置客户端进行远程日志记录。
过程 3.3: 配置 rsyslog 实例进行远程日志记录 #
要配置机器以远程日志记录到中央 syslog 服务器,请执行以下步骤
编辑配置文件
/etc/rsyslog.d/remote.conf。取消注释相应的行(TCP 或 UDP),并将
remote-host替换为在第 3.6.1 节 “设置中央 syslog 服务器”中设置的中央 syslog 服务器的地址。TCP 示例
# Remote Logging using TCP for reliable delivery # remote host is: name/ip:port, e.g. 192.168.0.1:514, port optional *.* @@remote-host
UDP 示例
# Remote Logging using UDP # remote host is: name/ip:port, e.g. 192.168.0.1:514, port optional *.* @remote-host
保存文件。
重启
rsyslog服务>sudosystemctl restart rsyslog.service验证 syslog 转发是否正常工作
>logger "hello world"日志消息
hello world现在应该出现在中央 syslog 服务器上。
您现在已配置系统以远程日志记录到您的中央 syslog 服务器。对所有需要远程日志记录的系统重复此过程。
此基本设置不包括加密,仅适用于受信任的内部网络。强烈建议使用 TLS 加密,但需要证书基础设施。
在此配置中,来自远程主机的所有消息在中央 syslog 服务器上都以相同的方式处理。考虑按远程主机将消息过滤到单独的文件中,或按消息类别对其进行分类。
有关加密、过滤和其他高级主题的更多信息,请参阅 RSyslog 文档,网址为 https://www.rsyslog.com/doc/master/index.html#manual。
- 4 SystemTap—过滤和分析系统数据
SystemTap 提供命令行接口和脚本语言,用于详细检查运行中的 Linux 系统(特别是内核)的活动。SystemTap 脚本以 SystemTap 脚本语言编写,然后编译为 C 代码内核模块并插入到内核中…
- 5 内核探针
内核探针是一组用于收集 Linux 内核调试和性能信息的工具。开发人员和系统管理员使用它们来调试内核,或查找系统性能瓶颈。报告的数据然后可以用于调整系统以获得更好的性能。
- 6 使用 Perf 进行基于硬件的性能监控
Perf 是一个用于访问处理器性能监控单元 (PMU) 并记录和显示软件事件(如页面错误)的接口。它支持全系统、每个线程和 KVM 虚拟化客户机监控。
- 7 OProfile—全系统分析器
OProfile 是一个用于动态程序分析的分析器。它调查正在运行的程序的行为并收集信息。这些信息可以查看,并为进一步优化提供提示。
使用 OProfile 无需重新编译或使用包装库。甚至不需要内核补丁。在分析应用程序时,您可以期望有少量开销,具体取决于工作负载和采样频率。
- 8 动态调试—内核调试消息
动态调试是 Linux 内核中的一项强大的调试功能,它允许您在运行时启用和禁用调试消息,而无需重新编译内核或重新启动系统。
SystemTap 提供命令行接口和脚本语言,用于详细检查运行中的 Linux 系统(特别是内核)的活动。SystemTap 脚本以 SystemTap 脚本语言编写,然后编译为 C 代码内核模块并插入到内核中。脚本可以设计用于提取、过滤和汇总数据,从而诊断复杂的性能问题或功能问题。SystemTap 提供的信息类似于 netstat、ps、top 和 iostat 等工具的输出。但是,可以对收集到的信息使用更多的过滤和分析选项。
每次运行 SystemTap 脚本时,都会启动一个 SystemTap 会话。在允许脚本运行之前,会对其进行几次传递。然后,脚本被编译成内核模块并加载。如果脚本之前已执行过,并且没有系统组件发生变化(例如,不同的编译器或内核版本、库路径或脚本内容),SystemTap 不会再次编译脚本。相反,它使用存储在 SystemTap 缓存 (~/.systemtap) 中的 *.c 和 *.ko 数据。
当探针运行结束后,模块将被卸载。有关示例,请参阅第 4.2 节 “安装和设置”中的测试运行和相应的解释。
SystemTap 的使用基于 SystemTap 脚本 (*.stp)。它们告诉 SystemTap 收集哪种类型的信息,以及一旦收集到信息后该怎么做。脚本以 SystemTap 脚本语言编写,该语言类似于 AWK 和 C。有关语言定义,请参阅 https://sourceware.org/systemtap/langref/。许多有用的示例脚本可在 https://www.sourceware.org/systemtap/examples/ 获取。
SystemTap 脚本的基本思想是命名 events,并为它们提供 handlers。当 SystemTap 运行脚本时,它会监控某些事件。当事件发生时,Linux 内核会作为子例程运行处理程序,然后继续执行。因此,事件充当处理程序运行的触发器。处理程序可以记录指定数据并以特定方式打印。
SystemTap 语言只使用少量数据类型(整数、字符串和它们的关联数组)和完整的控制结构(块、条件、循环、函数)。它具有轻量级标点符号(分号是可选的),并且不需要详细声明(类型会自动推断和检查)。
有关 SystemTap 脚本及其语法的更多信息,请参阅第 4.3 节 “脚本语法”以及 systemtap-docs 软件包提供的 stapprobes 和 stapfuncs 手册页。
Tapsets 是预先编写的探测器和函数库,可在 SystemTap 脚本中使用。当用户运行 SystemTap 脚本时,SystemTap 会对照 tapset 库检查脚本的探测事件和处理程序。然后 SystemTap 会加载相应的探测器和函数,然后将脚本转换为 C。与 SystemTap 脚本本身一样,tapsets 使用文件扩展名 *.stp。
然而,与 SystemTap 脚本不同,tapsets 不用于直接执行。它们构成了其他脚本可以从中提取定义的库。因此,tapset 库是一个抽象层,旨在方便用户定义事件和函数。Tapsets 为用户可能希望指定为事件的函数提供别名。了解正确的别名通常比记住可能因内核版本而异的特定内核函数更容易。
与 SystemTap 相关的主要命令是 stap 和 staprun。要执行它们,您需要 root 权限,或者必须是 stapdev 或 stapusr 组的成员。
stapSystemTap 前端。运行 SystemTap 脚本(无论是来自文件还是来自标准输入)。它将脚本翻译成 C 代码,编译它,并将生成的内核模块加载到运行中的 Linux 内核中。然后,执行请求的系统跟踪或探测功能。
staprunSystemTap 后端。加载和卸载 SystemTap 前端生成的内核模块。
要获取每个命令的选项列表,请使用 --help。有关详细信息,请参阅 stap 和 staprun 手册页。
为了避免仅为使用 SystemTap 而向用户授予 root 访问权限,请使用以下 SystemTap 组之一。它们在 openSUSE Leap 上默认不可用,但您可以创建这些组并相应地修改访问权限。此外,如果安全影响适合您的环境,请调整 staprun 命令的权限。
stapdev此组的成员可以使用
stap运行 SystemTap 脚本,或使用staprun运行 SystemTap 检测模块。由于运行stap涉及将脚本编译成内核模块并加载到内核中,因此此组的成员仍然拥有有效的root访问权限。stapusr此组的成员只允许使用
staprun运行 SystemTap 检测模块。此外,他们只能从/lib/modules/KERNEL_VERSION/systemtap/运行这些模块。此目录必须由root拥有,并且只能由root用户写入。
以下列表概述了 SystemTap 的主要文件和目录。
/lib/modules/KERNEL_VERSION/systemtap/保存 SystemTap 检测模块。
/usr/share/systemtap/tapset/保存标准 tapset 库。
/usr/share/doc/packages/systemtap/examples保存各种用途的 SystemTap 示例脚本。仅当安装了
systemtap-docs软件包时才可用。~/.systemtap/cache缓存 SystemTap 文件的目录。
/tmp/stap*SystemTap 文件的临时目录,包括翻译后的 C 代码和内核对象。
由于 SystemTap 需要有关内核的信息,因此必须安装一些额外的内核相关软件包。对于您想要使用 SystemTap 探测的每个内核,您需要安装一组以下软件包。这组软件包应该与内核版本和类型(如下概述中用 * 表示)完全匹配。
重要:包含调试信息的软件包的存储库
如果你已订阅系统的在线更新,你可以在 openSUSE Leap 15.6 相关的 *-Debuginfo-Updates 在线安装存储库中找到“debuginfo”包。使用 YaST 启用存储库。
对于经典的 SystemTap 设置,安装以下软件包(使用 YaST 或 zypper)。
systemtapsystemtap-serversystemtap-docs(可选)kernel-*-basekernel-*-debuginfokernel-*-develkernel-source-*gcc
要访问手册页和有用的各种 SystemTap 示例脚本集合,请另外安装 systemtap-docs 软件包。
要检查机器上是否正确安装了所有软件包以及 SystemTap 是否可供使用,请以 root 身份执行以下命令。
# stap -v -e 'probe vfs.read {printf("read performed\n"); exit()}'它通过运行脚本探测当前使用的内核并返回输出。如果输出与以下内容相似,则 SystemTap 已成功部署并可供使用
Pass 1: parsed user script and 59 library script(s) in 80usr/0sys/214real ms. Pass 2: analyzed script: 1 probe(s), 11 function(s), 2 embed(s), 1 global(s) in 140usr/20sys/412real ms. Pass 3: translated to C into "/tmp/stapDwEk76/stap_1856e21ea1c246da85ad8c66b4338349_4970.c" in 160usr/0sys/408real ms. Pass 4: compiled C into "stap_1856e21ea1c246da85ad8c66b4338349_4970.ko" in 2030usr/360sys/10182real ms. Pass 5: starting run. read performed Pass 5: run completed in 10usr/20sys/257real ms.
对照 | |
检查脚本的组件。 | |
将脚本翻译成 C。运行系统 C 编译器从中创建内核模块。生成的 C 代码 ( | |
加载模块并通过挂接到内核来启用脚本中的所有探测器(事件和处理程序)。正在探测的事件是虚拟文件系统 (VFS) 读取。当事件在任何处理器上发生时,执行一个有效的处理程序(打印文本 | |
SystemTap 会话终止后,探测器将被禁用,并且内核模块将被卸载。 |
如果在测试过程中出现任何错误消息,请检查输出以获取有关任何缺失软件包的提示,并确保它们已正确安装。可能还需要重新启动并加载适当的内核。
SystemTap 脚本由以下两个组件组成
- SystemTap 事件(探测点)
命名内核事件,关联的处理程序应执行。事件示例包括进入或退出某个函数、计时器到期或启动或终止会话。
- SystemTap 处理程序(探测主体)
一系列脚本语言语句,用于指定每当某个事件发生时要完成的工作。这通常包括从事件上下文中提取数据、将它们存储到内部变量或打印结果。
一个事件及其对应的处理程序统称为 probe。SystemTap 事件也称为 probe points。探测的处理程序也称为 probe body。
注释可以以不同样式插入到 SystemTap 脚本的任何位置:使用 #、/* */ 或 // 作为标记。
一个 SystemTap 脚本可以有多个探测。它们必须以以下格式编写
probe EVENT {STATEMENTS}每个探测都有一个相应的语句块。此语句块必须用 { } 括起来,并包含要为每个事件执行的语句。
示例 4.1: 简单的 SystemTap 脚本 #
以下示例显示了一个简单的 SystemTap 脚本。
probe1 begin2 {3 printf4 ("hello world\n")5 exit ()6 }7
探测开始。 | |
事件 | |
处理程序定义开始,由 | |
处理程序中定义的第一个函数: | |
要由 | |
处理程序中定义的第二个函数: | |
处理程序定义结束,由 |
事件 begin 2(SystemTap 会话开始)触发 { } 中包含的处理程序。这里是 printf 函数 4。在这种情况下,它打印 hello world 后跟一个新行 5。然后,脚本退出。
如果您的语句块包含多个语句,SystemTap 将按顺序执行这些语句——您无需在多个语句之间插入特殊的分隔符或终止符。语句块也可以嵌套在其他语句块中。通常,SystemTap 脚本中的语句块使用与 C 编程语言相同的语法和语义。
SystemTap 支持多个内置事件。
通用事件语法是点符号序列。这允许将事件命名空间分解为多个部分。每个组件标识符都可以通过字符串或数字字面量进行参数化,其语法类似于函数调用。组件可以包含 * 字符,以扩展到其他匹配的探测点。探测点后面可以跟着 ? 字符,表示它是可选的,如果扩展失败则不应导致错误。或者,探测点后面可以跟着 ! 字符,表示它既可选又充分。
SystemTap 支持每个探测有多个事件——它们需要用逗号 (,) 分隔。如果在单个探测中指定了多个事件,SystemTap 将在任何指定事件发生时执行处理程序。
事件可分为以下几类
同步事件:当任何进程在内核代码中的特定位置执行指令时发生。这为其他事件提供了一个参考点(指令地址),从中可以获得更多上下文数据。
同步事件的一个例子是
vfs.FILE_OPERATION:进入虚拟文件系统 (VFS) 的 FILE_OPERATION 事件。例如,在第 4.2 节 “安装和设置”中,read是用于 VFS 的 FILE_OPERATION 事件。异步事件:不与代码中的特定指令或位置相关联。此探测点系列主要由计数器、计时器和类似构造组成。
异步事件的示例包括:
begin(SystemTap 会话开始时——当 SystemTap 脚本运行时)、end(SystemTap 会话结束时)或计时器事件。计时器事件指定一个定期执行的处理程序,例如example timer.s(SECONDS),或timer.ms(MILLISECONDS)。当与其他收集信息的探测器一起使用时,计时器事件允许您打印定期更新并查看信息如何随时间变化。
示例 4.2: 带计时器事件的探测 #
例如,以下探测器将每 4 秒打印一次文本“hello world”
probe timer.s(4)
{
printf("hello world\n")
}有关支持事件的详细信息,请参阅 stapprobes 手册页。手册页的另请参阅部分还包含指向讨论特定子系统和组件支持事件的其他手册页的链接。
每个 SystemTap 事件都伴随着为该事件定义的相应处理程序,由一个语句块组成。
如果您需要在多个探测中执行相同的语句集,则可以将它们放在函数中以便轻松重用。函数由关键字 function 后跟名称定义。它们接受任意数量的字符串或数字参数(按值),并可能返回单个字符串或数字。
function FUNCTION_NAME(ARGUMENTS) {STATEMENTS}
probe EVENT {FUNCTION_NAME(ARGUMENTS)}当 EVENT 的探测执行时,FUNCTION_NAME 中的语句将执行。ARGUMENTS 是传递给函数的可选值。
函数可以在脚本中的任何位置定义。它们可以接受任意数量的
在示例 4.1 “简单的 SystemTap 脚本”中已经介绍了经常需要的一个函数:用于格式化打印数据的 printf 函数。使用 printf 函数时,您可以使用格式字符串指定参数的打印方式。格式字符串包含在引号中,并且可以包含由 % 字符引入的更多格式说明符。
要使用哪种格式字符串取决于您的参数列表。格式字符串可以有多个格式说明符——每个说明符匹配一个相应的参数。多个参数可以用逗号分隔。
示例 4.3: 带格式说明符的 printf 函数 #
上面的示例将当前可执行名称 (execname()) 打印为字符串,将进程 ID (pid()) 打印为括号中的整数。然后,跟着一个空格、单词 open 和一个换行符
[...] vmware-guestd(2206) open held(2360) open [...]
除了在示例 4.3 “带格式说明符的 printf 函数”中使用的两个函数 execname() 和 pid() 之外,还可以将各种其他函数用作 printf 参数。
SystemTap 最常用的函数包括以下这些
- tid()
当前线程的 ID。
- pid()
当前线程的进程 ID。
- uid()
当前用户的 ID。
- cpu()
当前 CPU 编号。
- execname()
当前进程的名称。
- gettimeofday_s()
自 Unix 纪元(1970 年 1 月 1 日)以来的秒数。
- ctime()
将时间转换为字符串。
- pp()
描述当前正在处理的探测点的字符串。
- thread_indent()
用于组织打印结果的有用函数。它(内部)为每个线程 (
tid()) 存储一个缩进计数器。该函数接受一个参数,即缩进增量,指示要从线程的缩进计数器中添加或删除多少个空格。它返回一个字符串,其中包含一些通用跟踪数据以及适当数量的缩进空格。返回的通用数据包括时间戳(自线程初始缩进以来的微秒数)、进程名称和线程 ID 本身。这允许您识别调用了哪些函数、谁调用了它们以及它们花费了多长时间。调用入口和出口通常不会立即相互前置(否则很容易匹配它们)。在第一次调用入口和其出口之间,通常会进行其他调用入口和出口。缩进计数器通过缩进下一个函数调用来帮助您将入口与其对应的出口匹配,以防它不是上一个函数的出口。
有关支持的 SystemTap 函数的更多信息,请参阅 stapfuncs 手册页。
除了函数之外,您还可以在 SystemTap 处理程序中使用其他常见的构造,包括变量、条件语句(如 if/else、while 循环、for 循环、数组或命令行参数。
变量可以在脚本中的任何位置定义。要定义变量,只需选择一个名称并为其分配一个来自函数或表达式的值
foo = gettimeofday( )
然后您可以在表达式中使用该变量。SystemTap 会根据分配给变量的值的类型自动推断每个标识符的类型(字符串或数字)。任何不一致之处都将报告为错误。在上面的示例中,foo 将自动分类为数字,并且可以使用 printf() 通过整数格式说明符 (%d) 打印。
但是,默认情况下,变量是它们所包含的探测的局部变量。它们在每次处理程序调用时初始化、使用和处置。要在探测之间共享变量,请在脚本中的任何位置声明它们为全局变量。为此,请在探测外部使用 global 关键字
示例 4.4: 使用全局变量 #
global count_jiffies, count_ms
probe timer.jiffies(100) { count_jiffies ++ }
probe timer.ms(100) { count_ms ++ }
probe timer.ms(12345)
{
hz=(1000*count_jiffies) / count_ms
printf ("jiffies:ms ratio %d:%d => CONFIG_HZ=%d\n",
count_jiffies, count_ms, hz)
exit ()
}此示例脚本通过使用计时器计算 jiffies 和毫秒,然后相应地计算,来计算内核的 CONFIG_HZ 设置。(jiffy 是系统计时器中断一个时钟周期持续的时间。它不是一个绝对时间间隔单位,因为其持续时间取决于特定硬件平台的时钟中断频率)。使用 global 语句,可以在探测 timer.ms(12345) 中使用变量 count_jiffies 和 count_ms。使用 ++,变量的值会增加 1。
您可以在 SystemTap 脚本中使用多种条件语句。最常见的条件语句如下
- If/else 语句
它们以以下格式表示
if (CONDITION)1STATEMENT12 else3STATEMENT24
if语句将整数值表达式与零进行比较。如果条件表达式 1 非零,则执行第一个语句 2。如果条件表达式为零,则执行第二个语句 4。else 子句(3 和 4)是可选的。 2 和 4 都可以是语句块。- While 循环
它们以以下格式表示
while (CONDITION)1STATEMENT2
当
condition非零时,执行语句 2。 2 也可以是语句块。它必须改变一个值,以便condition最终为零。- For 循环
它们是
while循环的快捷方式,采用以下格式表示for (INITIALIZATION1; CONDITIONAL2; INCREMENT3) statement
1 中指定的表达式用于初始化循环迭代次数的计数器,并在循环开始执行前执行。循环的执行持续到循环条件 2 为假。(此表达式在每次循环迭代开始时检查)。3 中指定的表达式用于递增循环计数器。它在每次循环迭代结束时执行。
- 条件运算符
以下运算符可在条件语句中使用
==: 等于
!=: 不等于
>=: 大于或等于
<=: 小于或等于
如果您已安装 systemtap-docs 软件包,您可以在 /usr/share/doc/packages/systemtap/examples 中找到几个有用的 SystemTap 示例脚本。
本节将更详细地描述一个相当简单的示例脚本:/usr/share/doc/packages/systemtap/examples/network/tcp_connections.stp。
示例 4.5: 使用 tcp_connections.stp 监视传入的 TCP 连接 #
#! /usr/bin/env stap
probe begin {
printf("%6s %16s %6s %6s %16s\n",
"UID", "CMD", "PID", "PORT", "IP_SOURCE")
}
probe kernel.function("tcp_accept").return?,
kernel.function("inet_csk_accept").return? {
sock = $return
if (sock != 0)
printf("%6d %16s %6d %6d %16s\n", uid(), execname(), pid(),
inet_get_local_port(sock), inet_get_ip_source(sock))
}这个 SystemTap 脚本监视传入的 TCP 连接,并帮助实时识别未经授权或不需要的网络访问请求。它显示计算机接受的每个新传入 TCP 连接的以下信息
用户 ID (
UID)接受连接的命令 (
CMD)命令的进程 ID (
PID)连接使用的端口 (
PORT)TCP 连接源 IP 地址 (
IP_SOURCE)
要运行脚本,请执行
stap /usr/share/doc/packages/systemtap/examples/network/tcp_connections.stp
并跟随屏幕上的输出。要手动停止脚本,请按 Ctrl–C。
为了调试用户空间应用程序(如 DTrace 可以做到的),openSUSE Leap 15.6 支持使用 SystemTap 进行用户空间探测。可以在任何用户空间应用程序中插入自定义探测点。因此,SystemTap 允许您使用内核空间和用户空间探测来调试整个系统的行为。
要获取用户空间探测所需的 utrace 基础设施和 uprobes 内核模块,除了 第 4.2 节 “安装和设置” 中列出的软件包外,您还需要安装 kernel-trace 软件包。
utrace 实现了一个用于控制用户空间任务的框架。它提供了一个接口,可以被各种跟踪“引擎”使用,这些引擎以可加载的内核模块的形式实现。引擎为特定事件注册回调函数,然后附加到它们想要跟踪的线程。由于回调是从内核中的“安全”位置进行的,这使得函数可以进行各种处理。可以通过 utrace 监视多个事件。例如,您可以观察系统调用进入和退出、fork() 和发送到任务的信号等事件。有关 utrace 基础设施的更多详细信息,请访问 https://sourceware.org/systemtap/wiki/utrace。
SystemTap 支持探测用户空间进程中函数的进入和返回,探测用户空间代码中预定义的标记,以及监视用户进程事件。
要检查当前运行的内核是否提供所需的 utrace 支持,请使用以下命令
>sudogrep CONFIG_UTRACE /boot/config-`uname -r`
有关用户空间探测的更多详细信息,请参阅 https://sourceware.org/systemtap/SystemTap_Beginners_Guide/userspace-probing.html。
本章仅提供 SystemTap 的简要概述。有关 SystemTap 的更多信息,请参阅以下链接
- https://sourceware.org/systemtap/
SystemTap 项目主页。
- https://sourceware.org/systemtap/wiki/
大量有用的 SystemTap 信息集合,包括详细的用户和开发者文档,以及与其他工具的评论和比较,或常见问题和提示。还包含 SystemTap 脚本、示例和使用案例的集合,并列出了关于 SystemTap 的最新讲座和论文。
- https://sourceware.org/systemtap/documentation.html
提供 PDF 和 HTML 格式的SystemTap 教程、SystemTap 初学者指南、Tapset 开发者指南和SystemTap 语言参考。还列出了相关的手册页。
您还可以在已安装系统上的 /usr/share/doc/packages/systemtap 中找到 SystemTap 语言参考和 SystemTap 教程。示例 SystemTap 脚本可在 example 子目录中找到。
内核探针是一组用于收集 Linux 内核调试和性能信息的工具。开发人员和系统管理员使用它们来调试内核,或查找系统性能瓶颈。报告的数据然后可以用于调整系统以获得更好的性能。
您可以将这些探测插入任何内核例程中,并指定在特定断点命中后调用的处理程序。内核探测的主要优点是,在探测中进行更改后,您不再需要重新构建内核并重新启动系统。
要使用内核探测,您通常需要编写或获取一个特定的内核模块。此类模块包括 init 和 exit 函数。init 函数(例如 register_kprobe())注册一个或多个探测,而 exit 函数注销它们。注册函数定义了探测插入的位置以及探测命中后调用哪个处理程序。要一次注册或注销一组探测,您可以使用相关的 register_<PROBE_TYPE>probes() 或 unregister_<PROBE_TYPE>probes() 函数。
调试和状态消息通常通过 printk 内核例程报告。printk 是用户空间 printf 例程的内核空间等效项。有关 printk 的更多信息,请参阅 记录内核消息。通常,您可以通过检查 systemd 日志的输出来查看这些消息(请参阅 书籍“参考”,第 11 章 “journalctl:查询 systemd 日志”)。有关日志文件的更多信息,请参阅 第 3 章 “系统日志文件”。
内核探测在以下架构上完全实现
x86
AMD64/Intel 64
Arm
POWER
内核探测在以下架构上部分实现
IA64 (不支持指令
slot1上的探测)sparc64 (返回探测尚未实现)
内核探测有三种类型:Kprobes、Jprobes 和 Kretprobes。Kretprobes 有时称为返回探测。您可以在 Linux 内核中找到所有三种类型探测的源代码示例。请参阅目录 /usr/src/linux/samples/kprobes/ (软件包 kernel-source)。
Kprobes 可以附加到 Linux 内核中的任何指令。注册 Kprobes 时,它会在被探测指令的第一个字节处插入一个断点。当处理器命中此断点时,处理器寄存器被保存,处理传递给 Kprobes。首先,执行一个前处理程序,然后单步执行被探测指令,最后执行一个后处理程序。然后控制权传递给探测点后面的指令。
Jprobes 通过 Kprobes 机制实现。它插入到函数的入口点,并允许直接访问被探测函数的参数。其处理例程必须与被探测函数具有相同的参数列表和返回值。要结束它,请调用 jprobe_return() 函数。
当命中 jprobe 时,处理器寄存器被保存,指令指针被指向 jprobe 处理例程。然后控制权以与被探测函数相同的寄存器内容传递给处理程序。最后,处理程序调用 jprobe_return() 函数,并将控制权切换回控制函数。
通常,您可以在一个函数上插入多个探测。然而,Jprobe 限制为每个函数只能有一个实例。
Kprobes 的编程接口由用于注册和注销所有使用的内核探测以及相关探测处理程序的函数组成。有关这些函数及其参数的更详细描述,请参阅 第 5.5 节 “更多信息” 中的信息源。
register_kprobe()在指定地址插入一个断点。当命中断点时,调用
pre_handler和post_handler。register_jprobe()在指定地址插入一个断点。该地址需要是被探测函数第一个指令的地址。当命中断点时,运行指定的处理程序。处理程序应该具有与被探测函数相同的参数列表和返回类型。
register_kretprobe()为指定的函数插入一个返回探测。当被探测函数返回时,运行指定的处理程序。此函数成功返回 0,失败返回负错误号。
unregister_kprobe()、unregister_jprobe()、unregister_kretprobe()移除指定的探测。您可以在探测注册后的任何时候使用它。
register_kprobes()、register_jprobes()、register_kretprobes()插入指定数组中的每个探测。
unregister_kprobes()、unregister_jprobes()、unregister_kretprobes()移除指定数组中的每个探测。
disable_kprobe()、disable_jprobe()、disable_kretprobe()暂时禁用指定的探测。
enable_kprobe()、enable_jprobe()、enable_kretprobe()暂时启用已禁用的探测。
在最新的 Linux 内核中,Kprobes 检测使用内核的 debugfs 接口。它可以列出所有已注册的探测并全局开启或关闭所有探测。
所有当前注册的探测列表在 /sys/kernel/debug/kprobes/list 文件中。
saturn.example.com:~ # cat /sys/kernel/debug/kprobes/list c015d71a k vfs_read+0x0 [DISABLED] c011a316 j do_fork+0x0 c03dedc5 r tcp_v4_rcv+0x0
第一列列出探测插入的内核地址。第二列打印探测的类型:k 代表 kprobe,j 代表 jprobe,r 代表返回探测。第三列指定探测的符号、偏移量和可选模块名称。接下来的可选列包括探测的状态信息。如果探测插入的虚拟地址不再有效,则用 [GONE] 标记。如果探测暂时禁用,则用 [DISABLED] 标记。
要了解有关内核探测的更多信息,请查看以下信息来源
有关内核探测的详细但技术性更强的信息可在
/usr/src/linux/Documentation/trace/kprobes.txt(软件包kernel-source) 中找到。所有三种类型探测的示例(以及相关的
Makefile)在/usr/src/linux/samples/kprobes/目录中(软件包kernel-source)。有关 Linux 内核模块和
printk内核例程的深入信息可在 The Linux Kernel Module Programming Guide 找到。
您可以将结果信息存储在报告中。此报告包含有关指令指针或线程正在执行的代码等信息。
Perf 由两部分组成
集成到 Linux 内核中,用于指示硬件的代码。
perf用户空间实用程序,允许您使用内核代码并帮助您分析收集到的数据。
性能监控意味着收集与应用程序或系统性能相关的信息。这些信息可以通过基于软件的方式或从 CPU 或芯片组获取。Perf 集成了这两种方法。
许多现代处理器包含一个性能监控单元 (PMU)。PMU 的设计和功能是 CPU 特定的。例如,寄存器、计数器和支持的功能数量因 CPU 实现而异。
每个 PMU 模型都包含一组寄存器:性能监控配置 (PMC) 和性能监控数据 (PMD)。两者都可以读取,但只有 PMC 是可写的。这些寄存器存储配置信息和数据。
Perf 支持几种分析模式
计数。 统计事件发生的次数。
基于事件的采样。 一种不太精确的计数方法:每当达到一定数量的事件时,就会记录一个样本。
基于时间的采样。 一种不太精确的计数方法:以定义的频率记录样本。
基于指令的采样(仅限 AMD64)。 处理器跟踪给定间隔内出现的指令,并采样它们产生的事件。这允许跟踪单个指令,并查看其中哪些对性能至关重要。
为了收集所需信息,perf 工具包含多个子命令。本节概述了最常用的命令。
要以手册页的形式查看任何子命令的帮助,请使用 perf helpSUBCOMMAND 或 man perf-SUBCOMMAND。
perf stat启动一个程序并创建一个统计概述,该概述在程序退出后显示。
perf stat用于计数事件。perf record启动一个程序并创建一个包含性能计数器信息的报告。报告以
perf.data存储在当前目录中。perf record用于采样事件。perf report显示先前使用
perf record创建的报告。perf annotate显示报告文件和执行代码的注释版本。如果安装了调试符号,还会显示源代码。
perf list列出 Perf 可以使用当前内核和您的 CPU 报告的事件类型。您可以按类别筛选事件类型。例如,要仅查看硬件事件,请使用
perf list hw。perf_event_open的手册页包含最重要事件的简短描述。例如,要查找事件branch-misses的描述,请搜索BRANCH_MISSES(注意拼写差异)。>manperf_event_open |grep-A5 BRANCH_MISSES有时,事件可能模棱两可。小写硬件事件名称不是原始硬件事件的名称,而是 Perf 创建的别名名称。这些别名映射到每个支持的处理器上命名不同但定义相似的硬件事件。
例如,
cpu-cycles事件在 Intel 处理器上映射到硬件事件UNHALTED_CORE_CYCLES。然而,在 AMD 处理器上,它映射到硬件事件CPU_CLK_UNHALTED。Perf 还允许测量特定于您硬件的原始事件。要查找它们的描述,请参阅您的 CPU 供应商的架构软件开发人员手册。有关 AMD64/Intel 64 处理器的相关文档已链接在 第 6.7 节 “更多信息” 中。
perf top显示系统活动发生时的情况。
perf trace此命令的行为类似于
strace。通过此子命令,您可以查看特定线程或进程执行了哪些系统调用以及它接收了哪些信号。
要统计事件的发生次数,例如 perf list 显示的事件,请使用
#perfstat -e EVENT -a
要同时计数多种类型的事件,请用逗号分隔它们。例如,要计数 cpu-cycles 和 instructions,请使用
#perfstat -e cpu-cycles,instructions -a
要停止会话,请按 Ctrl–C。
您还可以统计特定时间内的事件发生次数
#perfstat -e EVENT -a -- sleep TIME
将 TIME 替换为秒数。
有几种方法可以对特定命令的事件进行采样
要为新调用的命令创建报告,请使用
#perfrecord COMMAND然后,正常使用已启动的进程。当您退出进程时,Perf 会话也会停止。
要在新调用的命令运行时为整个系统创建报告,请使用
#perfrecord -a COMMAND然后,正常使用已启动的进程。当您退出进程时,Perf 会话也会停止。
要为已运行的进程创建报告,请使用
#perfrecord -p PID将 PID 替换为进程 ID。要停止会话,请按 Ctrl–C。
现在您可以使用以下命令查看收集到的数据 (perf.data)
>perfreport
这会打开一个伪图形界面。要获取帮助,请按 H。要退出,请按 Q。
如果您喜欢图形界面,请尝试 Perf 的 GTK+ 界面
>perfreport --gtk
然而,GTK+ 界面功能有限。
本章仅提供简要概述。有关更多信息,请参阅以下链接
- https://perf.wiki.kernel.org/index.php/Main_Page
项目主页。它还提供了一个关于使用
perf的教程。- https://www.brendangregg.com/perf.html
非官方页面,包含许多关于如何使用
perf的单行示例。- https://web.eece.maine.edu/~vweaver/projects/perf_events/
非官方页面,包含多个资源,主要与 Perf 的 Linux 内核代码及其 API 相关。此页面例如包含 CPU 兼容性表和编程指南。
- https://www-ssl.intel.com/content/dam/www/public/us/en/documents/manuals/64-ia-32-architectures-software-developer-vol-3b-part-2-manual.pdf
Intel 架构软件开发人员手册,第 3B 卷。
- https://support.amd.com/TechDocs/24593.pdf
AMD 架构程序员手册,第 2 卷。
- 第 7 章 “OProfile—系统范围的分析器”
有关其他性能优化,请查阅本章。
OProfile 由一个内核驱动程序和一个用于收集数据的守护程序组成。它使用许多处理器上提供的硬件性能计数器。OProfile 能够分析所有代码,包括内核、内核模块、内核中断处理程序、系统共享库和其他应用程序。
现代处理器通过硬件的性能计数器支持分析。根据处理器,可以有许多计数器,每个计数器都可以编程一个事件来计数。每个计数器都有一个值,该值决定了采样的频率。值越低,使用频率越高。
在后处理步骤中,收集所有信息并将指令地址映射到函数名。
要使用 OProfile,请安装 oprofile 软件包。
安装要分析的相应应用程序的 *-debuginfo 软件包会很有用。要分析内核,您还需要 debuginfo 软件包。
OProfile 包含几个实用程序来处理分析过程及其分析数据。以下列表是本章中使用的程序的简短摘要
opannotate输出包含分析信息的带注释的源代码或汇编列表。带注释的报告可以与
addr2line结合使用,以识别潜在热点存在的源文件和行。有关详细信息,请参阅man addr2line。operf分析器工具。分析停止后,默认存储在
CUR_DIR/oprofile_data/samples/current中的数据可以由opreport处理,例如。ophelp列出可用事件及简短描述。
opimport将样本数据库文件从外部二进制格式转换为平台特定格式。
opreport从分析数据生成报告。
使用 OProfile,您可以同时分析内核和应用程序。分析内核时,告诉 OProfile 在哪里找到 vmlinuz* 文件。使用 --vmlinux 选项并将其指向 vmlinuz*(通常可在 /boot 中找到)。如果您需要分析内核模块,OProfile 默认会这样做。但是,请务必阅读 https://oprofile.sourceforge.net/doc/kernel-profiling.html。
大多数应用程序不需要分析内核,因此您应该使用 --no-vmlinux 选项来减少信息量。
启动守护进程、收集数据、停止守护进程并为应用程序 COMMAND 创建报告。
打开 shell 并以
root用户身份登录。决定是否带或不带 Linux 内核进行分析
使用 Linux 内核进行分析。 执行以下命令,因为
operf只能处理未压缩的映像>cp /boot/vmlinux-`uname -r`.gz /tmp>gunzip /tmp/vmlinux*.gz>operf--vmlinux=/tmp/vmlinux* COMMAND不使用 Linux 内核进行分析。 使用以下命令
#operf --no-vmlinux COMMAND要在输出中查看哪些函数调用了其他函数,请额外使用
--callgraph选项并设置最大 DEPTH#operf --no-vmlinux --callgraph DEPTH COMMAND
operf将其数据写入CUR_DIR/oprofile_data/samples/current。operf命令完成后(或通过 Ctrl–C 中止),可以使用oreport分析数据#opreport Overflow stats not available CPU: CPU with timer interrupt, speed 0 MHz (estimated) Profiling through timer interrupt TIMER:0| samples| %| ------------------ 84877 98.3226 no-vmlinux ...
事件配置的一般过程如下
首先使用事件
CPU-CLK_UNHALTED和INST_RETIRED来寻找优化机会。使用特定事件来查找瓶颈。要列出它们,请使用命令
perf list。
如果您需要分析某些事件,请首先使用 ophelp 命令检查处理器支持的可用事件(来自 Intel Core i5 CPU 生成的示例输出)
#ophelpoprofile: available events for CPU type "Intel Architectural Perfmon" See Intel 64 and IA-32 Architectures Software Developer's Manual Volume 3B (Document 253669) Chapter 18 for architectural perfmon events This is a limited set of fallback events because oprofile does not know your CPU CPU_CLK_UNHALTED: (counter: all)) Clock cycles when not halted (min count: 6000) INST_RETIRED: (counter: all)) number of instructions retired (min count: 6000) LLC_MISSES: (counter: all)) Last level cache demand requests from this core that missed the LLC (min count: 6000) Unit masks (default 0x41) ---------- 0x41: No unit mask LLC_REFS: (counter: all)) Last level cache demand requests from this core (min count: 6000) Unit masks (default 0x4f) ---------- 0x4f: No unit mask BR_MISS_PRED_RETIRED: (counter: all)) number of mispredicted branches retired (precise) (min count: 500)
使用选项 --event 指定性能计数器事件。可以有多个选项。此选项需要一个事件名称(来自 ophelp)和一个采样率,例如
# operf --events CPU_CLK_UNHALTED:100000警告:使用 CPU_CLK_UNHALTED 设置采样率
设置低的采样率会严重影响系统性能,而高的采样率会严重干扰系统,导致数据无用。建议在带和不带 OProfile 的情况下调整要监控的性能指标,并通过实验确定对性能干扰最小的最低采样率。
生成报告之前,请确保 operf 已停止。除非您提供了带有 --session-dir 的输出目录,否则 operf 已将其数据写入 CUR_DIR/oprofile_data/samples/current,并且报告工具 opreport 和 opannotate 默认会在此处查找。
不带任何选项调用 opreport 会提供完整的摘要。如果将可执行文件作为参数,则仅从该可执行文件中检索配置文件数据。如果您分析用 C++ 编写的应用程序,请使用 --demangle smart 选项。
opannotate 生成带有源代码注释的输出。使用以下选项运行它
#opannotate--source \ --base-dirs=BASEDIR \ --search-dirs=SEARCHDIR \ --output-dir=annotated/ \ /lib/libfoo.so
选项 --base-dir 包含一个以逗号分隔的路径列表,这些路径将从调试源文件中剥离。在查找 --search-dirs 之前会搜索这些路径。--search-dirs 选项也是一个以逗号分隔的目录列表,用于搜索源文件。
注意:注释源代码中的不准确之处
由于编译器优化,代码可能会消失并出现在不同的位置。请参阅 https://oprofile.sourceforge.net/doc/debug-info.html 中的信息,以充分理解其含义。
本章仅提供简要概述。有关更多信息,请参阅以下链接
- https://oprofile.sourceforge.net
项目主页。
- 手册页
不同工具选项的详细描述。
/usr/share/doc/packages/oprofile/oprofile.html包含 OProfile 手册。
- https://developer.intel.com/
Intel 处理器架构参考。
您可以在以下几种情况下使用动态调试,例如
故障排除内核问题
开发新硬件的驱动程序
跟踪和审计安全事件
以下列出了动态调试的某些优点
- 实时调试
动态调试无需系统重启即可启用调试消息。这种实时功能对于诊断生产环境中的问题至关重要。
- 选择性调试
您可以为内核的特定部分甚至单个模块启用调试消息,从而让您专注于相关信息。
- 性能调优
使用动态调试通过根据当前分析要求选择性启用或禁用调试消息来监视和优化内核性能。
对于默认安装的受支持内核版本,动态调试已内置。要检查动态调试的状态,请以 root 用户身份运行以下命令
#zcat /proc/config.gz | grep CONFIG_DYNAMIC_DEBUG
如果动态调试已编译到内核中,您应该看到类似于以下内容的输出
CONFIG_DYNAMIC_DEBUG=y CONFIG_DYNAMIC_DEBUG_CORE=y
要在运行中的内核中启用特定的调试消息或日志,您可以使用 echo 命令并写入 /sys/kernel/debug/dynamic_debug/control 文件。
以下示例说明了动态调试的某些简单用法
注意
动态调试依赖于嵌入在内核代码中的特定调试宏,例如 pr_debug。内核开发人员使用这些宏将调试消息插入到代码中。
本节中的示例假定 pr_debug 宏正常工作,因为动态调试已为正在运行的内核启用。
- 为特定内核源代码文件启用调试消息
要为特定内核源代码文件启用调试消息,请使用以下示例
#echo "file FILE_NAME.c +p" > /sys/kernel/debug/dynamic_debug/control- 为特定内核模块启用调试消息
要为特定内核模块启用调试消息,请使用以下示例
#echo "module MODULE_NAME +p" > /sys/kernel/debug/dynamic_debug/control- 禁用调试消息
要禁用先前为特定内核源代码文件或内核模块启用的调试消息,请运行带
-p选项的echo命令。例如#echo "file FILE_NAME.c -p" > /sys/kernel/debug/dynamic_debug/control#echo "module MODULE_NAME -p" > /sys/kernel/debug/dynamic_debug/control
有关动态调试及其用例的详细信息,请参阅其官方文档。
- 9 通用系统资源管理
调优系统不仅仅是优化内核或充分利用您的应用程序,它始于建立一个精简且快速的系统。您设置分区和文件系统的方式会影响服务器的速度。活动服务的数量以及常规任务的调度方式也会影响性能。
- 10 内核控制组
Kernel Control Groups(“cgroups”)是内核特性,用于分配和限制进程的硬件和系统资源。进程也可以组织成层次树结构。
- 11 自动非统一内存访问 (NUMA) 平衡
当需要许多 CPU 和大量内存时,硬件存在物理限制。本章中,重要的限制在于 CPU 和内存之间的通信带宽有限。为了解决这个问题,引入了一种架构修改,即非统一内存访问 (NUMA)。
在此配置中,存在多个节点。每个节点包含所有 CPU 和内存的一个子集。访问主内存的速度取决于内存相对于 CPU 的位置。工作负载的性能取决于应用程序线程访问与线程正在执行的 CPU 位于同一节点上的数据。自动 NUMA 平衡会按需将数据迁移到与访问该数据的 CPU 位于同一节点的内存节点。根据工作负载,在使用 NUMA 硬件时,这可以显著提高性能。
- 12 电源管理
电源管理旨在降低能源和冷却系统的运营成本,同时保持系统性能达到满足当前需求的水平。因此,电源管理始终需要在实际性能需求和系统的节能选项之间取得平衡。电源管理可以在系统的不同层级实现和使用。高级配置和电源接口 (ACPI) 定义了一组用于设备电源管理功能的规范以及操作系统与其接口。由于服务器环境中的节能主要可以在处理器级别实现,因此本章介绍主要概念并突出显示一些用于分析和影响相关参数的工具。
精心规划的安装可确保系统完全按照您所需的目的进行设置。它还可以节省大量系统微调时间。本节中建议的所有更改都可以在安装过程中的步骤中进行。有关详细信息,请参阅书籍“启动”,第 3 章 “安装步骤”,第 3.11 节 “安装设置”。
根据服务器的应用范围和硬件布局,分区方案可能会影响机器的性能(尽管程度较小)。本手册超出此范围,无法为特定工作负载建议不同的分区方案。但是,以下规则对性能有积极影响。它们不适用于使用外部存储系统的情况。
确保磁盘上始终有一定量的可用空间,因为磁盘已满会降低性能。
通过以下方式将同时的读写访问分散到不同的磁盘上,例如
为操作系统、数据和日志文件使用独立的磁盘
将邮件服务器的后台处理目录放在独立的磁盘上
将家用服务器的用户目录分布在不同的磁盘之间
安装范围对机器的性能没有直接影响,但精心选择的软件包范围具有优势。建议安装运行服务器所需的最小软件包。具有最小软件包集的系统更易于维护,并且潜在的安全问题更少。此外,定制的安装范围还可确保默认情况下不会启动不必要的服务。
openSUSE Leap 允许您在“安装摘要”屏幕上自定义安装范围。默认情况下,您可以选择或移除针对特定任务的预配置模式,但也可以启动 YaST 软件管理器进行细粒度的基于软件包的选择。
并非所有情况下都需要以下一个或多个默认模式
服务器很少需要完整的桌面环境。如果需要图形环境,更经济的解决方案(例如 IceWM)可能就足够了。
如果仅通过命令行管理服务器及其应用程序,请考虑不安装此模式。但是,请记住,远程运行 GUI 应用程序需要它。如果您的应用程序由 GUI 管理,或者您更喜欢 YaST 的 GUI 版本,请保留此模式。
此模式仅用于从机器打印。
默认安装会启动多个服务(数量因安装范围而异)。由于每个服务都会消耗资源,因此建议禁用不需要的服务。运行 › › 以启动服务管理模块。
如果您正在使用 YaST 的图形版本,您可以单击列标题对服务列表进行排序。使用此功能可以概览当前正在运行的服务。使用按钮禁用当前会话的服务。要永久禁用它,请使用按钮。
以下列表显示了安装 openSUSE Leap 后默认启动的服务。检查您需要哪些组件,并禁用其他组件
加载高级 Linux 声音系统。
审计系统的守护进程(有关详细信息,请参阅书籍“安全和强化指南”)。如果您不使用审计,请禁用此项。
处理蓝牙加密狗的冷插拔。
打印机守护程序。
启用
*.class或*.jarJava 程序的执行。挂载 NFS 所需的服务。
从 Windows* 服务器挂载 SMB/CIFS 文件系统所需的服务。
启动时显示启动画面。
硬盘是计算机系统中最慢的组件,因此通常是瓶颈的原因。使用最适合您工作负载的文件系统有助于提高性能。使用特殊的挂载选项或优先处理进程的 I/O 优先级是加快系统速度的进一步手段。
openSUSE Leap 附带了多种文件系统,包括 Btrfs、Ext4、Ext3、Ext2 和 XFS。每种文件系统都有其自身的优缺点。
NFS (版本 3) 调优在 NFS Howto 中有详细介绍:https://nfs.sourceforge.net/nfs-howto/。挂载 NFS 共享时,首先尝试将读写块大小增加到 32768,使用挂载选项 wsize 和 rsize。
文件系统中的每个文件和目录都关联着三个时间戳:文件上次读取的时间称为访问时间,文件数据上次修改的时间称为修改时间,文件元数据上次修改的时间称为更改时间。始终保持访问时间最新会带来显著的性能开销,因为每次只读访问都会导致写入操作。默认情况下,每个文件系统仅在当前文件访问时间早于一天,或早于文件修改或更改时间时更新访问时间。此功能称为相对访问时间,相应的挂载选项是 relatime。可以使用 noatime 挂载选项禁用访问时间的更新。但是,您需要验证您的应用程序不使用它。这可能适用于文件和 Web 服务器或网络存储。如果默认的相对访问时间更新策略不适合您的应用程序,请使用 strictatime 挂载选项。
某些文件系统(例如 Ext4)还支持延迟时间戳更新。当使用 lazytime 挂载选项启用此功能时,所有时间戳的更新都在内存中进行,但它们不写入磁盘。只有在响应 fsync 或 sync 系统调用时,当由于文件大小更新等其他原因而写入文件信息时,当时间戳早于 24 小时时,或者当需要从内存中逐出缓存的文件信息时,才会发生这种情况。
要更新文件系统使用的挂载选项,可以直接编辑 /etc/fstab,或者在 YaST 分区工具中编辑或添加分区时使用对话框。
ionice 命令允许您优先处理单个进程的磁盘访问。这使您能够为非时间敏感的后台进程(如备份作业)分配较低的 I/O 优先级,这些进程具有大量磁盘访问。ionice 还允许您提高特定进程的 I/O 优先级,以确保该进程始终立即访问磁盘。此功能的缺点是标准写入会缓存在页面缓存中,并且仅在稍后由独立的内核进程写回持久存储。因此,I/O 优先级设置通常不适用于这些写入。另请注意,I/O 类和优先级设置仅由 blk-mq I/O 路径的 BFQ I/O 调度程序遵守(请参阅 第 13.2 节 “blk-mq I/O 路径的可用 I/O 调度器”)。您可以设置以下三种调度类
- 空闲
空闲调度类中的进程仅在没有其他进程请求磁盘 I/O 时才获得磁盘访问权限。
- 尽力而为
用于任何未请求特定 I/O 优先级的进程的默认调度类。此类别中的优先级可以调整到
0到7级别(0是最高优先级)。以相同尽力而为优先级运行的程序以轮询方式提供服务。某些内核版本对尽力而为类别中的优先级处理方式不同——有关详细信息,请参阅ionice(1)手册页。- 实时
此类中的进程始终首先获得磁盘访问权限。将优先级级别从
0到7精细调整(0为最高优先级)。请谨慎使用,因为它可能导致其他进程饥饿。
有关详细信息和确切的命令语法,请参阅 ionice(1) 手册页。如果您需要更可靠地控制每个应用程序可用的带宽,请使用内核控制组,如 第 10 章 “内核控制组” 中所述。
每个进程都分配一个且只有一个管理 cgroup。cgroup 以分层树结构排序。您可以为单个进程或整个层次结构树分支设置资源限制,例如 CPU、内存、磁盘 I/O 或网络带宽使用。
在 openSUSE Leap 上,systemd 使用 cgroup 将所有进程组织成组,systemd 将其称为 slice。systemd 还提供了一个用于设置 cgroup 属性的接口。
命令 systemd-cgls 显示层级树。
内核 cgroup API 有两种变体——v1 和 v2。此外,可以有多个公开不同 API 的 cgroup 层级。在许多可能的组合中,有两种实际选择
统一:带控制器的 v2 层级
混合:不带控制器的 v2 层级,控制器在 v1 层级上(已弃用)
默认模式是统一。有一种混合模式,为需要它的应用程序提供向后兼容性。
您只能设置一种模式。
将进程组织到不同的 cgroup 中可用于获取每个 cgroup 的资源消耗数据。
记账的开销相对较小但非零,其影响取决于工作负载。为一个单元激活记账也会隐式地为同一切片中的所有单元、所有其父切片以及其中包含的单元激活记账。
记账可以在每个单元的基础上使用 MemoryAccounting= 等指令设置,也可以在 /etc/systemd/system.conf 中使用 DefaultMemoryAccounting= 指令全局设置。有关可能指令的详尽列表,请参阅 man systemd.resource-control。
注意:隐式资源消耗
请注意,资源消耗隐式地取决于工作负载执行的环境(例如,库/内核中数据结构的大小、实用程序的 fork 行为、计算效率)。因此,建议在环境变化时(重新)校准您的限制。
cgroup 的限制可以使用 systemctl set-property 命令设置。语法为
#systemctl set-property [--runtime] NAME PROPERTY1=VALUE [PROPERTY2=VALUE]
配置的值会立即应用。可选地,使用 --runtime 选项,这样新值在重启后不会持久存在。
将 NAME 替换为 systemd 服务、范围或切片名称。
有关属性的完整列表和更多详细信息,请参阅 man systemd.resource-control。
systemd 支持为每个单独的叶单元配置任务计数限制,或在切片上进行聚合。上游 systemd 附带的默认设置限制了每个单元的任务数(内核全局限制的 15%,运行 /usr/sbin/sysctl kernel.pid_max 查看总限制)。每个用户切片限制为内核限制的 33%。然而,这在 openSUSE Leap 中有所不同。
在实践中,发现没有适用于所有用例的单一默认值。openSUSE Leap 附带了两个自定义配置,它们覆盖了系统单元和用户切片的上游默认值,并将它们都设置为 infinity。/usr/lib/systemd/system.conf.d/__20-defaults-SUSE.conf 包含以下行
[Manager] DefaultTasksMax=infinity
/usr/lib/systemd/system/user-.slice.d/10-defaults.conf 包含以下行
[Slice] TasksMax=infinity
使用 systemctl 验证 DefaultTasksMax 值
>systemctl show --property DefaultTasksMaxDefaultTasksMax=infinity
infinity 意味着没有限制。更改默认值并非必需,但设置某些限制可能有助于防止失控进程导致的系统崩溃。
通过创建新的覆盖文件 /etc/systemd/system.conf.d/90-system-tasksmax.conf 来更改全局 DefaultTasksMax 值,并写入以下行以将每个系统单元的新默认限制设置为 256 个任务
[Manager] DefaultTasksMax=256
加载新设置,然后验证它是否已更改
>sudosystemctl daemon-reload>systemctl show --property DefaultTasksMaxDefaultTasksMax=256
根据您的需求调整此默认值。您可以根据需要为单个服务设置不同的限制。此示例适用于 MariaDB。首先检查当前活动值
>systemctl status mariadb.service● mariadb.service - MariaDB database server Loaded: loaded (/usr/lib/systemd/system/mariadb.service; disabled; vendor preset> Active: active (running) since Tue 2020-05-26 14:15:03 PDT; 27min ago Docs: man:mysqld(8) https://mariadb.com/kb/en/library/systemd/ Main PID: 11845 (mysqld) Status: "Taking your SQL requests now..." Tasks: 30 (limit: 256) CGroup: /system.slice/mariadb.service └─11845 /usr/sbin/mysqld --defaults-file=/etc/my.cnf --user=mysql
“Tasks”行显示 MariaDB 当前运行 30 个任务,上限为默认的 256,这对于数据库来说是不够的。以下示例演示如何将 MariaDB 的限制提高到 8192。
>sudosystemctl set-property mariadb.service TasksMax=8192>systemctl status mariadb.service● mariadb.service - MariaDB database server Loaded: loaded (/usr/lib/systemd/system/mariadb.service; disabled; vendor preset: disab> Drop-In: /etc/systemd/system/mariadb.service.d └─50-TasksMax.conf Active: active (running) since Tue 2020-06-02 17:57:48 PDT; 7min ago Docs: man:mysqld(8) https://mariadb.com/kb/en/library/systemd/ Process: 3446 ExecStartPre=/usr/lib/mysql/mysql-systemd-helper upgrade (code=exited, sta> Process: 3440 ExecStartPre=/usr/lib/mysql/mysql-systemd-helper install (code=exited, sta> Main PID: 3452 (mysqld) Status: "Taking your SQL requests now..." Tasks: 30 (limit: 8192) CGroup: /system.slice/mariadb.service └─3452 /usr/sbin/mysqld --defaults-file=/etc/my.cnf --user=mysql
systemctl set-property 应用新限制并创建一个临时文件以持久化,即 /etc/systemd/system/mariadb.service.d/50-TasksMax.conf,该文件仅包含您要应用于现有单元文件的更改。该值不必是 8192,而应是适合您的工作负载的任何限制。
用户的默认限制应较高,因为用户会话需要更多资源。通过创建新文件(例如 /etc/systemd/system/user-.slice.d/40-user-taskmask.conf)为任何用户设置您自己的默认值。以下示例将默认值设置为 16284
[Slice] TasksMax=16284
注意:数字前缀参考
请参阅 《参考》一书,第 10 章“systemd 守护程序”,第 10.5.3 节“手动创建临时文件”,以了解临时文件预期使用的数字前缀。
然后重新加载 systemd 以加载新值,并验证更改
>sudosystemctl daemon-reload>systemctl show --property TasksMax user-1000.sliceTasksMax=16284
您如何知道要使用哪些值?这取决于您的工作负载、系统资源和其他资源配置。当您的 TasksMax 值过低时,您可能会看到错误消息,例如 Failed to fork (Resources temporarily unavailable)、Can't create thread to handle new connection 和 Error: Function call 'fork' failed with error code 11, 'Resource temporarily unavailable'。
有关在 systemd 中配置系统资源的更多信息,请参阅 systemd.resource-control (5)。
本节介绍如何使用 Linux 内核的块 I/O 控制器来优先处理或限制 I/O 操作。这利用了 systemd 提供的配置 cgroup 的方法,并讨论了处理比例 I/O 控制时可能遇到的陷阱。
以下小节描述了您在设计和配置系统时必须提前采取的步骤,因为这些方面无法在运行时更改。
您应该使用支持 cgroup 回写的的文件系统(否则无法进行回写计费)。推荐的 openSUSE Leap 文件系统在以下上游版本中添加了支持
Btrfs (v4.3)
Ext4 (v4.3)
XFS (v5.3)
截至 openSUSE Leap 15.3,可以使用任何指定的文件系统。
限制策略在堆栈的更高层实现,因此不需要任何额外的调整。比例 I/O 控制策略有两种不同的实现:BFQ 控制器和基于成本的模型。我们在此描述 BFQ 控制器。要对特定设备施加其比例实现,我们必须确保 BFQ 是选择的调度程序。检查当前调度程序
>cat /sys/class/block/sda/queue/schedulermq-deadline kyber bfq [none]
将调度程序切换到 BFQ
#echo bfq > /sys/class/block/sda/queue/scheduler
您必须指定磁盘设备(而不是分区)。设置此属性的最佳方法是针对设备的 udev 规则。openSUSE Leap 附带的 udev 规则已经为旋转磁盘驱动器启用了 BFQ。
您可以将值永久应用于(长期运行的)服务。
>sudosystemctl set-property fast.service IOWeight=400>sudosystemctl set-property slow.service IOWeight=50>sudosystemctl set-property throttled.service IOReadBandwidthMax="/dev/sda 1M"
或者,您可以将 I/O 控制应用于单个命令,例如
>sudosystemd-run --scope -p IOWeight=400 high_prioritized_command>sudosystemd-run --scope -p IOWeight=50 low_prioritized_command>sudosystemd-run --scope -p IOReadBandwidthMax="/dev/sda 1M" dd if=/dev/sda of=/dev/null bs=1M count=10
以下列表项描述了 I/O 控制行为,以及您在不同条件下应该期待什么。
I/O 控制对于直接 I/O 操作(绕过页面缓存)效果最佳,实际 I/O 与调用者分离的情况(通常是通过页面缓存回写)可能会有不同的表现。例如,延迟的 I/O 控制,甚至没有观察到 I/O 控制(考虑小突发或竞争工作负载恰好从不 “相遇,” 同时提交 I/O 并饱和带宽)。由于这些原因,I/O 吞吐量的最终比率不严格遵循配置权重的比率。
systemd 执行配置权重的缩放(以适应更窄的 BFQ 权重范围),因此产生的吞吐量比率也不同。
回写活动取决于脏页的数量,以及全局 sysctl 旋钮(
vm.dirty_background_ratio和vm.dirty_ratio)。当脏限制分布在 cgroup 之间时,单个 cgroup 的内存限制会发挥作用,这反过来可能会影响受影响 cgroup 的 I/O 强度。并非所有存储都相同。I/O 控制发生在 I/O 调度层,这对于堆叠在其上不进行实际调度设备的设置会产生影响。考虑跨多个物理设备的设备映射器逻辑卷、MD RAID 甚至 Btrfs RAID。对此类设置进行 I/O 控制可能具有挑战性。
没有单独的读写比例 I/O 控制设置。
比例 I/O 控制只是可能相互作用的策略之一(但负责的资源设计可能避免这种情况)。
I/O 设备带宽并非 I/O 路径上唯一的共享资源。全局文件系统结构参与其中,这在 I/O 控制旨在保证一定带宽时至关重要;它不能,甚至可能导致优先级反转(优先级高的 cgroup 等待优先级低的 cgroup 的事务)。
到目前为止,我们只讨论了文件系统数据的显式 I/O,但换入和换出也可以控制。尽管如果出现这种需求,它表明内存配置不当(或内存限制)。
为了在用户会话中应用 cgroup 资源控制,控制器必须委托给 systemd 的用户实例。openSUSE Leap 附带的 systemd 默认配置不委托任何控制器。
您可以使用临时文件更改委托控制器的集合。例如,/etc/systemd/system/user@.service.d/60-delegate.conf 将控制器添加到所有用户,而 /etc/systemd/system/user@uid.service.d/60-delegate.conf 仅将控制器添加到特定用户。文件的内容应如下所示
[Service] Delegate=pids memory
systemd 实例和受影响的用户实例都必须被通知重新加载新配置。
>sudosystemctl daemon-reload>systemctl --user daemon-reexec
或者,受影响的用户可以注销并登录,而不是第二行,以重新启动其用户实例。
内核文档(
kernel-source软件包):/usr/src/linux/Documentation/admin-guide/cgroup-v1中的文件和文件/usr/src/linux/Documentation/admin-guide/cgroup-v2.rst。man systemd.resource-controlhttps://lwn.net/Articles/604609/—Brown, Neil: Control Groups Series (2014, 7 parts)。
https://lwn.net/Articles/243795/—Corbet, Jonathan: Controlling memory use in containers (2007)。
https://lwn.net/Articles/236038/—Corbet, Jonathan: Process containers (2007)。
自动 NUMA 平衡分三个基本步骤进行
任务扫描程序定期扫描任务地址空间的一部分并标记内存,以便在下次访问数据时强制页面错误。
下次访问数据会导致 NUMA 提示错误。根据此错误,数据可以迁移到与访问内存的任务相关联的内存节点。
为了使任务、它使用的 CPU 和它访问的内存保持在一起,调度程序将共享数据的任务分组。
数据取消映射和页面错误处理会产生开销。但是,通常开销会被访问与 CPU 相关联的数据的线程抵消。
静态配置一直是 NUMA 硬件上调整工作负载的推荐方法。为此,可以使用 numactl、taskset 或 cpusets 设置内存策略。支持 NUMA 的应用程序可以使用特殊的 API。如果已经创建了静态策略,则应禁用自动 NUMA 平衡,因为数据访问应已是本地的。
numactl --hardware 显示机器的内存配置以及它是否支持 NUMA。这是 4 节点机器的示例输出。
> numactl --hardware
available: 4 nodes (0-3)
node 0 cpus: 0 4 8 12 16 20 24 28 32 36 40 44
node 0 size: 16068 MB
node 0 free: 15909 MB
node 1 cpus: 1 5 9 13 17 21 25 29 33 37 41 45
node 1 size: 16157 MB
node 1 free: 15948 MB
node 2 cpus: 2 6 10 14 18 22 26 30 34 38 42 46
node 2 size: 16157 MB
node 2 free: 15981 MB
node 3 cpus: 3 7 11 15 19 23 27 31 35 39 43 47
node 3 size: 16157 MB
node 3 free: 16028 MB
node distances:
node 0 1 2 3
0: 10 20 20 20
1: 20 10 20 20
2: 20 20 10 20
3: 20 20 20 10通过向 /proc/sys/kernel/numa_balancing 写入 1 或 0,可以为当前会话启用或禁用自动 NUMA 平衡,分别启用或禁用该功能。要永久启用或禁用它,请使用内核命令行选项 numa_balancing=[enable|disable]。
如果启用了自动 NUMA 平衡,则可以配置任务扫描程序行为。任务扫描程序通过识别最佳数据放置所需的时间来平衡自动 NUMA 平衡的开销。
numa_balancing_scan_delay_ms线程在扫描其数据之前必须消耗的 CPU 时间量。这可以防止因短寿命进程而产生开销。
numa_balancing_scan_period_min_ms和numa_balancing_scan_period_max_ms控制任务数据扫描的频率。根据错误的局部性,扫描速率会增加或减少。这些设置控制最小和最大扫描速率。
numa_balancing_scan_size_mb控制任务扫描程序处于活动状态时扫描的地址空间量。
最重要的任务是为您的工作负载分配指标,并在启用和禁用自动 NUMA 平衡的情况下测量性能以衡量影响。如果 CPU 支持此类监控,则可以使用分析工具监控本地和远程内存访问。自动 NUMA 平衡活动可以通过 /proc/vmstat 中的以下参数进行监控
numa_pte_updates被标记为 NUMA 提示错误的基页数量。
numa_huge_pte_updates被标记为 NUMA 提示错误的透明大页数量。结合
numa_pte_updates可以计算出被标记的总地址空间。numa_hint_faults记录了捕获了多少 NUMA 提示错误。
numa_hint_faults_local显示有多少提示错误是针对本地节点的。结合
numa_hint_faults,可以计算本地与远程错误的百分比。高百分比的本地提示错误表明工作负载更接近于收敛。numa_pages_migrated记录因放置错误而迁移的页面数量。由于迁移是复制操作,因此它构成了 NUMA 平衡产生的开销的最大部分。
以下是一个简单的测试用例,展示了在一台 4 节点 NUMA 机器上运行 SpecJBB 2005,使用单个 JVM 实例,且没有对内存策略进行静态调整。然而,每种工作负载的影响各不相同,此示例基于 openSUSE Leap 12 的预发布版本。
Balancing disabled Balancing enabled
TPut 1 26629.00 ( 0.00%) 26507.00 ( -0.46%)
TPut 2 55841.00 ( 0.00%) 53592.00 ( -4.03%)
TPut 3 86078.00 ( 0.00%) 86443.00 ( 0.42%)
TPut 4 116764.00 ( 0.00%) 113272.00 ( -2.99%)
TPut 5 143916.00 ( 0.00%) 141581.00 ( -1.62%)
TPut 6 166854.00 ( 0.00%) 166706.00 ( -0.09%)
TPut 7 195992.00 ( 0.00%) 192481.00 ( -1.79%)
TPut 8 222045.00 ( 0.00%) 227143.00 ( 2.30%)
TPut 9 248872.00 ( 0.00%) 250123.00 ( 0.50%)
TPut 10 270934.00 ( 0.00%) 279314.00 ( 3.09%)
TPut 11 297217.00 ( 0.00%) 301878.00 ( 1.57%)
TPut 12 311021.00 ( 0.00%) 326048.00 ( 4.83%)
TPut 13 324145.00 ( 0.00%) 346855.00 ( 7.01%)
TPut 14 345973.00 ( 0.00%) 378741.00 ( 9.47%)
TPut 15 354199.00 ( 0.00%) 394268.00 ( 11.31%)
TPut 16 378016.00 ( 0.00%) 426782.00 ( 12.90%)
TPut 17 392553.00 ( 0.00%) 437772.00 ( 11.52%)
TPut 18 396630.00 ( 0.00%) 456715.00 ( 15.15%)
TPut 19 399114.00 ( 0.00%) 484020.00 ( 21.27%)
TPut 20 413907.00 ( 0.00%) 493618.00 ( 19.26%)
TPut 21 413173.00 ( 0.00%) 510386.00 ( 23.53%)
TPut 22 420256.00 ( 0.00%) 521016.00 ( 23.98%)
TPut 23 425581.00 ( 0.00%) 536214.00 ( 26.00%)
TPut 24 429052.00 ( 0.00%) 532469.00 ( 24.10%)
TPut 25 426127.00 ( 0.00%) 526548.00 ( 23.57%)
TPut 26 422428.00 ( 0.00%) 531994.00 ( 25.94%)
TPut 27 424378.00 ( 0.00%) 488340.00 ( 15.07%)
TPut 28 419338.00 ( 0.00%) 543016.00 ( 29.49%)
TPut 29 403347.00 ( 0.00%) 529178.00 ( 31.20%)
TPut 30 408681.00 ( 0.00%) 510621.00 ( 24.94%)
TPut 31 406496.00 ( 0.00%) 499781.00 ( 22.95%)
TPut 32 404931.00 ( 0.00%) 502313.00 ( 24.05%)
TPut 33 397353.00 ( 0.00%) 522418.00 ( 31.47%)
TPut 34 382271.00 ( 0.00%) 491989.00 ( 28.70%)
TPut 35 388965.00 ( 0.00%) 493012.00 ( 26.75%)
TPut 36 374702.00 ( 0.00%) 502677.00 ( 34.15%)
TPut 37 367578.00 ( 0.00%) 500588.00 ( 36.19%)
TPut 38 367121.00 ( 0.00%) 496977.00 ( 35.37%)
TPut 39 355956.00 ( 0.00%) 489430.00 ( 37.50%)
TPut 40 350855.00 ( 0.00%) 487802.00 ( 39.03%)
TPut 41 345001.00 ( 0.00%) 468021.00 ( 35.66%)
TPut 42 336177.00 ( 0.00%) 462260.00 ( 37.50%)
TPut 43 329169.00 ( 0.00%) 467906.00 ( 42.15%)
TPut 44 329475.00 ( 0.00%) 470784.00 ( 42.89%)
TPut 45 323845.00 ( 0.00%) 450739.00 ( 39.18%)
TPut 46 323878.00 ( 0.00%) 435457.00 ( 34.45%)
TPut 47 310524.00 ( 0.00%) 403914.00 ( 30.07%)
TPut 48 311843.00 ( 0.00%) 459017.00 ( 47.19%)
Balancing Disabled Balancing Enabled
Expctd Warehouse 48.00 ( 0.00%) 48.00 ( 0.00%)
Expctd Peak Bops 310524.00 ( 0.00%) 403914.00 ( 30.07%)
Actual Warehouse 25.00 ( 0.00%) 29.00 ( 16.00%)
Actual Peak Bops 429052.00 ( 0.00%) 543016.00 ( 26.56%)
SpecJBB Bops 6364.00 ( 0.00%) 9368.00 ( 47.20%)
SpecJBB Bops/JVM 6364.00 ( 0.00%) 9368.00 ( 47.20%)自动 NUMA 平衡简化了在 NUMA 机器上对工作负载进行高性能调整。在可能的情况下,仍然建议静态调整工作负载以将其划分到每个节点内。然而,在所有其他情况下,自动 NUMA 平衡都应提高性能。
在 CPU 级别,您可以通过多种方式控制功耗。例如,使用空闲电源状态(C 状态)、更改 CPU 频率(P 状态)和限制 CPU(T 状态)。以下章节简要介绍了每种方法及其对节能的意义。详细规范可在 https://uefi.org/sites/default/files/resources/ACPI_Spec_6_4_Jan22.pdf 中找到。
现代处理器有几种省电模式,称为 C 状态。它们反映了空闲处理器关闭未使用组件以节省电量的能力。
当处理器处于 C0 状态时,它正在执行指令。处于任何其他 C 状态的处理器都是空闲的。C 编号越高,CPU 睡眠模式越深:关闭的组件越多,以节省电量。更深的睡眠状态可以节省大量能源。它们的缺点是会引入延迟。这意味着,CPU 返回 C0 需要更长的时间。根据工作负载(线程唤醒,触发 CPU 使用,然后又短暂地再次进入睡眠状态)和硬件(例如,网络设备的中断活动),禁用最深的睡眠状态可以提高整体性能。有关如何操作的详细信息,请参阅 第 12.3.2 节“使用 cpupower 查看内核空闲统计信息”。
某些状态也有具有不同节能延迟级别的子模式。支持哪些 C 状态和子模式取决于相应的处理器。但是,C1 始终可用。
表 12.1,“C 状态”概述了最常见的 C 状态。
表 12.1: C 状态 #
|
模式 |
定义 |
|---|---|
|
C0 |
操作状态。CPU 完全开启。 |
|
C1 |
第一个空闲状态。通过软件停止 CPU 主要内部时钟。总线接口单元和 APIC 以全速运行。 |
|
C2 |
通过硬件停止 CPU 主要内部时钟。处理器维护所有软件可见状态的状态,但通过中断唤醒可能需要更长时间。 |
|
C3 |
停止所有 CPU 内部时钟。处理器不需要保持其缓存一致,但维护其他状态。某些处理器具有 C3 状态的变体,其通过中断唤醒处理器的所需时间不同。 |
为避免不必要的功耗,建议测试您的工作负载,比较启用深度睡眠状态和禁用深度睡眠状态的情况。有关更多信息,请参阅 第 12.3.2 节“使用 cpupower 查看内核空闲统计信息” 或 cpupower-idle-set(1) 手册页。
当处理器运行时(在 C0 状态),它可以处于几种 CPU 性能状态 (P 状态) 之一。C 状态是空闲状态(除了 C0),而 P 状态 是与 CPU 频率和电压相关的操作状态。
P 状态越高,处理器运行的频率和电压越低。P 状态的数量是处理器特定的,并且实现方式因不同类型而异。但是,P0 始终是最高性能状态(第 12.1.3 节“睿频特性” 除外)。更高的 P 状态编号表示更慢的处理器速度和更低的功耗。例如,处于 P3 状态的处理器比处于 P1 状态的处理器运行速度更慢且功耗更低。要以任何 P 状态运行,处理器必须处于 C0 状态,这意味着它正在工作而不是空闲。CPU P 状态也在 ACPI 规范中定义,请参阅 https://uefi.org/sites/default/files/resources/ACPI_Spec_6_5_Aug29.pdf。
C 状态和 P 状态可以相互独立变化。
睿频功能允许在其他核心处于深度睡眠状态时动态地超频活动 CPU 核心。这提高了活动线程的性能,同时仍符合热设计功耗 (TDP) 限制。
然而,CPU 核心使用睿频频率的条件是架构特定的。了解如何在 第 12.3 节“cpupower 工具” 中评估这些新功能的效率。
内核内置调节器属于 Linux 内核 CPUfreq 基础设施,可用于在运行时动态调整处理器频率。您可以将调节器视为 CPU 的一种预配置电源方案。CPUfreq 调节器使用 P 状态来改变频率和降低功耗。动态调节器可以根据 CPU 使用情况在 CPU 频率之间切换,从而在不牺牲性能的情况下实现节能。
CPUfreq 子系统提供以下调节器
- 性能调节器
CPU 频率静态设置为最高,以实现最大性能。因此,节能不是此调节器的重点。
另请参阅 第 12.4.1 节“P 状态的调整选项”。
- 节能调节器
CPU 频率静态设置为尽可能最低。这可能会对性能产生严重影响,因为无论处理器多忙,系统都不会提高到此频率以上。一个重要的例外是
intel_pstate,它默认为powersave模式。这是由于硬件特定的决定,但其功能上类似于on-demand调节器。然而,使用此调节器通常不会带来预期的节电效果,因为通过进入 C 状态可以在空闲时实现最高节电。使用 powersave 调节器,进程以最低频率运行,因此完成时间更长。这意味着系统进入空闲 C 状态所需的时间更长。
调整选项:可以调整调节器可用的最小频率范围(例如,使用
cpupower命令行工具)。- 按需调节器
动态 CPU 频率策略的内核实现:调节器监控处理器使用情况。当处理器使用率超过某个阈值时,调节器会将频率设置为最高可用频率。如果使用率低于阈值,则使用下一个最低频率。如果系统继续处于低利用率状态,频率将再次降低,直到设置为最低可用频率。
重要:驱动程序和内核内置调节器
并非所有驱动程序都使用内核内置调节器在运行时动态调整电源频率。例如,intel_pstate 驱动程序自行调整电源频率。使用 cpupower frequency-info 命令可以找出您的系统使用哪个驱动程序。
cpupower 工具旨在概述给定机器上支持的所有与 CPU 功耗相关的参数,包括睿频(或加速)状态。使用该工具集可以查看和修改内核相关的 CPUfreq 和 cpuidle 系统设置以及其他与频率缩放或空闲状态无关的设置。集成的监控框架可以访问内核相关参数和硬件统计数据。因此,它非常适合性能基准测试。它还可以帮助您识别睿频和空闲状态之间的依赖关系。
安装 cpupower 软件包后,使用 cpupower --help 查看可用的 cpupower 子命令。使用 man cpupower 访问通用手册页,使用 man cpupower-SUBCOMMAND 访问子命令手册页。
cpupower frequency-info 命令显示内核中使用的 cpufreq 驱动程序的统计信息。此外,它还显示 BIOS 中是否支持并启用了睿频(加速)状态。不带任何选项运行,它会显示类似以下的输出
示例 12.1: cpupower frequency-info 示例输出 #
# cpupower frequency-info
analyzing CPU 0:
driver: intel_pstate
CPUs which run at the same hardware frequency: 0
CPUs which need to have their frequency coordinated by software: 0
maximum transition latency: 0.97 ms.
hardware limits: 1.20 GHz - 3.80 GHz
available cpufreq governors: performance, powersave
current policy: frequency should be within 1.20 GHz and 3.80 GHz.
The governor "powersave" may decide which speed to use
within this range.
current CPU frequency is 3.40 GHz (asserted by call to hardware).
boost state support:
Supported: yes
Active: yes
3500 MHz max turbo 4 active cores
3600 MHz max turbo 3 active cores
3600 MHz max turbo 2 active cores
3800 MHz max turbo 1 active cores要获取所有 CPU 的当前值,请使用 cpupower -c all frequency-info。
idle-info 子命令显示内核中使用的 cpuidle 驱动程序的统计信息。它适用于所有使用 cpuidle 内核框架的架构。
示例 12.2: cpupower idle-info 示例输出 #
# cpupower idle-info
CPUidle driver: intel_idle
CPUidle governor: menu
Analyzing CPU 0:
Number of idle states: 6
Available idle states: POLL C1-SNB C1E-SNB C3-SNB C6-SNB C7-SNB
POLL:
Flags/Description: CPUIDLE CORE POLL IDLE
Latency: 0
Usage: 163128
Duration: 17585669
C1-SNB:
Flags/Description: MWAIT 0x00
Latency: 2
Usage: 16170005
Duration: 697658910
C1E-SNB:
Flags/Description: MWAIT 0x01
Latency: 10
Usage: 4421617
Duration: 757797385
C3-SNB:
Flags/Description: MWAIT 0x10
Latency: 80
Usage: 2135929
Duration: 735042875
C6-SNB:
Flags/Description: MWAIT 0x20
Latency: 104
Usage: 53268
Duration: 229366052
C7-SNB:
Flags/Description: MWAIT 0x30
Latency: 109
Usage: 62593595
Duration: 324631233978在通过 cpupower idle-info 找出支持哪些处理器空闲状态后,可以使用 cpupower idle-set 命令禁用单个状态。通常,人们希望禁用最深的睡眠状态,例如
# cpupower idle-set -d 5或者,禁用所有延迟等于或高于 80 的 CPU
# cpupower idle-set -D 80使用 monitor 子命令报告处理器拓扑,并在一定时间内监控频率和空闲电源状态统计信息。默认间隔为 1 秒,但可以使用 -i 更改。工具中实现了独立的处理器睡眠状态和频率计数器——有些从内核统计信息中检索,有些读取硬件寄存器。可用的监视器取决于底层硬件和系统。使用 cpupower monitor -l 列出它们。有关单个监视器的描述,请参阅 cpupower-monitor 手册页。
monitor 子命令允许您执行性能基准测试。要将内核统计信息与特定工作负载的硬件统计信息进行比较,请连接相应的命令,例如
cpupowermonitordb_test.sh
示例 12.3: cpupower monitor 输出示例 #
# cpupower monitor
|Mperf || Idle_Stats
1 2
CPU | C0 | Cx | Freq || POLL | C1 | C2 | C3
0| 3.71| 96.29| 2833|| 0.00| 0.00| 0.02| 96.32
1| 100.0| -0.00| 2833|| 0.00| 0.00| 0.00| 0.00
2| 9.06| 90.94| 1983|| 0.00| 7.69| 6.98| 76.45
3| 7.43| 92.57| 2039|| 0.00| 2.60| 12.62| 77.52Mperf 显示 CPU 的平均频率,包括加速频率,随时间变化。此外,它还显示 CPU 处于活动状态 ( | |
Idle_Stats 显示 cpuidle 内核子系统的统计信息。内核在每次进入或退出空闲状态时更新这些值。因此,当核心在测量开始或结束时处于空闲状态一段时间时,可能会出现一些不准确。 |
除了上述示例中的(通用)监控器之外,还有其他特定于架构的监控器可用。有关详细信息,请参阅 cpupower-monitor 手册页。
通过比较各个监控器的值,您可以发现相关性和依赖性,并评估节能机制对特定工作负载的工作效果。示例 12.3 中,您可以看到 CPU 0 处于空闲状态(Cx 的值接近 100%),但运行在高频率。这是因为 CPU 0 和 1 具有相同的频率值,这意味着它们之间存在依赖关系。
以下章节重点介绍重要设置。
- BIOS 选项是否启用?
要使用 C 状态或 P 状态,请检查您的 BIOS 选项
要使用 C 状态,请确保启用
CPU C State或类似选项,以便在空闲时受益于节能。要使用 P 状态和 CPUfreq 调节器,请确保启用
Processor Performance States选项或类似选项。即使 P 状态和 C 状态可用,平台固件也可能正在管理 CPU 频率,这可能不是最佳的。例如,如果加载了
pcc-cpufreq,则操作系统仅向固件提供提示,固件可以自由忽略这些提示。这可以通过在 BIOS 中选择“OS Management”或类似选项来管理 CPU 频率。重启后,将使用备用驱动程序,但应仔细测量性能影响。
如果 CPU 升级,请务必也升级您的 BIOS。BIOS 需要知道新的 CPU 及其频率步进,以便将此信息传递给操作系统。
- 日志文件信息?
检查
systemd日志(请参阅 《参考》一书,第 11 章“journalctl:查询systemd日志”),以查找有关 CPUfreq 子系统的任何输出。仅报告严重错误。如果您怀疑机器上的 CPUfreq 子系统存在问题,还可以启用附加调试输出。为此,可以使用
cpufreq.debug=7作为引导参数,或以root身份执行以下命令#echo 7 > /sys/module/cpufreq/parameters/debug这将使 CPUfreq 在状态转换时向
dmesg记录更多信息,这有助于诊断。但由于这种额外的内核消息输出可能相当全面,因此仅在确定存在问题时才使用它。
powerTOP 有助于识别不必要的高功耗原因。这对于笔记本电脑尤其有用,因为最大限度地降低功耗更为重要。它支持 Intel 和 AMD 处理器。以通常的方式安装它
>sudozypper in powertop
powerTOP 结合了多种信息来源(程序分析、设备驱动程序、内核选项、唤醒处理器从睡眠状态中断的数量和来源),并提供了多种查看方式。您可以在交互模式下启动它,该模式在 ncurses 会话中运行(请参阅 图 12.1,“powerTOP 交互模式”)
>sudopowertop
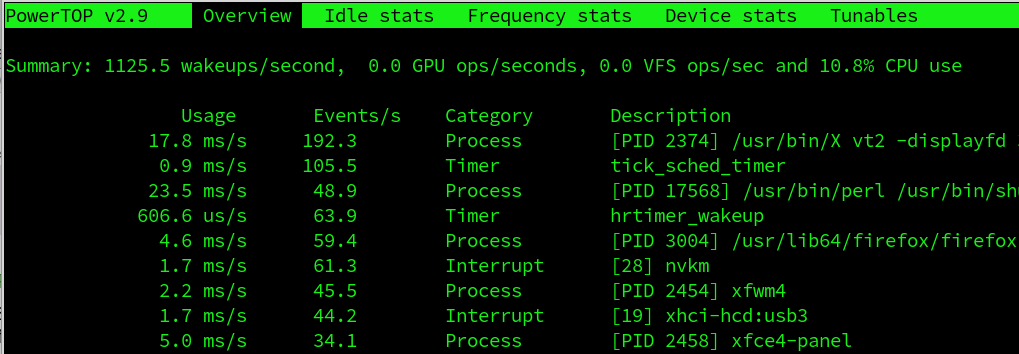
图 12.1: powerTOP 交互模式 #
powerTOP 支持将报告导出为 HTML 和 CSV。以下示例生成一个 240 秒运行的单个报告
>sudopowertop --iteration=1 --time=240 --html=POWERREPORT.HTML
运行单独的报告随着时间的推移可能很有用。以下示例运行 powerTOP 10 次,每次 20 秒,并为每次运行创建单独的 HTML 报告
>sudopowertop --iteration=10 --time=20 --html=POWERREPORT.HTML
这将创建 10 个带时间戳的报告
powerreport-20200108-104512.html powerreport-20200108-104451.html powerreport-20200108-104431.html [...]
HTML 报告如下所示 图 12.2,“HTML powerTOP 报告”
图 12.2: HTML powerTOP 报告 #
HTML 报告的“Tuning”选项卡和交互模式下的“Tunables”选项卡都提供了用于测试各种电源设置的命令。HTML 报告会打印命令,您可以将其复制到 root 命令行进行测试,例如 echo '0' > '/proc/sys/kernel/nmi_watchdog'。ncurses 模式提供了在 Good 和 Bad 之间切换的简单开关。Good 运行命令以启用省电,Bad 关闭省电。使用一个命令启用所有 powerTOP 设置
>sudopowertop --auto-tune
这些更改在重启后都不会保留。要使任何更改永久生效,请使用 sysctl、udev 或 systemd 在启动时运行您选择的命令。powerTOP 包含一个 systemd 服务文件 /usr/lib/systemd/system/powertop.service。它会使用 --auto-tune 选项启动 powerTOP
ExecStart=/usr/sbin/powertop --auto-tune
在启动 systemd 服务之前仔细测试,看看它是否能达到您想要的效果。您不应使用 USB 键盘和鼠标进入省电模式,以避免不断唤醒它们并干扰其他设备。为了更轻松地测试和编辑配置,请使用 awk 从 HTML 报告中提取命令
> awk -F '</?td ?>' '/tune/ { print $4 }' POWERREPORT.HTML在校准模式下,powerTOP 会设置几次运行,使用不同的背光、CPU、Wi-Fi、USB 设备和磁盘空闲设置,并有助于识别电池供电下的最佳亮度设置
>sudopowertop --calibrate
您可以调用一个文件来创建工作负载以进行更准确的校准
>sudopowertop --calibrate --workload=FILENAME --html=POWERREPORT.HTML
有关更多信息,请参阅
powerTOP 项目页面位于 https://01.org/powertop
《参考》一书,第 10 章“
systemd守护进程”《参考》一书,第 16 章“使用
udev进行动态内核设备管理”
- 13 调优 I/O 性能
I/O 调度控制着如何将输入/输出操作提交到存储设备。 openSUSE Leap 提供了几种 I/O 算法,称为
电梯调度器 (elevators),适用于不同的工作负载。 电梯调度器可以帮助减少寻道操作,并可以优先处理 I/O 请求。- 14 调优任务调度器
现代操作系统,如 openSUSE® Leap,通常同时运行许多任务。例如,您可能正在搜索文本文件,同时收到电子邮件并将大文件复制到外部硬盘。这些简单的任务需要系统运行许多额外的进程。为了给每个任务提供所需的系统资源,…
- 15 调优内存管理子系统
要理解和调整内核的内存管理行为,首先需要了解它的工作方式以及它与其他子系统的协作方式。
- 16 调优网络
网络子系统是复杂的,其调优高度依赖于系统使用场景以及外部因素,例如网络中的软件客户端或硬件组件(交换机、路由器或网关)。Linux 内核旨在提供可靠性和低延迟,而不是低开销和高吞吐量……
I/O 调度控制着如何将输入/输出操作提交到存储设备。 openSUSE Leap 提供了几种 I/O 算法,称为 电梯调度器 (elevators),适用于不同的工作负载。 电梯调度器可以帮助减少寻道操作,并可以优先处理 I/O 请求。
选择最适合的 I/O 调度器不仅取决于工作负载,还取决于硬件。例如,单个 ATA 磁盘系统、SSD、RAID 阵列或网络存储系统都需要不同的调优策略。
openSUSE Leap 在启动时选择一个默认的 I/O 调度器,可以为每个块设备动态更改。这使得可以为不同的算法设置不同的算法,例如,用于托管系统分区的设备和托管数据库的设备。
根据设备是否报告为旋转磁盘,为每个设备选择默认的 I/O 调度器。对于旋转磁盘,选择 BFQ I/O 调度器。其他设备默认为 MQ-DEADLINE 或 NONE。
要在运行的系统中更改特定设备的调度器,请运行以下命令
>sudoecho SCHEDULER > /sys/block/DEVICE/queue/scheduler
这里,SCHEDULER 是 bfq、none、kyber 或 mq-deadline 之一。DEVICE 是块设备(例如 sda)。此更改在重启后不会保留。要永久更改特定设备的 I/O 调度器,请将 /usr/lib/udev/rules.d/60-io-scheduler.rules 复制到 /etc/udev/rules.d/60-io-scheduler.rules,并编辑后者文件以适应您的需求。
以下是 openSUSE Leap 上适用于使用 blk-mq I/O 路径的设备的可用调度器列表。如果调度器具有可调参数,则可以使用以下命令进行设置
echo VALUE > /sys/block/DEVICE/queue/iosched/TUNABLE
在上述命令中,VALUE 是 TUNABLE 的所需值,DEVICE 是块设备。
要查找设备(例如 sda)可用的调度器,请运行以下命令(当前选定的调度器列在括号中)
> cat /sys/block/sda/queue/scheduler
[mq-deadline] kyber bfq none
MQ-DEADLINE 是一种面向延迟的 I/O 调度器。MQ-DEADLINE 具有以下可调参数
表 13.1: MQ-DEADLINE 可调参数 #
文件 | 描述 |
|---|---|
| 控制读取优先于写入的次数。值为 默认值为 |
| 设置读操作的截止时间(当前时间加上 默认值为 |
| 设置写操作的截止时间(当前时间加上 默认值为 |
| 启用 (1) 或禁用 (0) 前端合并请求的尝试。 默认值为 |
| 设置每个批次的最大请求数(截止时间仅针对批次进行检查)。此参数允许在延迟和吞吐量之间进行平衡。当设置为 默认值为 |
当选择 NONE 作为 blk-mq 的 I/O 调度器选项时,不使用 I/O 调度器,I/O 请求将直接传递到设备,无需进一步的 I/O 调度交互。
NONE 是 NVM Express 设备的默认设置。与其他 I/O 调度器选项相比,它没有开销,被认为是将 I/O 请求以多队列方式传递到此类设备的最快方式。
NONE 没有可调参数。
BFQ 是一种面向公平性的调度器。它被描述为“一种基于 CFQ 的按片服务方案的比例共享存储 I/O 调度算法。但 BFQ 将预算(以扇区数衡量)分配给进程,而不是时间片。”(来源:linux-4.12/block/bfq-iosched.c)
BFQ 允许为任务分配 I/O 优先级,这些优先级在调度决策中会被考虑(参见 第 9.3.3 节,“使用 ionice 优先处理磁盘访问”)。
BFQ 调度器具有以下可调参数
表 13.2: BFQ 可调参数 #
文件 | 描述 |
|---|---|
| 以毫秒为单位的值,指定空闲等待空队列上下一个请求的时间。 默认值为 |
| 与 默认值为 |
| 启用 (1) 或禁用 (0) 默认值为 |
| 向后寻道的最大值(以 KB 为单位)。 默认值为 |
| 用于计算向后寻道的成本。 默认值为 |
| 值(以毫秒为单位)用于设置异步请求的超时。 默认值为 |
| 以毫秒为单位的值,指定同步请求的超时时间。 默认值为 |
| 任务(队列)被选中后服务的最大时间(毫秒)。 默认值为 |
|
默认值为 |
| 启用 (1) 或禁用 (0) 默认值为 |
某些文件系统(例如 Ext3 或 Ext4)在 fsync 或事务提交期间会向磁盘发送写屏障。写屏障强制正确的写入顺序,使易失性磁盘写入缓存安全可用(但会降低性能)。如果您的磁盘以某种方式由电池供电,则禁用屏障可以安全地提高性能。
重要:nobarrier 在 XFS 中已弃用
nobarrier 选项在 XFS 中已弃用,并且在 SUSE Linux Enterprise 15 SP2 及更高版本中不是有效的挂载选项。任何明确指定该标志的 XFS 挂载命令都可能无法挂载文件系统。为防止这种情况发生,请确保没有任何脚本或 fstab 条目包含 nobarrier 选项。
可以使用 nobarrier 挂载选项禁用发送写屏障。
警告:禁用屏障可能导致数据丢失
当磁盘无法保证在断电情况下正确写入缓存时禁用屏障,可能导致严重的文件系统损坏和数据丢失。
现代操作系统,例如 openSUSE® Leap,通常同时运行许多任务。例如,您可能正在搜索文本文件,同时收到电子邮件并将大文件复制到外部硬盘。这些简单的任务需要系统运行许多额外的进程。为了给每个任务提供所需的系统资源,Linux 内核需要一个工具来将可用的系统资源分配给单个任务。这正是任务调度程序所做的。
以下章节解释了与进程调度相关的最重要术语。它们还介绍了任务调度策略、调度算法、openSUSE Leap 使用的任务调度程序的描述以及相关信息的其他来源。
Linux 内核控制系统上任务(或进程)的管理方式。任务调度程序,有时称为进程调度程序,是内核中决定下一个运行哪个任务的部分。它负责优化系统资源的使用,以确保多个任务同时执行。这使其成为任何多任务操作系统的核心组件。
任务调度的理论很简单。如果系统中存在可运行的进程,则至少一个进程必须始终运行。如果系统中可运行的进程多于处理器,则并非所有进程都能始终运行。
因此,某些进程需要暂时停止,或挂起,以便其他进程可以再次运行。调度程序决定队列中哪个进程接下来运行。
如前所述,Linux 与所有其他 Unix 变体一样,是一个多任务操作系统。这意味着可以同时运行多个任务。Linux 提供了一种所谓的抢占式多任务处理,其中调度程序决定何时挂起进程。这种强制挂起称为抢占。所有 Unix 版本从一开始就提供了抢占式多任务处理。
进程在被抢占之前运行的时间段是预先定义的。它被称为进程的时间片,代表提供给每个进程的处理器时间量。通过分配时间片,调度器为运行系统做出全局决策,并防止单个进程独占处理器资源。
进程根据其目的和行为进行分类。尽管界限并不总是明确的,但通常使用两个标准对其进行排序。这些标准是独立的,不相互排斥。
一种方法是将进程分类为I/O 密集型或处理器密集型。
- I/O 密集型
I/O 代表输入/输出设备,如键盘、鼠标或光驱和硬盘。I/O 密集型进程大部分时间用于提交和等待请求。它们频繁运行,但时间间隔短,以免阻塞等待 I/O 请求的其他进程。
- 处理器密集型
处理器限制任务将其时间用于执行代码,并一直运行直到被调度程序抢占。它们不会阻塞等待 I/O 请求的进程,因此可以以较低的频率运行但持续较长的时间间隔。
另一种方法是将进程按类型划分为交互式、批处理和实时进程。
交互式进程花费大量时间等待 I/O 请求,例如键盘或鼠标操作。调度程序必须在用户请求时快速唤醒此类进程,否则用户会觉得环境无响应。典型的延迟约为 100 毫秒。办公应用程序、文本编辑器或图像处理程序代表典型的交互式进程。
批处理进程通常在后台运行,不需要响应。它们从调度程序那里获得较低的优先级。多媒体转换器、数据库搜索引擎或日志文件分析器是批处理进程的典型示例。
实时进程绝不能被低优先级进程阻塞,调度程序保证它们有较短的响应时间。编辑多媒体内容的应用程序是一个很好的例子。
自 Linux 内核版本 2.6.23 以来,已对可运行进程的调度采取了一种新方法。完全公平调度程序 (CFS) 成为默认的 Linux 内核调度程序。此后,进行了重要的更改和改进。本章中的信息适用于内核版本 2.6.32 及更高版本(包括 3.x 内核)的 openSUSE Leap。调度程序环境分为几个部分,并引入了三个主要新功能
- 模块化调度程序核心
调度程序的核心通过调度类得到增强。这些类是模块化的,代表调度策略。
- 完全公平调度程序
CFS 于内核 2.6.23 中引入并在 2.6.24 中扩展,它试图确保每个进程获得其“公平”的处理器时间份额。
- 组调度
例如,如果您根据运行进程的用户将进程分组,CFS 会尝试为每个组提供相同数量的处理器时间。
因此,CFS 为服务器和桌面带来了优化的调度。
CFS 尝试保证对每个可运行任务的公平方法。为了找到最平衡的任务调度方式,它使用了红黑树的概念。红黑树是一种自平衡数据搜索树,它以合理的方式插入和删除条目,使其保持良好平衡。
当 CFS 调度任务时,它会累积“虚拟运行时”或vruntime。下一个被选择运行的任务始终是迄今为止累积 vruntime 最小的任务。通过在将任务插入运行队列(即将执行的进程的计划时间线)时平衡红黑树,vruntime 最小的任务始终是红黑树中的第一个条目。
任务累积的 vruntime 量与其优先级相关。高优先级任务获得 vruntime 的速度比低优先级任务慢,这导致高优先级任务更频繁地被选择在处理器上运行。
自 Linux 内核版本 2.6.24 以来,CFS 可以进行调整,以对组而不是仅对任务公平。然后将可运行任务分组形成实体,CFS 尝试对这些实体而不是单个可运行任务公平。调度程序还尝试对这些实体中的单个任务公平。
内核调度程序允许您使用控制组对可运行任务进行分组。有关更多信息,请参阅第 10 章,内核控制组。
任务调度程序行为的基本方面可以通过内核配置选项进行设置。设置这些选项是内核编译过程的一部分。由于内核编译过程是一项复杂的任务,并且超出了本文档的范围,请参阅相关信息源。
警告:内核编译
如果您在未随 openSUSE Leap 提供的内核上运行它,例如在自编译内核上,您将失去所有支持权利。
有关任务调度策略的文档经常使用一些您需要了解的技术术语才能正确理解信息。其中一些如下
- 延迟
进程调度运行时间与实际进程执行时间之间的延迟。
- 粒度
粒度与延迟之间的关系可以用以下公式表示
gran = ( lat / rtasks ) - ( lat / rtasks / rtasks )
其中 gran 代表粒度,lat 代表延迟,rtasks 是运行任务的数量。
chrt 命令设置或检索正在运行的进程的实时调度属性,或使用指定属性运行命令。您可以获取或检索进程的调度策略和优先级。
在以下示例中,使用了 PID 为 16244 的进程。
要检索现有任务的实时属性
# chrt -p 16244
pid 16244's current scheduling policy: SCHED_OTHER
pid 16244's current scheduling priority: 0在进程上设置新的调度策略之前,您需要找出每个调度算法的最小和最大有效优先级
# chrt -m
SCHED_SCHED_OTHER min/max priority : 0/0
SCHED_SCHED_FIFO min/max priority : 1/99
SCHED_SCHED_RR min/max priority : 1/99
SCHED_SCHED_BATCH min/max priority : 0/0
SCHED_SCHED_IDLE min/max priority : 0/0在上述示例中,SCHED_OTHER、SCHED_BATCH、SCHED_IDLE 策略只允许优先级 0,而 SCHED_FIFO 和 SCHED_RR 的优先级范围为 1 到 99。
设置 SCHED_BATCH 调度策略
# chrt -b -p 0 16244
pid 16244's current scheduling policy: SCHED_BATCH
pid 16244's current scheduling priority: 0有关 chrt 的更多信息,请参阅其手册页 (man 1 chrt)。
用于在运行时检查和更改内核参数的 sysctl 接口引入了重要的变量,您可以使用它们更改任务调度程序的默认行为。sysctl 的语法很简单,所有以下命令都必须在命令行上以 root 身份输入。
要从内核变量中读取值,请输入
#sysctl VARIABLE
要赋值,请输入
#sysctl VARIABLE=VALUE
要获取所有与调度程序相关的变量列表,请运行 sysctl 命令,并使用 grep 过滤输出
#sysctl -A | grep "sched" | grep -v "domain"kernel.sched_cfs_bandwidth_slice_us = 5000 kernel.sched_child_runs_first = 0 kernel.sched_compat_yield = 0 kernel.sched_latency_ns = 24000000 kernel.sched_migration_cost_ns = 500000 kernel.sched_min_granularity_ns = 8000000 kernel.sched_nr_migrate = 32 kernel.sched_rr_timeslice_ms = 25 kernel.sched_rt_period_us = 1000000 kernel.sched_rt_runtime_us = 950000 kernel.sched_schedstats = 0 kernel.sched_shares_window_ns = 10000000 kernel.sched_time_avg_ms = 1000 kernel.sched_tunable_scaling = 1 kernel.sched_wakeup_granularity_ns = 10000000
以“_ns”和“_us”结尾的变量分别接受纳秒和微秒的值。
以下是与任务调度程序相关的最重要的 sysctl 调优变量(位于 /proc/sys/kernel/)及其简要描述的列表
sched_cfs_bandwidth_slice_us当使用 CFS 带宽控制时,此参数控制从任务的控制组带宽池传输到运行队列的运行时(带宽)量。小值允许全局带宽在任务之间以细粒度方式共享,大值减少传输开销。请参阅 https://linuxkernel.org.cn/doc/Documentation/scheduler/sched-bwc.txt。
sched_child_runs_first新分叉的子进程在父进程继续执行之前运行。将此参数设置为
1对子进程在分叉后执行的应用程序有益。sched_compat_yield通过将放弃任务移动到可运行队列的末尾(红黑树中最右侧的位置),启用旧 O(1) 调度程序的激进 CPU 让步行为。依赖于
sched_yield(2)系统调用行为的应用程序可能会通过在存在高度竞争资源(如锁)时给其他进程运行机会来看到性能改进。鉴于此调用发生在上下文切换中,滥用此调用可能会损害工作负载。仅当您看到性能下降时才使用它。默认值为0。sched_migration_cost_ns任务在迁移决策中被认为是“缓存热”的最后执行后时间量。“热”任务迁移到另一个 CPU 的机会较少,因此增加此变量会减少任务迁移。默认值为
500000(纳秒)。如果存在可运行进程时 CPU 空闲时间高于预期,请尝试减小此值。如果任务在 CPU 或节点之间反弹过于频繁,请尝试增加此值。
sched_latency_nsCPU 限制任务的目标抢占延迟。增加此变量会增加 CPU 限制任务的时间片。任务的时间片是其在调度周期中的加权公平份额
时间片 = 调度周期 * (任务权重/运行队列中任务的总权重)
任务的权重取决于任务的 nice 级别和调度策略。SCHED_OTHER 任务的最小任务权重为 15,对应 nice 19。最大任务权重为 88761,对应 nice -20。
随着负载的增加,时间片会变小。当可运行任务的数量超过
sched_latency_ns/sched_min_granularity_ns时,时间片变为 number_of_running_tasks *sched_min_granularity_ns。在此之前,时间片等于sched_latency_ns。此值还指定了休眠任务在权利计算中被视为运行的最大时间量。增加此变量会增加唤醒任务在被抢占之前可能消耗的时间量,从而增加 CPU 限制任务的调度程序延迟。默认值为
6000000(纳秒)。sched_min_granularity_nsCPU 限制任务的最小抢占粒度。详情请参阅
sched_latency_ns。默认值为4000000(纳秒)。sched_wakeup_granularity_ns唤醒抢占粒度。增加此变量会减少唤醒抢占,减少对计算密集型任务的干扰。降低此变量会改善延迟关键型任务的唤醒延迟和吞吐量,特别是当短占空比负载组件必须与 CPU 密集型组件竞争时。默认值为
2500000(纳秒)。警告:设置正确的唤醒粒度值
大于
sched_latency_ns一半的设置会导致没有唤醒抢占。短占空比任务无法有效地与 CPU 占用者竞争。sched_rr_timeslice_msSCHED_RR 任务在被抢占并置于任务列表末尾之前允许运行的时间量子。
sched_rt_period_us实时任务带宽强制执行的测量周期。默认值为
1000000(微秒)。sched_rt_runtime_us在 sched_rt_period_us 期间分配给实时任务的时间量子。设置为 -1 会禁用 RT 带宽强制执行。默认情况下,RT 任务可能会消耗 95% CPU/秒,因此 SCHED_OTHER 任务可以使用 5% CPU/秒或 0.05 秒。默认值为
950000(微秒)。sched_nr_migrate控制为负载平衡目的可在处理器之间迁移的任务数量。因为平衡会禁用中断(软中断)迭代运行队列,所以它可能会导致实时任务的 irq 延迟惩罚。因此,增加此值可能会提高大型 SCHED_OTHER 线程的性能,但代价是增加实时任务的 irq 延迟。默认值为
32。sched_time_avg_ms此参数设置运行实时任务所花费时间的平均周期。该平均值有助于 CFS 做出负载平衡决策,并指示 CPU 在高优先级实时任务上的繁忙程度。
此参数的最佳设置高度依赖于工作负载,并且除其他因素外,还取决于实时任务运行的频率和持续时间。
警告:一些调度程序参数已移至 debugfs
如果您的操作系统的默认 Linux 内核版本是 5.13 或更高版本(可以使用命令 rpm -q kernel-default 检查),您可能会在内核日志中注意到类似于以下示例的消息
[ 20.485624] The sched.sched_min_granularity_ns sysctl was moved to debugfs in kernel 5.13 for CPU scheduler debugging only. This sysctl will be removed in a future SLE release. [ 20.485632] The sched.sched_wakeup_granularity_ns sysctl was moved to debugfs in kernel 5.13 for CPU scheduler debugging only. This sysctl will be removed in a future SLE release.
发生这种情况是因为六个调度程序参数已从 /proc/sys/kernel/sched_* 移至 /sys/kernel/debug/sched/*。受影响的调度程序参数如下
sched_latency_nssched_migration_cost_nssched_min_granularity_nssched_nr_migratesched_tunable_scalingsched_wakeup_granularity_n
为了临时方便,这些调度程序参数的 sysctl 在 openSUSE Leap 中仍然存在。但是,由于 CPU 调度程序实现的计划更改,无法保证 sysctl 或 debugfs 选项会在 openSUSE Leap 的未来版本中存在。
如果您当前的任何系统调优配置依赖于这六个调度程序参数,我们强烈建议您寻找实现目标的替代方法,并停止在生产工作负载中依赖它们。
CFS 附带了一个新的改进调试接口,并提供运行时统计信息。相关文件已添加到 /proc 文件系统,可以简单地使用 cat 或 less 命令进行检查。以下是相关 /proc 文件及其简要描述的列表
/proc/sched_debug包含影响任务调度程序行为的所有可调变量(请参阅第 14.3.6 节,“使用
sysctl进行运行时调优”)的当前值、CFS 统计信息以及所有可用处理器上运行队列(CFS、RT 和截止时间)的信息。还显示了每个处理器上运行的任务摘要,包括任务名称和 PID,以及调度程序特定的统计信息。第一个是tree-key列,它指示任务的虚拟运行时,其名称来自内核通过此键在红黑树中对所有可运行任务进行排序。switches列指示总切换次数(非自愿或自愿),prio指的是进程优先级。wait-time值指示任务等待调度的时间量。最后,sum-exec和sum-sleep分别计算任务在处理器上运行或休眠的总时间(纳秒)。#cat /proc/sched_debug Sched Debug Version: v0.11, 6.4.0-150600.9-default #1 ktime : 23533900.395978 sched_clk : 23543587.726648 cpu_clk : 23533900.396165 jiffies : 4300775771 sched_clock_stable : 0 sysctl_sched .sysctl_sched_latency : 6.000000 .sysctl_sched_min_granularity : 2.000000 .sysctl_sched_wakeup_granularity : 2.500000 .sysctl_sched_child_runs_first : 0 .sysctl_sched_features : 154871 .sysctl_sched_tunable_scaling : 1 (logarithmic) cpu#0, 2666.762 MHz .nr_running : 1 .load : 1024 .nr_switches : 1918946 [...] cfs_rq[0]:/ .exec_clock : 170176.383770 .MIN_vruntime : 0.000001 .min_vruntime : 347375.854324 .max_vruntime : 0.000001 [...] rt_rq[0]:/ .rt_nr_running : 0 .rt_throttled : 0 .rt_time : 0.000000 .rt_runtime : 950.000000 dl_rq[0]: .dl_nr_running : 0 task PID tree-key switches prio wait-time [...] ------------------------------------------------------------------------ R cc1 63477 98876.717832 197 120 0.000000 .../proc/schedstat显示与当前运行队列相关的统计信息。还显示所有连接处理器上的 SMP 系统的域特定统计信息。由于输出格式不友好,请阅读
/usr/src/linux/Documentation/scheduler/sched-stats.txt的内容以获取更多信息。/proc/PID/sched显示 ID 为 PID 的进程的调度信息。
#cat /proc/$(pidof gdm)/sched gdm (744, #threads: 3) ------------------------------------------------------------------- se.exec_start : 8888.758381 se.vruntime : 6062.853815 se.sum_exec_runtime : 7.836043 se.statistics.wait_start : 0.000000 se.statistics.sleep_start : 8888.758381 se.statistics.block_start : 0.000000 se.statistics.sleep_max : 1965.987638 [...] se.avg.decay_count : 8477 policy : 0 prio : 120 clock-delta : 128 mm->numa_scan_seq : 0 numa_migrations, 0 numa_faults_memory, 0, 0, 1, 0, -1 numa_faults_memory, 1, 0, 0, 0, -1
要获得有关 Linux 内核任务调度的简明知识,您需要探索多个信息源。以下是一些
有关任务调度程序系统调用的描述,请参阅相关手册页(例如
man 2 sched_setaffinity)。可以在 https://www.inf.fu-berlin.de/lehre/SS01/OS/Lectures/Lecture08.pdf 中找到有关 Linux 调度程序策略和算法的有用讲座。
Robert Love 的《Linux Kernel Development》(ISBN-10: 0-672-32512-8)中提供了 Linux 进程调度的良好概述。请参阅 https://www.informit.com/articles/article.aspx?p=101760。
Daniel P. Bovet 和 Marco Cesati 的 Understanding the Linux Kernel(ISBN 978-0-596-00565-8)提供了 Linux 内核内部的全面概述。
有关任务调度程序的技术信息在
/usr/src/linux/Documentation/scheduler下的文件中。
要理解和调整内核的内存管理行为,首先需要了解它的工作方式以及它与其他子系统的协作方式。
内存管理子系统,也称为虚拟内存管理器,在下文中将称为“VM”。VM 的作用是管理整个内核和用户程序的物理内存 (RAM) 分配。它还负责为用户进程提供虚拟内存环境(通过带有 Linux 扩展的 POSIX API 管理)。最后,当内存不足时,VM 通过修剪缓存或交换出“匿名”内存来释放 RAM。
检查和调优 VM 时最重要的一点是了解其缓存是如何管理的。VM 缓存的基本目标是最大限度地减少交换和文件系统操作(包括网络文件系统)产生的 I/O 成本。这通过避免 I/O 或以更好的模式提交 I/O 来实现。
可用内存根据需要由这些缓存使用和填充。用于缓存和匿名内存的内存越多,缓存和交换操作就越有效。但是,如果遇到内存不足,缓存会被修剪或内存会被交换出。
对于特定的工作负载,可以做的第一件事是增加内存并减少必须修剪或交换内存的频率。第二件事是通过更改内核参数来更改缓存的管理方式。
最后,工作负载本身也应该进行检查和调优。如果允许应用程序运行更多的进程或线程,那么如果每个进程都在其自己的文件系统区域中操作,VM 缓存的效率可能会降低。内存开销也会增加。如果应用程序分配自己的缓冲区或缓存,更大的缓存意味着可用于 VM 缓存的内存更少。但是,更多的进程和线程可能意味着更多的机会来重叠和并行处理 I/O,并且可能更好地利用多个核心。需要通过实验才能获得最佳结果。
内存分配可以描述为“固定”(也称为“不可回收”)、“可回收”或“可交换”。
匿名内存倾向于程序堆和栈内存(例如,>malloc())。它是可回收的,特殊情况除外,例如 mlock 或没有可用的交换空间。匿名内存必须先写入交换区才能被回收。由于分配和访问模式,交换 I/O(页面换入和换出)往往比页面缓存 I/O 效率低。
文件数据的缓存。当从磁盘或网络读取文件时,内容存储在页面缓存中。如果页面缓存中的内容是最新的,则不需要磁盘或网络访问。tmpfs 和共享内存段计入页面缓存。
当写入文件时,新数据在写回磁盘或网络之前存储在页面缓存中(使其成为回写缓存)。当一个页面有尚未写回的新数据时,它被称为“脏”页面。未分类为脏页面的页面是“干净”页面。如果内存不足,可以通过简单地释放干净的页面缓存页面来回收它们。脏页面必须先变干净才能被回收。
这是一种用于块设备(例如,/dev/sda)的页面缓存。文件系统通常在访问其磁盘上的元数据结构(例如 inode 表、分配位图等)时使用缓冲区缓存。缓冲区缓存可以类似于页面缓存进行回收。
当应用程序写入文件时,页面缓存会变脏,缓冲区缓存也可能变脏。当脏内存量达到指定的字节数页面数(vm.dirty_background_bytes),或者当脏内存量达到总内存的特定比例(vm.dirty_background_ratio),或者当页面脏污时间超过指定时间(vm.dirty_expire_centisecs)时,内核会开始回写页面,从页面首先变脏的文件开始。后台字节和比例是互斥的,设置其中一个会覆盖另一个。刷入器线程在后台执行回写,并允许应用程序继续运行。如果 I/O 无法跟上应用程序脏污页面缓存的速度,并且脏数据达到关键设置(vm.dirty_bytes 或 vm.dirty_ratio),那么应用程序将开始被限制以防止脏数据超过此阈值。
VM 监视文件访问模式,并可能尝试执行预读。预读将尚未请求的页面从文件系统读取到页面缓存中。这样做是为了允许提交更少、更大的 I/O 请求(更高效)。并且为了使 I/O 流水线化(I/O 与应用程序同时执行)。
在 openSUSE Leap 15.6 上运行的应用程序可以比旧版本分配更多的内存。这是因为 glibc 在分配用户空间内存时改变了其默认行为。请参阅 https://gnu.ac.cn/s/libc/manual/html_node/Malloc-Tunable-Parameters.html 以获取这些参数的解释。
要恢复类似于旧版本的行为,应将 M_MMAP_THRESHOLD 设置为 128*1024。这可以通过应用程序的 mallopt() 调用,或者在运行应用程序之前设置 MALLOC_MMAP_THRESHOLD_ 环境变量来完成。
可回收的内核内存(上述缓存)在内存不足时会自动修剪。大多数其他内核内存无法轻易减少,而是内核工作负载的属性。
减少用户空间工作负载的要求可以减少内核内存使用(更少的进程,更少的打开文件和套接字等)
在调整 VM 时,应该理解某些更改需要时间才能影响工作负载并完全生效。如果工作负载全天变化,它在不同时间可能表现不同。在某些条件下增加吞吐量的更改可能在其他条件下降低吞吐量。
/proc/sys/vm/swappiness此控制用于定义内核相对于页面缓存和其他缓存交换出匿名内存的积极程度。增加该值会增加交换量。默认值为
60。交换 I/O 往往比其他 I/O 效率低得多。然而,某些页面缓存页面比使用较少的匿名内存访问更频繁。这里应该找到正确的平衡。
如果在减速期间观察到交换活动,则可能值得降低此参数。如果 I/O 活动很多且系统中页面缓存量相当小,或者有大量休眠应用程序正在运行,则增加此值可以提高性能。
交换出的数据越多,系统在需要时将数据交换回来所需的时间就越长。
/proc/sys/vm/vfs_cache_pressure此变量控制内核回收用于缓存 VFS 缓存的内存与页面缓存和交换的趋势。增加此值会提高 VFS 缓存的回收率。
除了通过实验,很难知道何时应该更改此值。
slabtop命令(procps软件包的一部分)显示了内核使用的顶部内存对象。vfs 缓存是“dentry”和“*_inode_cache”对象。如果这些对象相对于页面缓存消耗了大量内存,则可能值得尝试增加压力。也可能有助于减少交换。默认值为100。/proc/sys/vm/min_free_kbytes这控制了为特殊储备(包括“原子”分配(那些不能等待回收的分配))保留的内存量。通常不应降低此值,除非系统正在仔细调整内存使用(通常对嵌入式而非服务器应用程序有用)。如果日志中经常出现“页面分配失败”消息和堆栈跟踪,则可以增加 min_free_kbytes,直到错误消失。如果这些消息不频繁,则无需担心。默认值取决于 RAM 量。
/proc/sys/vm/watermark_scale_factor广义地说,空闲内存具有高、低和最小水位线。当达到低水位线时,
kswapd唤醒并在后台回收内存。它会保持唤醒状态,直到空闲内存达到高水位线。当达到最小水位线时,应用程序将停滞并回收内存。watermark_scale_factor定义了 kswapd 唤醒之前节点/系统中剩余的内存量,以及 kswapd 再次休眠之前需要有多少内存可用。单位是万分之一。默认值 10 意味着水位线之间的距离是节点/系统中可用内存的 0.1%。最大值为 1000,即内存的 10%。在直接回收中频繁停滞的工作负载,如
/proc/vmstat中的allocstall所记录,可能会从更改此参数中受益。同样,如果kswapd过早休眠,如kswapd_low_wmark_hit_quickly所记录,则可能表明为避免停滞而保留的页面数量过低。
自 openSUSE Leap 10 以来,回写行为的一个重要变化是,对文件支持的 mmap() 内存的修改会立即被记录为脏内存(并受到回写)。而以前,它只会在取消映射、msync() 系统调用或内存压力过大时才受到回写。
一些应用程序不期望 mmap 修改受到这种回写行为的影响,并且性能可能会下降。增加回写比例和时间可以改善这种减速。
/proc/sys/vm/dirty_background_ratio这是空闲和可回收内存总量的百分比。当脏页面缓存量超过此百分比时,回写线程开始回写脏内存。默认值为
10(%)。/proc/sys/vm/dirty_background_bytes这包含后台内核刷新器线程开始回写时脏内存的数量。
dirty_background_bytes是dirty_background_ratio的对应项。如果设置了其中一个,另一个将自动读取为0。/proc/sys/vm/dirty_ratio与
dirty_background_ratio类似的百分比值。当超过此值时,想要写入页面缓存的应用程序会被阻塞,并等待内核后台刷新器线程减少脏内存量。默认值为20(%)。/proc/sys/vm/dirty_bytes此文件控制与
dirty_ratio相同的可调参数,但脏内存量以字节为单位,而不是可回收内存的百分比。由于dirty_ratio和dirty_bytes都控制相同的可调参数,因此如果设置了其中一个,另一个将自动读取为0。dirty_bytes允许的最小值为两页(以字节为单位);任何低于此限制的值都将被忽略,并保留旧配置。/proc/sys/vm/dirty_expire_centisecs在内存中脏污时间超过此间隔的数据将在下一次刷新线程唤醒时写出。过期是根据文件的 inode 的修改时间来衡量的。因此,当超过间隔时,来自同一文件的多个脏页面都将被写入。
dirty_background_ratio 和 dirty_ratio 共同决定页面缓存的回写行为。如果这些值增加,系统将保留更多的脏内存更长时间。允许系统中有更多的脏内存,通过避免回写 I/O 和提交更优化的 I/O 模式来提高吞吐量的机会增加。然而,当需要回收内存或在需要写回磁盘的数据完整性点(“同步点”)时,更多的脏内存可能会损害延迟。
/sys/block/<bdev>/queue/read_ahead_kb如果一个或多个进程正在顺序读取文件,内核会提前(预读)读取某些数据,以减少进程等待数据可用所需的时间。实际预读的数据量是根据 I/O 的顺序性动态计算的。此参数设置内核为单个文件预读的最大数据量。如果您观察到从文件进行的大型顺序读取不够快,您可以尝试增加此值。增加太多可能会导致预读颠簸,即用于预读的页面缓存在使用之前就被回收,或者因为大量无用 I/O 而导致减速。默认值为
512(KB)。
透明大页 (THP) 提供了一种动态分配大页的方法,既可以通过进程按需分配,也可以通过 khugepaged 内核线程延迟分配。这种方法与使用 hugetlbfs 手动管理其分配和使用不同。具有连续内存访问模式的工作负载可以从 THP 中受益匪浅。当运行具有连续内存访问模式的合成工作负载时,可以观察到页错误减少 1000 倍。
在某些情况下,THP 可能不理想。由于过多的内存使用,具有稀疏内存访问模式的工作负载在 THP 下可能会表现不佳。例如,在故障时可能会使用 2 MB 内存而不是每个故障 4 KB,最终导致过早的页面回收。
THP 的行为可以通过 transparent_hugepage= 内核参数或通过 sysfs 进行配置。例如,可以通过添加内核参数 transparent_hugepage=never、重建 grub2 配置并重新启动来禁用它。使用以下命令验证 THP 是否已禁用
# cat /sys/kernel/mm/transparent_hugepage/enabled
always madvise [never]如果禁用,值 never 将显示在方括号中,如上例所示。值 always 在故障时强制尝试并使用 THP,如果分配失败则延迟到 khugepaged。值 madvise 将仅为应用程序明确指定的地址空间分配 THP。
/sys/kernel/mm/transparent_hugepage/defrag此参数控制应用程序在分配 THP 时投入的精力。值
always是支持 THP 的 openSUSE 42.1 及更早版本的默认值。如果 THP 不可用,应用程序会尝试对内存进行碎片整理。如果内存碎片化且 THP 不可用,它可能会导致应用程序出现大量停顿。值
madvise意味着只有当应用程序明确请求时,THP 分配请求才会进行碎片整理。这是 openSUSE 42.2 及更高版本的默认值。defer仅在 openSUSE 42.2 及更高版本中可用。如果 THP 不可用,应用程序将回退到使用小页。它会唤醒kswapd和kcompactd内核线程以在后台碎片整理内存,然后khugepaged将在稍后分配 THP。最后一个选项
never在 THP 不可用时使用小页,但不会采取其他操作。
当 transparent_hugepage 设置为 always 或 madvise 时,khugepaged 会自动启动,当设置为 never 时,它会自动关闭。通常,它以低频率运行,但其行为可以调整。
/sys/kernel/mm/transparent_hugepage/khugepaged/defrag值 0 将禁用
khugepaged,即使在故障时仍可能使用 THP。这对于受益于 THP 但不能容忍khugepaged尝试更新应用程序内存使用时出现停顿的延迟敏感型应用程序可能很重要。/sys/kernel/mm/transparent_hugepage/khugepaged/pages_to_scan此参数控制
khugepaged在单次扫描中扫描多少页面。扫描识别可以重新分配为 THP 的小页面。增加此值将以 CPU 使用率为代价更快地在后台分配 THP。/sys/kernel/mm/transparent_hugepage/khugepaged/scan_sleep_millisecskhugepaged在每次通过后会休眠一段由该参数指定的时间,以限制 CPU 使用量。减少此值会以 CPU 使用量为代价更快地在后台分配 THP。值为 0 将强制持续扫描。/sys/kernel/mm/transparent_hugepage/khugepaged/alloc_sleep_millisecs此参数控制
khugepaged在未能分配后台 THP 时休眠多长时间,等待kswapd和kcompactd采取行动。
khugepaged 的其余参数很少用于性能调优,但已在 /usr/src/linux/Documentation/vm/transhuge.txt 中完整记录。
一些有助于监控 VM 行为的简单工具
vmstat:此工具提供了 VM 正在做什么的良好概述。详情请参阅第 2.1.1 节,“
vmstat”。/proc/meminfo:此文件详细介绍了内存的使用位置。详情请参阅第 2.4.2 节,“详细内存使用情况:/proc/meminfo”。slabtop:此工具提供有关内核 slab 内存使用的详细信息。buffer_head、dentry、inode_cache、ext3_inode_cache 等是主要缓存。此命令随procps包提供。/proc/vmstat:此文件详细介绍了内部 VM 行为。其中包含的信息是特定于实现的,并且可能并非总是可用。一些信息在/proc/meminfo中重复,其他信息可以通过实用程序以友好的方式呈现。为了获得最大效用,需要长时间监视此文件以观察变化率。最重要且难以从其他来源获取的信息如下pgscan_kswapd_*, pgsteal_kswapd_*这些分别报告系统启动以来
kswapd扫描和回收的页面数量。这些值之间的比率可以解释为回收效率,低效率意味着系统难以回收内存并可能发生颠簸。这里的轻微活动通常无需担心。pgscan_direct_*, pgsteal_direct_*这些分别报告应用程序直接扫描和回收的页面数量。这与
allocstall计数器的增加相关。这比kswapd活动更严重,因为这些事件表明进程正在停滞。这里的严重活动与kswapd以及高速率的pgpgin、pgpout和/或高速率的pswapin或pswpout相结合,是系统严重颠簸的迹象。可以使用跟踪点获取更详细的信息。
thp_fault_alloc, thp_fault_fallback这些计数器对应于应用程序直接分配的 THP 数量,以及 THP 不可用而使用小页面的次数。通常,高回退率是无害的,除非应用程序对 TLB 压力敏感。
thp_collapse_alloc, thp_collapse_alloc_failed这些计数器对应于
khugepaged分配的 THP 数量,以及 THP 不可用而使用小页面的次数。高回退率意味着系统碎片化,并且即使应用程序的内存使用允许,THP 也没有被使用。这仅对对 TLB 压力敏感的应用程序来说是个问题。compact_*_scanned, compact_stall, compact_fail, compact_success当启用 THP 且系统碎片化时,这些计数器可能会增加。
compact_stall在应用程序分配 THP 停滞时递增。其余计数器计算已扫描的页面数,成功或失败的碎片整理事件数。
网络子系统复杂,其调优高度依赖于系统使用场景以及外部因素,例如网络中的软件客户端或硬件组件(交换机、路由器或网关)。Linux 内核更注重可靠性和低延迟,而不是低开销和高吞吐量。其他设置可能意味着较低的安全性,但更好的性能。
大多数现代网络都基于 TCP/IP 协议和用于通信的套接字接口;有关 TCP/IP 的更多信息,请参阅《参考》一书,第 13 章“基本网络”。Linux 内核通过套接字接口接收或发送数据时使用套接字缓冲区。这些内核套接字缓冲区是可调的。
重要:TCP 自动调优
自内核版本 2.6.17 以来,已存在具有 4 MB 最大缓冲区大小的完整自动调优功能。这意味着手动调优不会显著提高网络性能。通常最好不要触碰以下变量,或者至少仔细检查调优工作的结果。
如果您从较旧的内核更新,建议删除手动 TCP 调优,以支持自动调优功能。
/proc 文件系统中的特殊文件可以修改内核套接字缓冲区的大小和行为;有关 /proc 文件系统的一般信息,请参阅第 2.6 节,“/proc 文件系统”。查找与网络相关的文件在
/proc/sys/net/core /proc/sys/net/ipv4 /proc/sys/net/ipv6
一般的 net 变量在内核文档 (linux/Documentation/sysctl/net.txt) 中有解释。特殊的 ipv4 变量在 linux/Documentation/networking/ip-sysctl.txt 和 linux/Documentation/networking/ipvs-sysctl.txt 中有解释。
在 /proc 文件系统中,例如,可以为所有协议设置最大套接字接收缓冲区和最大套接字发送缓冲区,或者只为 TCP 协议(在 ipv4 中)设置这两个选项,从而覆盖所有协议(在 core 中)的设置。
/proc/sys/net/ipv4/tcp_moderate_rcvbuf如果
/proc/sys/net/ipv4/tcp_moderate_rcvbuf设置为1,则自动调优处于活动状态,并且缓冲区大小会动态调整。/proc/sys/net/ipv4/tcp_rmem这三个值设置了每个连接内存接收缓冲区的最小、初始和最大大小。它们定义了实际内存使用量,而不仅仅是 TCP 窗口大小。
/proc/sys/net/ipv4/tcp_wmem与
tcp_rmem相同,但用于每个连接的内存发送缓冲区。/proc/sys/net/core/rmem_max用于限制应用程序可以请求的最大接收缓冲区大小。
/proc/sys/net/core/wmem_max用于限制应用程序可以请求的最大发送缓冲区大小。
通过 /proc 可以禁用您不需要的 TCP 功能(所有 TCP 功能默认都已启用)。例如,检查以下文件
/proc/sys/net/ipv4/tcp_timestampsTCP 时间戳在 RFC1323 中定义。
/proc/sys/net/ipv4/tcp_window_scalingTCP 窗口缩放也在 RFC1323 中定义。
/proc/sys/net/ipv4/tcp_sack选择性确认 (SACKS)。
使用 sysctl 读取或写入 /proc 文件系统的变量。sysctl 比 cat(用于读取)和 echo(用于写入)更可取,因为它也从 /etc/sysctl.conf 读取设置,因此这些设置在重新启动后能可靠地保存。使用 sysctl,您可以轻松读取所有变量及其值;以 root 身份使用以下命令列出与 TCP 相关的设置
>sudosysctl -a | grep tcp
注意:调优网络变量的副作用
调优网络变量可能会影响其他系统资源,例如 CPU 或内存使用。
在开始网络调优之前,隔离网络瓶颈和网络流量模式非常重要。有一些工具可以帮助您检测这些瓶颈。
以下工具可以帮助分析您的网络流量:netstat、tcpdump 和 wireshark。Wireshark 是一个网络流量分析器。
Linux 防火墙和伪装功能由 Netfilter 内核模块提供。这是一个高度可配置的基于规则的框架。如果规则与数据包匹配,Netfilter 会接受或拒绝它,或者根据地址转换等规则采取特殊操作(“目标”)。
Netfilter 可以考虑许多属性。因此,定义的规则越多,数据包处理所需的时间可能越长。此外,高级连接跟踪可能相当昂贵,从而降低整体网络性能。
当内核队列满时,所有新数据包都会被丢弃,导致现有连接失败。“故障开放”功能允许用户暂时禁用数据包检查,并在网络流量大的情况下保持连接。有关参考,请参阅 https://home.regit.org/netfilter-en/using-nfqueue-and-libnetfilter_queue/。
有关更多信息,请参阅 Netfilter 和 iptables 项目主页,https://www.netfilter.org
现代网络接口设备可以移动如此多的数据包,以至于主机可能成为实现最大性能的限制因素。为了跟上速度,系统必须能够将工作分配到多个 CPU 核心。
一些现代网络接口可以通过在硬件中实现多个传输队列和多个接收队列来帮助将工作分配到多个 CPU 核心。然而,其他接口只配备一个队列,驱动程序必须在单个串行流中处理所有传入的数据包。为了解决这个问题,操作系统必须“并行化”流以将工作分配到多个 CPU。在 openSUSE Leap 上,这是通过接收数据包转向 (RPS) 完成的。RPS 也可以在虚拟环境中使用。
RPS 使用 IP 地址和端口号为每个数据流创建一个唯一的哈希。使用此哈希可确保将同一数据流的数据包发送到同一 CPU,这有助于提高性能。
RPS 是按网络设备接收队列和接口配置的。配置文件名符合以下方案
/sys/class/net/<device>/queues/<rx-queue>/rps_cpus
<device> 代表网络设备,例如 eth0、eth1。<rx-queue> 代表接收队列,例如 rx-0、rx-1。
如果网络接口硬件只支持单个接收队列,则只存在 rx-0。如果支持多个接收队列,则每个接收队列都有一个 rx-N 目录。
这些配置文件包含一个逗号分隔的 CPU 位图列表。默认情况下,所有位都设置为 0。在此设置下,RPS 被禁用,因此处理中断的 CPU 也处理数据包队列。
要启用 RPS 并启用特定的 CPU 来处理接口接收队列的数据包,请将其在位图中的位置值设置为 1。例如,要启用 CPU 0-3 处理 eth0 第一个接收队列的数据包,请将位位置 0-3 设置为二进制的 1:00001111。然后需要将此表示转换为十六进制——在本例中结果为 F。使用以下命令设置此十六进制值
>sudoecho "f" > /sys/class/net/eth0/queues/rx-0/rps_cpus
如果你想启用 CPU 8-15
1111 1111 0000 0000 (binary) 15 15 0 0 (decimal) F F 0 0 (hex)
设置十六进制值 ff00 的命令将是
>sudoecho "ff00" > /sys/class/net/eth0/queues/rx-0/rps_cpus
在 NUMA 机器上,通过将 RPS 配置为使用与接口接收队列中断位于同一 NUMA 节点上的 CPU,可以实现最佳性能。
在非 NUMA 机器上,可以使用所有 CPU。如果中断率很高,排除处理网络接口的 CPU 可以提高性能。用于网络接口的 CPU 可以从 /proc/interrupts 中确定。例如
>sudocat /proc/interrupts CPU0 CPU1 CPU2 CPU3 ... 51: 113915241 0 0 0 Phys-fasteoi eth0 ...
在这种情况下,CPU 0是唯一处理eth0中断的CPU,因为只有CPU0包含非零值。
在x86和AMD64/Intel 64平台上,irqbalance可用于在CPU之间分配硬件中断。有关详细信息,请参阅man 1 irqbalance。
- 17 跟踪工具
openSUSE Leap 附带了多种工具,可帮助您获取有关系统的有用信息。您可以将这些信息用于不同的目的。例如,调试和查找程序中的问题,发现导致性能下降的地方,或者跟踪正在运行的进程以找出它正在做什么...
- 18 Kexec 和 Kdump
Kexec 是一种从当前运行的内核启动到另一个内核的工具。您可以执行更快的系统重新启动,而无需任何硬件初始化。您还可以准备系统启动到另一个内核,如果系统崩溃。
- 19 使用
systemd-coredump调试应用程序崩溃 systemd-coredump 收集并显示核心转储,用于分析应用程序崩溃。核心转储包含进程终止时内存的图像。默认情况下,当进程崩溃(或属于应用程序的所有进程)时,它会将核心转储存储在 /var/lib/systemd...
openSUSE Leap 附带了多种工具,可帮助您获取有关系统的有用信息。您可以将这些信息用于不同的目的。例如,调试和查找程序中的问题,发现导致性能下降的地方,或者跟踪正在运行的进程以找出它使用了哪些系统资源。
注意:跟踪和对性能的影响
当监视正在运行的进程的系统或库调用时,进程的性能会严重下降。建议您仅在需要收集数据的时间内使用跟踪工具。
strace 命令跟踪进程的系统调用和进程接收到的信号。strace 可以运行一个新命令并跟踪其系统调用,或者您可以将strace附加到已在运行的命令。命令输出的每一行都包含系统调用名称,后跟括号中的参数及其返回值。
要运行新命令并开始跟踪其系统调用,请像往常一样输入要监视的命令,并在命令行开头添加strace
> strace ls
execve("/bin/ls", ["ls"], [/* 52 vars */]) = 0
brk(0) = 0x618000
mmap(NULL, 4096, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) \
= 0x7f9848667000
mmap(NULL, 4096, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) \
= 0x7f9848666000
access("/etc/ld.so.preload", R_OK) = -1 ENOENT \
(No such file or directory)
open("/etc/ld.so.cache", O_RDONLY) = 3
fstat(3, {st_mode=S_IFREG|0644, st_size=200411, ...}) = 0
mmap(NULL, 200411, PROT_READ, MAP_PRIVATE, 3, 0) = 0x7f9848635000
close(3) = 0
open("/lib64/librt.so.1", O_RDONLY) = 3
[...]
mmap(NULL, 4096, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) \
= 0x7fd780f79000
write(1, "Desktop\nDocuments\nbin\ninst-sys\n", 31Desktop
Documents
bin
inst-sys
) = 31
close(1) = 0
munmap(0x7fd780f79000, 4096) = 0
close(2) = 0
exit_group(0) = ?要将strace附加到已在运行的进程,您需要使用要监视的进程的进程ID (PID)指定-p
> strace -p `pidof cron`
Process 1261 attached
restart_syscall(<... resuming interrupted call ...>) = 0
stat("/etc/localtime", {st_mode=S_IFREG|0644, st_size=2309, ...}) = 0
select(5, [4], NULL, NULL, {0, 0}) = 0 (Timeout)
socket(PF_LOCAL, SOCK_STREAM|SOCK_CLOEXEC|SOCK_NONBLOCK, 0) = 5
connect(5, {sa_family=AF_LOCAL, sun_path="/var/run/nscd/socket"}, 110) = 0
sendto(5, "\2\0\0\0\0\0\0\0\5\0\0\0root\0", 17, MSG_NOSIGNAL, NULL, 0) = 17
poll([{fd=5, events=POLLIN|POLLERR|POLLHUP}], 1, 5000) = 1 ([{fd=5, revents=POLLIN|POLLHUP}])
read(5, "\2\0\0\0\1\0\0\0\5\0\0\0\2\0\0\0\0\0\0\0\0\0\0\0\5\0\0\0\6\0\0\0"..., 36) = 36
read(5, "root\0x\0root\0/root\0/bin/bash\0", 28) = 28
close(5) = 0
rt_sigprocmask(SIG_BLOCK, [CHLD], [], 8) = 0
rt_sigaction(SIGCHLD, NULL, {0x7f772b9ea890, [], SA_RESTORER|SA_RESTART, 0x7f772adf7880}, 8) = 0
rt_sigprocmask(SIG_SETMASK, [], NULL, 8) = 0
nanosleep({60, 0}, 0x7fff87d8c580) = 0
stat("/etc/localtime", {st_mode=S_IFREG|0644, st_size=2309, ...}) = 0
select(5, [4], NULL, NULL, {0, 0}) = 0 (Timeout)
socket(PF_LOCAL, SOCK_STREAM|SOCK_CLOEXEC|SOCK_NONBLOCK, 0) = 5
connect(5, {sa_family=AF_LOCAL, sun_path="/var/run/nscd/socket"}, 110) = 0
sendto(5, "\2\0\0\0\0\0\0\0\5\0\0\0root\0", 17, MSG_NOSIGNAL, NULL, 0) = 17
poll([{fd=5, events=POLLIN|POLLERR|POLLHUP}], 1, 5000) = 1 ([{fd=5, revents=POLLIN|POLLHUP}])
read(5, "\2\0\0\0\1\0\0\0\5\0\0\0\2\0\0\0\0\0\0\0\0\0\0\0\5\0\0\0\6\0\0\0"..., 36) = 36
read(5, "root\0x\0root\0/root\0/bin/bash\0", 28) = 28
close(5)
[...]-e选项支持多个子选项和参数。例如,要跟踪所有打开或写入特定文件的尝试,请使用以下命令
> strace -e trace=open,write ls ~
open("/etc/ld.so.cache", O_RDONLY) = 3
open("/lib64/librt.so.1", O_RDONLY) = 3
open("/lib64/libselinux.so.1", O_RDONLY) = 3
open("/lib64/libacl.so.1", O_RDONLY) = 3
open("/lib64/libc.so.6", O_RDONLY) = 3
open("/lib64/libpthread.so.0", O_RDONLY) = 3
[...]
open("/usr/lib/locale/cs_CZ.utf8/LC_CTYPE", O_RDONLY) = 3
open(".", O_RDONLY|O_NONBLOCK|O_DIRECTORY|O_CLOEXEC) = 3
write(1, "addressbook.db.bak\nbin\ncxoffice\n"..., 311) = 311要仅跟踪网络相关的系统调用,请使用-e trace=network
> strace -e trace=network -p 26520
Process 26520 attached - interrupt to quit
socket(PF_NETLINK, SOCK_RAW, 0) = 50
bind(50, {sa_family=AF_NETLINK, pid=0, groups=00000000}, 12) = 0
getsockname(50, {sa_family=AF_NETLINK, pid=26520, groups=00000000}, \
[12]) = 0
sendto(50, "\24\0\0\0\26\0\1\3~p\315K\0\0\0\0\0\0\0\0", 20, 0,
{sa_family=AF_NETLINK, pid=0, groups=00000000}, 12) = 20
[...]-c计算内核在每个系统调用上花费的时间
> strace -c find /etc -name xorg.conf
/etc/X11/xorg.conf
% time seconds usecs/call calls errors syscall
------ ----------- ----------- --------- --------- ----------------
32.38 0.000181 181 1 execve
22.00 0.000123 0 576 getdents64
19.50 0.000109 0 917 31 open
19.14 0.000107 0 888 close
4.11 0.000023 2 10 mprotect
0.00 0.000000 0 1 write
[...]
0.00 0.000000 0 1 getrlimit
0.00 0.000000 0 1 arch_prctl
0.00 0.000000 0 3 1 futex
0.00 0.000000 0 1 set_tid_address
0.00 0.000000 0 4 fadvise64
0.00 0.000000 0 1 set_robust_list
------ ----------- ----------- --------- --------- ----------------
100.00 0.000559 3633 33 total要跟踪进程的所有子进程,请使用-f
> strace -f systemctl status apache2.service
execve("/usr/bin/systemctl", ["systemctl", "status", "apache2.service"], \
0x7ffea44a3318 /* 56 vars */) = 0
brk(NULL) = 0x5560f664a000
[...]
mmap(NULL, 8192, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f98c58a5000
mmap(NULL, 4420544, PROT_READ|PROT_EXEC, MAP_PRIVATE|MAP_DENYWRITE, 3, 0) = 0x7f98c524a000
mprotect(0x7f98c53f4000, 2097152, PROT_NONE) = 0
[...]
[pid 9130] read(0, "\342\227\217 apache2.service - The Apache"..., 8192) = 165
[pid 9130] read(0, "", 8027) = 0
● apache2.service - The Apache Webserver227\217 apache2.service - Th"..., 193
Loaded: loaded (/usr/lib/systemd/system/apache2.service; disabled; vendor preset: disabled)
Active: inactive (dead)
) = 193
[pid 9130] ioctl(3, SNDCTL_TMR_STOP or TCSETSW, {B38400 opost isig icanon echo ...}) = 0
[pid 9130] exit_group(0) = ?
[pid 9130] +++ exited with 0 +++
<... waitid resumed>{si_signo=SIGCHLD, si_code=CLD_EXITED, si_pid=9130, \
si_uid=0, si_status=0, si_utime=0, si_stime=0}, WEXITED, NULL) = 0
--- SIGCHLD {si_signo=SIGCHLD, si_code=CLD_EXITED, si_pid=9130, si_uid=0, \
si_status=0, si_utime=0, si_stime=0} ---
exit_group(3) = ?
+++ exited with 3 +++如果您需要分析strace的输出,并且输出消息太长而无法直接在控制台窗口中检查,请使用-o。在这种情况下,不必要的消息(例如有关附加和分离进程的信息)将被抑制。您还可以使用-q抑制这些消息(通常打印到标准输出)。要在每行系统调用开头添加时间戳,请使用-t
> strace -t -o strace_sleep.txt sleep 1; more strace_sleep.txt
08:44:06 execve("/bin/sleep", ["sleep", "1"], [/* 81 vars */]) = 0
08:44:06 brk(0) = 0x606000
08:44:06 mmap(NULL, 4096, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, \
-1, 0) = 0x7f8e78cc5000
[...]
08:44:06 close(3) = 0
08:44:06 nanosleep({1, 0}, NULL) = 0
08:44:07 close(1) = 0
08:44:07 close(2) = 0
08:44:07 exit_group(0) = ?strace 的行为和输出格式可以控制。有关更多信息,请参阅相关手册页 (man 1 strace)。
ltrace 跟踪进程的动态库调用。它的用法与strace类似,并且它们的大多数参数具有相似或相同的含义。默认情况下,ltrace使用/etc/ltrace.conf或~/.ltrace.conf配置文件。但是,您可以使用-F CONFIG_FILE选项指定替代文件。
除了库调用之外,带有-S选项的ltrace也可以跟踪系统调用
> ltrace -S -o ltrace_find.txt find /etc -name \
xorg.conf; more ltrace_find.txt
SYS_brk(NULL) = 0x00628000
SYS_mmap(0, 4096, 3, 34, 0xffffffff) = 0x7f1327ea1000
SYS_mmap(0, 4096, 3, 34, 0xffffffff) = 0x7f1327ea0000
[...]
fnmatch("xorg.conf", "xorg.conf", 0) = 0
free(0x0062db80) = <void>
__errno_location() = 0x7f1327e5d698
__ctype_get_mb_cur_max(0x7fff25227af0, 8192, 0x62e020, -1, 0) = 6
__ctype_get_mb_cur_max(0x7fff25227af0, 18, 0x7f1327e5d6f0, 0x7fff25227af0,
0x62e031) = 6
__fprintf_chk(0x7f1327821780, 1, 0x420cf7, 0x7fff25227af0, 0x62e031
<unfinished ...>
SYS_fstat(1, 0x7fff25227230) = 0
SYS_mmap(0, 4096, 3, 34, 0xffffffff) = 0x7f1327e72000
SYS_write(1, "/etc/X11/xorg.conf\n", 19) = 19
[...]您可以使用-e选项更改跟踪事件的类型。以下示例打印与fnmatch和strlen函数相关的库调用
> ltrace -e fnmatch,strlen find /etc -name xorg.conf
[...]
fnmatch("xorg.conf", "xorg.conf", 0) = 0
strlen("Xresources") = 10
strlen("Xresources") = 10
strlen("Xresources") = 10
fnmatch("xorg.conf", "Xresources", 0) = 1
strlen("xorg.conf.install") = 17
[...]要仅显示特定库中包含的符号,请使用-l /path/to/library
> ltrace -l /lib64/librt.so.1 sleep 1
clock_gettime(1, 0x7fff4b5c34d0, 0, 0, 0) = 0
clock_gettime(1, 0x7fff4b5c34c0, 0xffffffffff600180, -1, 0) = 0
+++ exited (status 0) +++您可以通过使用-n NUM_OF_SPACES将每个嵌套调用缩进指定数量的空格来使输出更具可读性。
Valgrind 是一套用于调试和分析程序的工具,使它们运行更快、错误更少。Valgrind 可以检测与内存管理和线程相关的问题,也可以作为构建新调试工具的框架。众所周知,该工具可能会产生高开销,例如,导致运行时间更长或在基于时间的并发工作负载下改变正常的程序行为。
Valgrind 的主要优点是它适用于现有的已编译可执行文件。您无需重新编译或修改程序即可使用它。像这样运行 Valgrind
valgrind VALGRIND_OPTIONS your-prog YOUR-PROGRAM-OPTIONS
Valgrind 包含多个工具,每个工具都提供特定的功能。本节中的信息是通用的,并且无论使用哪种工具都有效。最重要的配置选项是--tool。此选项告诉Valgrind要运行哪个工具。如果您省略此选项,则默认选择memcheck。例如,要使用Valgrind的memcheck工具运行find ~ -name .bashrc,请在命令行中输入以下内容
valgrind --tool=memcheck find ~ -name .bashrc
以下是标准 Valgrind 工具的列表及其简要说明
memcheck检测内存错误。它帮助您调整程序以使其行为正确。
cachegrind配置文件缓存预测。它帮助您调整程序以运行得更快。
callgrind与
cachegrind类似,但也会收集额外的缓存分析信息。exp-drd检测线程错误。它帮助您调整多线程程序以使其行为正确。
helgrind另一个线程错误检测器。与
exp-drd类似,但使用不同的技术进行问题分析。massif堆分析器。堆是用于动态内存分配的内存区域。此工具可帮助您调整程序以使用更少的内存。
lackey一个示例工具,演示了基本的检测。
Valgrind 可以在启动时读取选项。Valgrind 检查三个地方
运行 Valgrind 的用户主目录中的文件
.valgrindrc。环境变量
$VALGRIND_OPTSValgrind 运行的当前目录中的文件
.valgrindrc。
这些资源将按此顺序精确解析,后给出的选项优先于先前处理的选项。特定 Valgrind 工具的选项必须以工具名称和冒号为前缀。例如,如果您希望cachegrind始终将配置文件数据写入/tmp/cachegrind_PID.log,请将以下行添加到主目录中的.valgrindrc文件
--cachegrind:cachegrind-out-file=/tmp/cachegrind_%p.log
Valgrind 在可执行文件启动之前控制它。它从可执行文件和相关的共享库中读取调试信息。可执行文件的代码被重定向到所选的 Valgrind 工具,工具会添加自己的代码来处理其调试。然后代码被交还给 Valgrind 核心,执行继续。
例如,memcheck添加其代码,该代码检查每个内存访问。因此,程序运行速度比在本机执行环境中慢得多。
Valgrind 模拟程序中的每条指令。因此,它不仅检查程序代码,还检查所有相关库(包括 C 库)、用于图形环境的库等。如果您尝试使用 Valgrind 检测错误,它还会检测相关库(如 C、X11 或 Gtk 库)中的错误。因为您不需要经常处理所有这些错误,所以 Valgrind 可以选择性地将这些错误消息抑制到抑制文件中。--gen-suppressions=yes告诉 Valgrind 报告这些抑制,您可以将其复制到文件中。
您应该提供一个真实的可执行文件(机器代码)作为 Valgrind 参数。如果您的应用程序例如从 shell 或 Perl 脚本运行,您可能会错误地收到与/bin/sh(或/usr/bin/perl)相关的错误报告。在这种情况下,您可以使用--trace-children=yes来解决此问题。但是,使用可执行文件本身可以避免在此问题上的任何混淆。
在其运行时,Valgrind 会报告包含详细错误和重要事件的消息。以下示例解释了这些消息
> valgrind --tool=memcheck find ~ -name .bashrc
[...]
==6558== Conditional jump or move depends on uninitialised value(s)
==6558== at 0x400AE79: _dl_relocate_object (in /lib64/ld-2.11.1.so)
==6558== by 0x4003868: dl_main (in /lib64/ld-2.11.1.so)
[...]
==6558== Conditional jump or move depends on uninitialised value(s)
==6558== at 0x400AE82: _dl_relocate_object (in /lib64/ld-2.11.1.so)
==6558== by 0x4003868: dl_main (in /lib64/ld-2.11.1.so)
[...]
==6558== ERROR SUMMARY: 2 errors from 2 contexts (suppressed: 0 from 0)
==6558== malloc/free: in use at exit: 2,228 bytes in 8 blocks.
==6558== malloc/free: 235 allocs, 227 frees, 489,675 bytes allocated.
==6558== For counts of detected errors, rerun with: -v
==6558== searching for pointers to 8 not-freed blocks.
==6558== checked 122,584 bytes.
==6558==
==6558== LEAK SUMMARY:
==6558== definitely lost: 0 bytes in 0 blocks.
==6558== possibly lost: 0 bytes in 0 blocks.
==6558== still reachable: 2,228 bytes in 8 blocks.
==6558== suppressed: 0 bytes in 0 blocks.
==6558== Rerun with --leak-check=full to see details of leaked memory.==6558== 引入了 Valgrind 的消息,并包含进程 ID 号 (PID)。您可以轻松区分 Valgrind 的消息与程序本身的输出,并决定哪些消息属于特定进程。
要使 Valgrind 的消息更详细,请使用-v甚至-v -v。
您可以让 Valgrind 将其消息发送到三个不同的位置
默认情况下,Valgrind 将其消息发送到文件描述符 2,即标准错误输出。您可以使用
--log-fd=FILE_DESCRIPTOR_NUMBER选项告诉 Valgrind 将其消息发送到任何其他文件描述符。第二种,也是更有用的方法,是使用
--log-file=FILENAME将Valgrind的消息发送到文件。此选项接受多个变量,例如,%p被替换为当前分析进程的PID。%q{env_var}被替换为相关env_var环境变量的值。以下示例检查Apache Web服务器重启期间可能出现的内存错误,同时跟踪子进程并将详细的Valgrind消息写入以当前进程PID区分的单独文件
>valgrind -v --tool=memcheck --trace-children=yes \ --log-file=valgrind_pid_%p.log systemctl restart apache2.service此过程在测试系统中创建了52个日志文件,耗时75秒,而不是通常运行不带Valgrind的
sudo systemctl restart apache2.service所需的7秒,大约多了10倍。>ls -1 valgrind_pid_*log valgrind_pid_11780.log valgrind_pid_11782.log valgrind_pid_11783.log [...] valgrind_pid_11860.log valgrind_pid_11862.log valgrind_pid_11863.log您可能还希望通过网络发送 Valgrind 的消息。您需要使用
--log-socket=AA.BB.CC.DD:PORT_NUM选项指定网络套接字的aa.bb.cc.ddIP 地址和port_num端口号。如果您省略端口号,则使用 1500。如果远程机器上没有应用程序能够接收 Valgrind 的消息,那么将这些消息发送到网络套接字是无用的。这就是为什么 Valgrind 随附了一个简单的侦听器
valgrind-listener。它接受指定端口上的连接并将接收到的所有内容复制到标准输出。
Valgrind 会记住所有错误消息,如果它检测到新错误,则会将该错误与旧错误消息进行比较。这样 Valgrind 会检查重复的错误消息。如果发生重复错误,它会被记录但不会显示消息。此机制可防止您被数百万条重复错误淹没。
-v 选项会将所有报告的摘要(按总计数排序)添加到 Valgrind 执行输出的末尾。此外,如果 Valgrind 检测到 1000 个不同的错误或总共 10,000,000 个错误,它会停止收集错误。要取消此限制并查看所有错误消息,请使用--error-limit=no。
某些错误会导致其他错误。因此,请按照错误出现的顺序修复错误并持续重新检查程序。
有关所描述的跟踪工具的选项的完整列表,请参阅相应的手册页(
man 1 strace、man 1 ltrace和man 1 valgrind)。Valgrind 的高级用法超出了本文档的范围。它有详细的文档,请参阅Valgrind 用户手册。如果您需要 Valgrind 或其标准工具的用法和目的的更多高级信息,这些页面是不可或缺的。
Kexec 是一种从当前运行的内核启动到另一个内核的工具。您可以执行更快的系统重新启动,而无需任何硬件初始化。您还可以准备系统启动到另一个内核,如果系统崩溃。
使用 Kexec,您可以在不进行硬重启的情况下,将运行中的内核替换为另一个内核。该工具的用处有以下几个原因
更快的系统重启
如果您需要频繁重启系统,Kexec 可以为您节省大量时间。
避免不可靠的固件和硬件
计算机硬件复杂,系统启动期间可能会出现严重问题。您不能总是立即更换不可靠的硬件。Kexec 将内核启动到一个受控环境中,硬件已初始化。这样可以最大限度地降低系统启动失败的风险。
保存崩溃内核的转储
Kexec 保留物理内存的内容。在生产内核失败后,捕获内核(在保留内存范围内运行的额外内核)会保存失败内核的状态。保存的图像可以帮助您进行后续分析。
无需 GRUB 2 配置即可启动
当系统使用 Kexec 引导内核时,它会跳过引导加载程序阶段。正常的引导过程可能会因引导加载程序配置中的错误而失败。使用 Kexec,您不依赖于工作的引导加载程序配置。
要在openSUSE® Leap上使用Kexec加速重启或避免潜在的硬件问题,请确保安装了kexec-tools软件包。它包含一个名为kexec-bootloader的脚本,该脚本读取引导加载程序配置并使用与正常引导加载程序相同的内核选项运行Kexec。
要设置一个环境,以便在内核崩溃时帮助您获取调试信息,请确保安装了makedumpfile软件包。
在openSUSE Leap中使用Kdump的首选方法是通过YaST Kdump模块。要使用YaST模块,请确保安装了yast2-kdump软件包。
Kexec 最重要的组件是/sbin/kexec命令。您可以通过两种不同的方式使用 Kexec 加载内核
将内核加载到生产内核的地址空间以进行常规重启
#kexec-lKERNEL_IMAGE您稍后可以使用
kexec-e启动此内核。将内核加载到内存的保留区域
#kexec-pKERNEL_IMAGE当系统崩溃时,此内核会自动启动。
要在系统崩溃时引导另一个内核并保留生产内核的数据,您需要保留一个专用的系统内存区域。生产内核永远不会加载到此区域,因为它必须始终可用。它用于捕获内核,以便可以保留生产内核的内存页。
要保留该区域,请将选项crashkernel附加到生产内核的引导命令行。要确定crashkernel的必要值,请按照第18.4节,“计算crashkernel分配大小”中的说明进行操作。
这不是捕获内核的参数。捕获内核不使用 Kexec。
捕获内核加载到保留区域,等待内核崩溃。然后,Kdump 尝试调用捕获内核,因为生产内核在此阶段不再可靠。这意味着即使 Kdump 也可能失败。
要加载捕获内核,您需要包含内核引导参数。在大多数情况下,初始 RAM 文件系统用于引导。您可以使用--initrd=FILENAME指定它。使用--append=CMDLINE,您可以将选项附加到要引导的内核的命令行。
必须包含生产内核的命令行。您可以简单地使用--append="$(cat /proc/cmdline)"复制命令行,或使用--append="$(cat /proc/cmdline) more_options"添加更多选项。
例如,要加载/boot/vmlinuz-6.4.0-150600.9-default内核映像,并使用当前运行的生产内核的命令行和/boot/initrd文件,请运行以下命令
# kexec -l /boot/vmlinuz-6.4.0-150600.9-default \
--append="$(cat /proc/cmdline)" --initrd=/boot/initrd您可以随时卸载以前加载的内核。要卸载使用-l选项加载的内核,请使用kexec -u命令。要卸载使用-p选项加载的崩溃内核,请使用kexec -p -u命令。
要将 Kexec 与捕获内核一起使用,并以任何方式使用 Kdump,需要为捕获内核分配 RAM。分配大小取决于计算机预期的硬件配置,因此您需要指定它。
分配大小也取决于您计算机的硬件架构。请务必按照适用于您系统架构的步骤操作。
步骤 18.1: AMD64/Intel 64 上的分配大小 #
要找出计算机的基值,请运行以下命令
#kdumptoolcalibrate Total: 49074 Low: 72 High: 180 MinLow: 72 MaxLow: 3085 MinHigh: 0 MaxHigh: 45824所有值均以兆字节表示。
记下
Low和High的值。注意:
Low和High值的意义在 AMD64/Intel 64 计算机上,
High值表示所有可用内存的内存保留。Low值表示 DMA32 区域中的内存保留,即所有内存直到 4 GB 标记。SIZE_LOW是32位设备所需的内存量。内核为DMA32反弹缓冲区分配64M。如果您的服务器没有任何32位设备,那么使用默认的72M分配给
SIZE_LOW应该一切正常。NUMA机器可能是一个例外,这可能使得似乎需要更多的Low内存。Kdump内核可以以numa=off启动,以确保正常的内核分配不使用Low内存。根据连接到计算机的 LUN 内核路径(存储设备路径)数量,调整上一步中的
High值。可以使用以下公式计算合理的兆字节值SIZE_HIGH = RECOMMENDATION + (LUNs / 2)
此公式中使用以下参数
SIZE_HIGH。
High的最终值。RECOMMENDATION。
kdumptool calibrate建议的High值。LUNs。 您预计在计算机上创建的最大 LUN 内核路径数。排除多路径设备,因为它们会被忽略。要获取系统上可用的当前 LUN 数量,请运行以下命令
>cat /proc/scsi/scsi | grep Lun | wc -l
如果设备的驱动程序在 DMA32 区域中进行了许多保留,则
Low值也需要调整。但是,没有简单的公式可以计算这些值。因此,找到合适的尺寸可能是一个反复试验的过程。首先,使用
kdumptool calibrate推荐的Low值。现在需要将值设置在正确的位置。
- 如果您直接更改内核命令行
将以下内核选项附加到您的引导加载程序配置中
crashkernel=SIZE_HIGH,high crashkernel=SIZE_LOW,low
将占位符SIZE_HIGH和SIZE_LOW替换为上一步中的相应值,并附加字母
M(表示兆字节)。例如,以下是有效的
crashkernel=36M,high crashkernel=72M,low
- 如果您正在使用 YaST GUI
将设置为确定的
Low值。将设置为确定的
High值。- 如果您正在使用 YaST 命令行界面
使用以下命令
#yast kdump startup enable alloc_mem=LOW,HIGH将LOW替换为确定的
Low值。将HIGH替换为确定的HIGH值。
提示:在 IBM Z 上排除未使用和非活动的 CCW 设备
根据可用设备的数量,由crashkernel内核参数指定的计算内存量可能不足。您可以通过限制内核可见的设备数量来替代增加该值。这会降低crashkernel设置所需的内存量。
要忽略设备,您可以运行
cio_ignore工具来生成适当的节,以忽略除当前活动或正在使用的设备之外的所有设备。>sudocio_ignore -u -k cio_ignore=all,!da5d,!f500-f502当您运行
cio_ignore -u -k时,黑名单会立即激活并替换任何现有的黑名单。未使用的设备不会被清除,因此它们仍然会出现在通道子系统中。但是,添加新的通道设备(通过 z/VM 下的 CP ATTACH 或 LPAR 中的动态 I/O 配置更改)会将它们视为被阻止。为了防止这种情况,请先运行sudo cio_ignore -l保留原始设置,然后在运行cio_ignore -u -k后恢复到该状态。作为替代方案,将生成的节添加到常规内核引导参数中。现在将包含上述节的
cio_ignore内核参数添加到/etc/sysconfig/kdump中的KDUMP_CMDLINE_APPEND,例如KDUMP_COMMANDLINE_APPEND="cio_ignore=all,!da5d,!f500-f502"
通过重启
kdump来激活设置systemctl restart kdump.service
要使用 Kexec,请确保相应的服务已启用并正在运行
确保 Kexec 服务在系统启动时加载
>sudosystemctl enable kexec-load.service确保 Kexec 服务正在运行
>sudosystemctl start kexec-load.service
要验证您的 Kexec 环境是否正常工作,请尝试使用 Kexec 重启到新内核。确保当前没有用户登录,也没有重要的服务在系统上运行。然后运行以下命令
systemctl kexec
先前加载到旧内核地址空间的新内核会重写旧内核并立即获得控制权。它会显示通常的启动消息。当新内核启动时,它会跳过所有硬件和固件检查。请确保没有出现警告消息。
提示:将 Kexec 与 reboot 命令一起使用
要让reboot使用Kexec而不是执行常规重启,请运行以下命令
ln -s /usr/lib/systemd/system/kexec.target /etc/systemd/system/reboot.target
您可以随时通过删除etc/systemd/system/reboot.target来恢复此操作。
Kexec 常用于频繁重启。例如,如果运行硬件检测例程需要很长时间,或者启动不可靠。
当系统使用 Kexec 重新启动时,固件和引导加载程序不会被使用。您对引导加载程序配置所做的任何更改都将被忽略,直到计算机执行硬重新启动。
您可以使用 Kdump 保存内核转储。如果内核崩溃,将崩溃环境的内存映像复制到文件系统会很有用。然后,您可以调试转储文件以找到内核崩溃的原因。这称为“核心转储”。
Kdump 的工作原理与 Kexec 类似(请参阅第 18 章,“Kexec 和 Kdump”)。捕获内核在运行的生产内核崩溃后执行。不同之处在于 Kexec 用捕获内核替换生产内核。使用 Kdump,您仍然可以访问崩溃的生产内核的内存空间。您可以将崩溃内核的内存快照保存在 Kdump 内核的环境中。
提示:网络上的转储
在本地存储有限的环境中,您需要设置通过网络进行内核转储。Kdump 支持配置指定的网络接口并通过initrd将其启动。支持 LAN 和 VLAN 接口。使用 YaST 或/etc/sysconfig/kdump文件中的KDUMP_NETCONFIG选项指定网络接口和模式(DHCP 或静态)。
重要:Kdump 的目标文件系统必须在配置期间挂载
配置 Kdump 时,您可以指定保存转储图像的位置(默认值:/var/crash)。此位置必须在配置 Kdump 时挂载,否则配置将失败。
Kdump 从/etc/sysconfig/kdump文件读取其配置。为了确保 Kdump 在您的系统上正常工作,其默认配置就足够了。要使用默认设置运行 Kdump,请按照以下步骤操作
按照第18.4节,“计算
crashkernel分配大小”中的说明确定 Kdump 所需的内存量。请务必设置内核参数crashkernel。重启电脑。
启用 Kdump 服务
#systemctlenable kdump您可以编辑
/etc/sysconfig/kdump中的选项。阅读注释有助于您理解各个选项的含义。使用
sudo systemctl start kdump执行一次init脚本,或者重启系统。
在配置 Kdump 使用默认值后,检查它是否按预期工作。确保当前没有用户登录,并且系统上没有重要的服务正在运行。然后按照以下步骤操作
使用
systemctl isolate rescue.target切换到救援目标重启 Kdump 服务
#systemctlstart kdump除根文件系统外,卸载所有磁盘文件系统,命令为
#umount-a以只读模式重新挂载根文件系统
#mount-o remount,ro /通过
procfs接口调用魔术 SysRq 键来引发“内核崩溃”#echoc > /proc/sysrq-trigger
重要:内核转储的大小
KDUMP_KEEP_OLD_DUMPS选项控制保留的内核转储的数量(默认为 5)。不进行压缩的情况下,转储的大小可能达到物理内存或 RAM 的大小。请确保/var分区有足够的空间。
捕获内核启动,崩溃的内核内存快照保存到文件系统。KDUMP_SAVEDIR选项给出保存路径,默认为/var/crash。如果KDUMP_IMMEDIATE_REBOOT设置为yes,系统会自动重启生产内核。登录并检查转储是否已在/var/crash下创建。
要使用 YaST 配置 Kdump,您需要安装yast2-kdump软件包。然后,要么在的类别中启动模块,要么以root身份在命令行中输入yast2 kdump。
图 18.1: YaST Kdump 模块:启动页 #
在窗口中,选择。
首次打开窗口时,的值会自动生成。但这并不意味着它们总是足够的。要设置正确的值,请按照第18.4节,“计算crashkernel分配大小”中的说明进行操作。
重要:硬件更改后,请重新设置值
如果您在计算机上设置了 Kdump,之后决定更改其可用的 RAM 或硬盘数量,YaST 将继续显示和使用过时的内存值。
要解决此问题,请按照第18.4节,“计算crashkernel分配大小”中的说明重新确定所需的内存。然后手动在 YaST 中设置它。
单击左侧窗格中的,然后检查要包含在转储中的页面。您不需要包含以下内存内容即可调试内核问题
填充零的页面
缓存页面
用户数据页面
空闲页面
在窗口中,选择转储目标的类型和要保存转储的 URL。如果选择了网络协议(例如 FTP 或 SSH),则还需要输入相关的访问信息。
提示:与其他应用程序共享转储目录
可以为保存 Kdump 转储指定一个路径,其他应用程序也在此路径保存其转储。在清理旧转储文件时,Kdump 会安全地忽略其他应用程序的转储文件。
如果您希望 Kdump 通过电子邮件通知您其事件,请填写窗口信息,并在窗口中微调 Kdump 后使用确认您的更改。Kdump 现已配置完成。
转储文件通常包含敏感数据,应防止未经授权的泄露。为了允许通过不安全的网络传输此类数据,Kdump 可以使用 SSH 协议将转储文件保存到远程机器。
目标主机身份必须为 Kdump 所知。这需要确保敏感数据永远不会发送给冒名顶替者。当 Kdump 生成新的
initrd时,它会运行ssh-keygen -F TARGET_HOST来查询目标主机的身份。这仅在TARGET_HOST公钥已知的情况下才有效。实现这一点的简单方法是,在 Kdump 主机上以root身份与TARGET_HOST建立 SSH 连接。Kdump 必须能够向目标机器进行身份验证。目前仅支持公钥身份验证。默认情况下,Kdump 使用
root的私钥,但建议为 Kdump 制作一个单独的密钥。这可以使用ssh-keygen完成#ssh-keygen-f ~/.ssh/kdump_key当提示输入密码短语时按Enter键(即,不要使用任何密码短语)。
打开
/etc/sysconfig/kdump并将KDUMP_SSH_IDENTITY设置为kdump_key。如果文件不在~/.ssh下,您可以使用文件的完整路径。
设置 Kdump SSH 密钥以授权登录远程主机。
#ssh-copy-id-i ~/.ssh/kdump_key TARGET_HOST设置
KDUMP_SAVEDIR。有两种选择- 安全文件传输协议 (SFTP)
SFTP 是通过 SSH 传输文件的首选方法。目标主机必须启用 SFTP 子系统(openSUSE Leap 默认)。示例
KDUMP_SAVEDIR=sftp://TARGET_HOST/path/to/dumps
- 安全外壳协议 (SSH)
一些其他发行版使用 SSH 在目标主机上运行特定命令。openSUSE Leap 也可以使用这种方法。目标主机上的 Kdump 用户必须具有可以执行这些命令的登录 shell:
mkdir、dd和mv。示例KDUMP_SAVEDIR=ssh://TARGET_HOST/path/to/dumps
重启 Kdump 服务以使用新配置。
获取转储后,就可以分析它了。有几种选择。
分析转储的原始工具是 GDB。即使在最新的环境中也可以使用它,尽管它有一些缺点和限制
GDB并非专门用于调试内核转储。
GDB 不支持 32 位平台上的 ELF64 二进制文件。
GDB 不理解 ELF 转储以外的格式(它无法调试压缩转储)。
这就是为什么实现crash实用程序的原因。它分析崩溃转储并调试运行中的系统。它提供专门用于调试 Linux 内核的功能,更适合高级调试。
要调试 Linux 内核,也请安装其调试信息包。使用以下命令检查软件包是否已安装在您的系统上
>zypperse kernel |grepdebug
重要:包含调试信息的软件包的存储库
如果你已订阅系统的在线更新,你可以在 openSUSE Leap 15.6 相关的 *-Debuginfo-Updates 在线安装存储库中找到“debuginfo”包。使用 YaST 启用存储库。
要在生成转储的机器上使用crash打开捕获的转储,请使用如下命令
crash /boot/vmlinux-6.4.0-150600.9-default.gz \
/var/crash/2024-04-23-11\:17/vmcore第一个参数表示内核映像。第二个参数是 Kdump 捕获的转储文件。默认情况下,您可以在/var/crash下找到此文件。
提示:从内核崩溃转储中获取基本信息
openSUSE Leap 附带实用程序kdumpid(包含在同名软件包中),用于识别未知内核转储。它可用于提取基本信息,例如体系结构和内核发行版。它支持 lkcd、diskdump、Kdump 文件和 ELF 转储。当使用-v开关调用时,它会尝试提取额外信息,例如机器类型、内核横幅字符串和内核配置风格。
Linux 内核以可执行和可链接格式 (ELF) 提供。此文件名为vmlinux,直接在编译过程中生成。并非所有引导加载程序都支持 ELF 二进制文件,尤其是在 AMD64/Intel 64 架构上。openSUSE® Leap支持的不同架构存在以下解决方案。
SUSE 提供的 AMD64/Intel 64 内核软件包包含两个内核文件:vmlinuz和vmlinux.gz。
vmlinuz。 这是引导加载程序执行的文件。Linux 内核由两部分组成:内核本身 (
vmlinux) 和引导加载程序运行的设置代码。这两部分链接在一起以创建vmlinuz(注意区别:z与x相比)。在内核源树中,该文件名为
bzImage。vmlinux.gz。 这是一个压缩的 ELF 映像,可由crash和 GDB 使用。在 AMD64/Intel 64 上,引导加载程序本身从不使用 ELF 映像。因此,只提供了压缩版本。
POWER 上的yaboot引导加载程序也支持加载 ELF 镜像,但不支持压缩镜像。在 POWER 内核软件包中,有一个 ELF Linux 内核文件vmlinux。考虑到crash,这是最简单的架构。
如果您决定在另一台机器上分析转储,则必须检查计算机的体系结构和调试所需的文件。
您只能在运行相同架构的 Linux 系统的另一台计算机上分析转储。要检查兼容性,请在两台计算机上使用uname -i命令并比较输出。
如果您要在另一台计算机上分析转储,还需要kernel和kernel debug软件包中相应的必需文件。
将内核转储、
/boot中的内核映像及其/usr/lib/debug/boot中的相关调试信息文件放入一个空的目录中。此外,将
/lib/modules/$(uname -r)/kernel/中的内核模块和/usr/lib/debug/lib/modules/$(uname -r)/kernel/中的相关调试信息文件复制到名为modules的子目录中。在包含转储、内核映像、其调试信息文件和
modules子目录的目录中,启动crash实用程序>crashVMLINUX-VERSION vmcore
无论您在哪台计算机上分析转储,crash 实用程序都会生成类似以下的输出
>crash/boot/vmlinux-6.4.0-150600.9-default.gz \ /var/crash/2024-04-23-11\:17/vmcore crash 7.2.1 Copyright (C) 2002-2017 Red Hat, Inc. Copyright (C) 2004, 2005, 2006, 2010 IBM Corporation Copyright (C) 1999-2006 Hewlett-Packard Co Copyright (C) 2005, 2006, 2011, 2012 Fujitsu Limited Copyright (C) 2006, 2007 VA Linux Systems Japan K.K. Copyright (C) 2005, 2011 NEC Corporation Copyright (C) 1999, 2002, 2007 Silicon Graphics, Inc. Copyright (C) 1999, 2000, 2001, 2002 Mission Critical Linux, Inc. This program is free software, covered by the GNU General Public License, and you are welcome to change it and/or distribute copies of it under certain conditions. Enter "help copying" to see the conditions. This program has absolutely no warranty. Enter "help warranty" for details. GNU gdb (GDB) 7.6 Copyright (C) 2013 Free Software Foundation, Inc. License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html> This is free software: you are free to change and redistribute it. There is NO WARRANTY, to the extent permitted by law. Type "show copying" and "show warranty" for details. This GDB was configured as "x86_64-unknown-linux-gnu". KERNEL: /boot/vmlinux-6.4.0-150600.9-default.gz DEBUGINFO: /usr/lib/debug/boot/vmlinux-6.4.0-150600.9-default.debug DUMPFILE: /var/crash/2024-04-23-11:17/vmcore CPUS: 2 DATE: Thu Apr 23 13:17:01 2024 UPTIME: 00:10:41 LOAD AVERAGE: 0.01, 0.09, 0.09 TASKS: 42 NODENAME: eros RELEASE: 6.4.0-150600.9-default VERSION: #1 SMP 2024-03-31 14:50:44 +0200 MACHINE: x86_64 (2999 Mhz) MEMORY: 16 GB PANIC: "SysRq : Trigger a crashdump" PID: 9446 COMMAND: "bash" TASK: ffff88003a57c3c0 [THREAD_INFO: ffff880037168000] CPU: 1 STATE: TASK_RUNNING (SYSRQ)crash>
命令输出首先打印有用的数据:在内核崩溃时有 42 个任务正在运行。崩溃的原因是由 PID 为 9446 的任务调用的 SysRq 触发器。它是一个 Bash 进程,因为已使用的echo是 Bash shell 的内部命令。
crash 实用程序基于 GDB 构建,并提供了许多附加命令。如果您不带任何参数输入bt,则会打印崩溃时运行的任务的回溯
crash>btPID: 9446 TASK: ffff88003a57c3c0 CPU: 1 COMMAND: "bash" #0 [ffff880037169db0] crash_kexec at ffffffff80268fd6 #1 [ffff880037169e80] __handle_sysrq at ffffffff803d50ed #2 [ffff880037169ec0] write_sysrq_trigger at ffffffff802f6fc5 #3 [ffff880037169ed0] proc_reg_write at ffffffff802f068b #4 [ffff880037169f10] vfs_write at ffffffff802b1aba #5 [ffff880037169f40] sys_write at ffffffff802b1c1f #6 [ffff880037169f80] system_call_fastpath at ffffffff8020bfbb RIP: 00007fa958991f60 RSP: 00007fff61330390 RFLAGS: 00010246 RAX: 0000000000000001 RBX: ffffffff8020bfbb RCX: 0000000000000001 RDX: 0000000000000002 RSI: 00007fa959284000 RDI: 0000000000000001 RBP: 0000000000000002 R8: 00007fa9592516f0 R9: 00007fa958c209c0 R10: 00007fa958c209c0 R11: 0000000000000246 R12: 00007fa958c1f780 R13: 00007fa959284000 R14: 0000000000000002 R15: 00000000595569d0 ORIG_RAX: 0000000000000001 CS: 0033 SS: 002bcrash>
现在很清楚发生了什么:Bash shell 的内部echo命令向/proc/sysrq-trigger发送了一个字符。在相应的处理程序识别出该字符后,它调用了crash_kexec()函数。该函数调用了panic(),Kdump 保存了一个转储。
除了基本的 GDB 命令和bt的扩展版本之外,crash 实用程序还定义了与 Linux 内核结构相关的其他命令。这些命令理解 Linux 内核的内部数据结构,并以人类可读的格式呈现其内容。例如,您可以使用ps列出崩溃时正在运行的任务。使用sym,您可以列出所有内核符号及其对应的地址,或者查询单个符号的值。使用files,您可以显示进程的所有打开文件描述符。使用kmem,您可以显示有关内核内存使用的详细信息。使用vm,您可以检查进程的虚拟内存,甚至可以检查各个页面映射级别。有用命令的列表很长,其中许多命令接受各种选项。
我们提到的命令反映了常见 Linux 命令的功能,例如ps和lsof。要使用调试器找出事件的确切序列,您需要知道如何使用 GDB 并具有强大的调试技能。这两者都超出了本文档的范围。此外,您需要了解 Linux 内核。本文档末尾提供了几个有用的参考信息源。
Kdump 的配置存储在/etc/sysconfig/kdump中。您也可以使用 YaST 进行配置。Kdump 配置选项在的 › 下可用。以下 Kdump 选项可能对您有用。
您可以使用KDUMP_SAVEDIR选项更改内核转储的目录。请记住,内核转储的大小可能很大。如果可用磁盘空间(减去估计的转储大小)低于KDUMP_FREE_DISK_SIZE选项指定的值,Kdump 将拒绝保存转储。KDUMP_SAVEDIR理解 URL 格式PROTOCOL://SPECIFICATION,其中PROTOCOL是file、ftp、sftp、nfs或cifs之一,并且specification因每个协议而异。例如,要将内核转储保存到 FTP 服务器,请使用以下 URL 作为模板:ftp://username:password@ftp.example.com:123/var/crash。
内核转储很大,包含许多分析不必要的页面。使用KDUMP_DUMPLEVEL选项,您可以省略此类页面。该选项接受 0 到 31 之间的数值。如果指定0,则转储大小最大。如果指定31,则生成最小的转储。有关可能值的完整表格,请参阅kdump的手册页(man 7 kdump)。
有时减小内核转储的大小会很有用。例如,您可以这样做是为了通过网络传输转储或节省转储目录中的磁盘空间。这可以通过将KDUMP_DUMPFORMAT设置为compressed来实现。crash实用程序支持对压缩转储进行动态解压缩。
重要:Kdump 配置文件更改
更改/etc/sysconfig/kdump文件后,您需要运行systemctl restart kdump.service。否则,更改只会在下次系统重启时生效。
没有关于 Kexec 和 Kdump 用法的单一综合参考。但是,有一些有用的资源涉及某些方面
有关 Kexec 实用程序的用法,请参阅
kexec的手册页(man 8 kexec)。您可以在https://developer.ibm.com/technologies/linux/找到有关 Kexec 的一般信息。
有关特定于openSUSE Leap的 Kdump 的更多详细信息,请参阅https://ftp.suse.com/pub/people/tiwai/kdump-training/kdump-training.pdf。
Kdump 内部原理的深入描述可以在https://lse.sourceforge.net/kdump/documentation/ols2oo5-kdump-paper.pdf找到。
有关crash转储分析和调试工具的更多详细信息,请使用以下资源
除了GDB的信息页(
info gdb),在https://sourceware.org/gdb/documentation/还有可打印的指南。crash 实用程序具有全面的在线帮助。使用
helpCOMMAND显示command的在线帮助。如果您具备必要的 Perl 技能,可以使用 Alicia 来简化调试。这个基于 Perl 的 crash 实用程序前端可以在https://alicia.sourceforge.net/找到。
如果您更喜欢使用 Python,则应安装 Pykdump。此软件包可帮助您通过 Python 脚本控制 GDB。
Daniel P. Bovet 和 Marco Cesati 的 Understanding the Linux Kernel(ISBN 978-0-596-00565-8)提供了 Linux 内核内部的全面概述。
systemd-coredump收集并显示核心转储,用于分析应用程序崩溃。核心转储包含进程终止时内存的图像。默认情况下,当进程崩溃(或属于应用程序的所有进程)时,它会将核心转储存储在/var/lib/systemd/coredump文件中,并将核心转储记录到systemd日志中,如果可能,还包括回溯。您还可以使用gdb或crash等其他工具检查转储文件(请参阅第18.8节,“分析崩溃转储”)。
存储在/var/lib/systemd/coredump中的核心转储会在三天后删除(请参阅/usr/lib/tmpfiles.d/systemd.conf中的d /var/lib/systemd/coredump行)。
可以选择不存储核心转储,而只记录到日志中,这可能有助于最大限度地减少敏感信息的收集和存储。
systemd-coredump默认启用并准备运行。默认配置位于/etc/systemd/coredump.conf
[Coredump] #Storage=external #Compress=yes #ProcessSizeMax=2G #ExternalSizeMax=2G #JournalSizeMax=767M #MaxUse= #KeepFree=
大小单位为 B、K、M、G、T、P 和 E。ExternalSizeMax还支持infinity值。
以下示例演示了如何使用 Vim 进行简单测试,通过创建段错误来生成日志条目和核心转储。
步骤 19.1: 使用 Vim 创建核心转储 #
启用
debuginfo-pool和debuginfo-update存储库安装vim-debuginfo
启动
vim testfile并输入几个字符获取 PID 并生成段错误
>ps ax | grep vim 2345 pts/3 S+ 0:00 vim testfile#kill -s SIGSEGV 2345Vim 会发出错误消息
Vim: Caught deadly signal SEGV Vim: Finished. Segmentation fault (core dumped)
列出您的核心转储,然后检查它们
#coredumpctl TIME PID UID GID SIG PRESENT EXE Wed 2019-11-12 11:56:47 PST 2345 1000 100 11 * /bin/vim#coredumpctl info PID: 2345 (vim) UID: 0 (root) GID: 0 (root) Signal: 11 (SEGV) Timestamp: Wed 2019-11-12 11:58:05 PST Command Line: vim testfile Executable: /bin/vim Control Group: /user.slice/user-1000.slice/session-1.scope Unit: session-1.scope Slice: user-1000.slice Session: 1 Owner UID: 1000 (tux) Boot ID: b5c251b86ab34674a2222cef102c0c88 Machine ID: b43c44a64696799b985cafd95dc1b698 Hostname: linux-uoch Coredump: /var/lib/systemd/coredump/core.vim.0.b5c251b86ab34674a2222cef102 Message: Process 2345 (vim) of user 0 dumped core. Stack trace of thread 2345: #0 0x00007f21dd87e2a7 kill (libc.so.6) #1 0x000000000050cb35 may_core_dump (vim) #2 0x00007f21ddbfec70 __restore_rt (libpthread.so.0) #3 0x00007f21dd92ea33 __select (libc.so.6) #4 0x000000000050b4e3 RealWaitForChar (vim) #5 0x000000000050b86b mch_inchar (vim) [...]
当您有多个核心转储时,coredumpctl info会显示所有核心转储。通过PID、COMM(命令)或EXE(可执行文件的完整路径)过滤它们。例如,Vim 的所有核心转储
# coredumpctl info /bin/vim按PID查看单个核心转储
# coredumpctl info 2345将选定的核心输出到gdb
# coredumpctl gdb 2345在 PRESENT 列中的星号表示存在一个存储的核心转储。如果该字段为空,则没有存储的核心转储,coredumpctl 会从日志中检索崩溃信息。您可以通过 /etc/systemd/coredump.conf 文件中的 Storage 选项来控制此行为
Storage=none——核心转储被记录在日志中,但不存储。这对于最大程度地减少敏感信息的收集和存储很有用,例如为了遵守通用数据保护条例 (GDPR)。Storage=external——核心转储存储在/var/lib/systemd/coredump中Storage=journal——核心转储存储在systemd日志中
每个核心转储都会调用 systemd-coredump 的新实例,因此配置更改会应用于下一个核心转储,并且无需重新启动任何服务。
系统重启后,核心转储不会保留。您可以使用 coredumpctl 永久保存它们。以下示例按 PID 过滤并将核心转储存储在 vim.dump 中
# coredumpctl -o vim.dump dump 2345有关完整的命令和选项列表,请参阅 man systemd-coredump、man coredumpctl、man core 和 man coredump.conf。
- 20 精确时间协议
对于网络环境,保持计算机和其他设备的同步和精确时钟至关重要。有几种解决方案可以实现同步和精确度,例如,在“参考”手册第 18 章“使用 NTP 同步时间”中描述的广泛使用的网络时间协议 (NTP)。
对于网络环境,保持计算机和其他设备的同步和精确时钟至关重要。有几种解决方案可以实现同步和精确度,例如,在《参考》手册第 18 章“使用 NTP 同步时间”中描述的广泛使用的网络时间协议 (NTP)。
精确时间协议 (PTP) 是一种能够实现亚微秒级精度的协议,优于 NTP。PTP 支持分为内核空间和用户空间。openSUSE Leap 中的内核包含对 PTP 时钟的支持,这些时钟由网络驱动程序提供。
PTP 管理的时钟遵循主从层级结构。从时钟与其主时钟同步。该层级结构由在每个时钟上运行的最佳主时钟 (BMC) 算法更新。只有一个端口的时钟可以是主时钟或从时钟。这种时钟称为普通时钟 (OC)。具有多个端口的时钟可以在一个端口上是主时钟,在另一个端口上是从时钟。这种时钟称为边界时钟 (BC)。顶层主时钟称为大主时钟。大主时钟可以与全球定位系统 (GPS) 同步。这样,不同的网络可以高精度同步。
硬件支持是 PTP 的主要优势。它受到多种网络交换机和网络接口控制器 (NIC) 的支持。虽然可以在网络中使用非 PTP 硬件,但所有 PTP 时钟之间的网络组件启用 PTP 硬件可以实现最佳精度。
PTP 要求所使用的内核网络驱动程序支持软件或硬件时间戳。此外,NIC 必须支持物理硬件中的时间戳。您可以使用 ethtool 验证驱动程序和 NIC 的时间戳功能
>sudoethtool -T eth0 Time stamping parameters for eth0: Capabilities: hardware-transmit (SOF_TIMESTAMPING_TX_HARDWARE) software-transmit (SOF_TIMESTAMPING_TX_SOFTWARE) hardware-receive (SOF_TIMESTAMPING_RX_HARDWARE) software-receive (SOF_TIMESTAMPING_RX_SOFTWARE) software-system-clock (SOF_TIMESTAMPING_SOFTWARE) hardware-raw-clock (SOF_TIMESTAMPING_RAW_HARDWARE) PTP Hardware Clock: 0 Hardware Transmit Timestamp Modes: off (HWTSTAMP_TX_OFF) on (HWTSTAMP_TX_ON) Hardware Receive Filter Modes: none (HWTSTAMP_FILTER_NONE) all (HWTSTAMP_FILTER_ALL)
软件时间戳需要以下参数
SOF_TIMESTAMPING_SOFTWARE SOF_TIMESTAMPING_TX_SOFTWARE SOF_TIMESTAMPING_RX_SOFTWARE
硬件时间戳需要以下参数
SOF_TIMESTAMPING_RAW_HARDWARE SOF_TIMESTAMPING_TX_HARDWARE SOF_TIMESTAMPING_RX_HARDWARE
ptp4l 默认使用硬件时间戳。作为 root 用户,您需要使用 -i 选项指定支持硬件时间戳的网络接口。-m 告诉 ptp4l 将其输出打印到标准输出而不是系统的日志工具
>sudoptp4l -m -i eth0 selected eth0 as PTP clock port 1: INITIALIZING to LISTENING on INITIALIZE port 0: INITIALIZING to LISTENING on INITIALIZE port 1: new foreign master 00a152.fffe.0b334d-1 selected best master clock 00a152.fffe.0b334d port 1: LISTENING to UNCALIBRATED on RS_SLAVE master offset -25937 s0 freq +0 path delay 12340 master offset -27887 s0 freq +0 path delay 14232 master offset -38802 s0 freq +0 path delay 13847 master offset -36205 s1 freq +0 path delay 10623 master offset -6975 s2 freq -30575 path delay 10286 port 1: UNCALIBRATED to SLAVE on MASTER_CLOCK_SELECTED master offset -4284 s2 freq -30135 path delay 9892
master offset 值表示与主时钟测量的偏移量(以纳秒为单位)。
s0、s1 和 s2 指示器显示时钟伺服器的不同状态:s0 为未锁定,s1 为时钟步进,s2 为已锁定。如果伺服器处于锁定状态 (s2),则当配置文件中将 pi_offset_const 选项设置为负值时(有关更多信息,请参见 man 8 ptp4l),时钟不会步进(仅缓慢调整)。
freq 值表示时钟的频率调整(以十亿分之一,ppb 为单位)。
path delay 值表示从主时钟发送的同步消息的估计延迟(以纳秒为单位)。
端口 0 是用于本地 PTP 管理的 Unix 域套接字。端口 1 是 eth0 接口。
INITIALIZING、LISTENING、UNCALIBRATED 和 SLAVE 是端口状态的示例,这些状态在 INITIALIZE、RS_SLAVE 和 MASTER_CLOCK_SELECTED 事件上发生变化。当端口状态从 UNCALIBRATED 变为 SLAVE 时,计算机已成功与 PTP 主时钟同步。
您可以使用 -S 选项启用软件时间戳。
>sudoptp4l -m -S -i eth3
您也可以将 ptp4l 作为服务运行
>sudosystemctl start ptp4l
在这种情况下,ptp4l 从 /etc/sysconfig/ptp4l 文件读取其选项。默认情况下,此文件告诉 ptp4l 从 /etc/ptp4l.conf 读取配置选项。有关 ptp4l 选项和配置文件设置的更多信息,请参见 man 8 ptp4l。
要永久启用 ptp4l 服务,请运行以下命令
>sudosystemctl enable ptp4l
要禁用它,请运行
>sudosystemctl disable ptp4l
ptp4l 可以从可选的配置文件中读取其配置。由于默认不使用配置文件,您需要使用 -f 指定它。
>sudoptp4l -f /etc/ptp4l.conf
配置文件分为多个部分。全局部分(表示为 [global])设置程序选项、时钟选项和默认端口选项。其他部分是端口特定的,它们会覆盖默认端口选项。部分名称是配置端口的名称,例如 [eth0]。空端口部分可用于替换命令行选项。
[global] verbose 1 time_stamping software [eth0]
示例配置文件与以下命令的选项等效
>sudoptp4l -i eth0 -m -S
有关 ptp4l 配置选项的完整列表,请参阅 man 8 ptp4l。
ptp4l 以两种不同的方式测量时间延迟:点对点 (P2P) 或端到端 (E2E)。
- P2P
此方法通过
-P指定。它能更快地响应网络环境的变化,并且在测量延迟方面更准确。它仅用于每个端口与其他一个端口交换 PTP 消息的网络。P2P 需要通信路径上的所有硬件都支持。
- E2E
此方法通过
-E指定。这是默认设置。- 自动方法选择
此方法通过
-A指定。自动选项以 E2E 模式启动ptp4l,如果收到对等延迟请求,则更改为 P2P 模式。
重要提示:通用测量方法
单个 PTP 通信路径上的所有时钟必须使用相同的方法来测量时间延迟。如果在使用 E2E 机制的端口上收到对等延迟请求,或者在使用 P2P 机制的端口上收到 E2E 延迟请求,将打印警告。
您可以使用 pmc 客户端获取有关 ptp41 的更详细信息。它从标准输入(或从命令行)读取由名称和管理 ID 指定的操作。然后它通过选定的传输发送操作,并打印任何收到的回复。支持三种操作:GET 检索指定信息,SET 更新指定信息,以及 CMD(或 COMMAND)启动指定事件。
默认情况下,管理命令是针对所有端口的。TARGET 命令可用于为后续消息选择特定的时钟和端口。有关管理 ID 的完整列表,请运行 pmc help。
>sudopmc -u -b 0 'GET TIME_STATUS_NP' sending: GET TIME_STATUS_NP 90f2ca.fffe.20d7e9-0 seq 0 RESPONSE MANAGEMENT TIME_STATUS_NP master_offset 283 ingress_time 1361569379345936841 cumulativeScaledRateOffset +1.000000000 scaledLastGmPhaseChange 0 gmTimeBaseIndicator 0 lastGmPhaseChange 0x0000'0000000000000000.0000 gmPresent true gmIdentity 00b058.feef.0b448a
-b 选项指定发送消息中的边界跳数。将其设置为零会将边界限制为本地 ptp4l 实例。增加该值还可以从离本地实例更远的 PTP 节点检索消息。返回的信息可能包括
- stepsRemoved
到大主时钟的通信节点数。
- offsetFromMaster, master_offset
时钟与主时钟的最后测量偏移量(纳秒)。
- meanPathDelay
从主时钟发送的同步消息的估计延迟(纳秒)。
- gmPresent
如果为
true,则 PTP 时钟与主时钟同步;本地时钟不是大主时钟。- gmIdentity
这是大主时钟的身份。
有关 pmc 命令行选项的完整列表,请参见 man 8 pmc。
使用 phc2sys 将系统时钟与网卡上的 PTP 硬件时钟 (PHC) 同步。系统时钟被认为是从时钟,而网卡是主时钟。PHC 本身与 ptp4l 同步(请参阅第 20.2 节“使用 PTP”)。使用 -s 通过设备或网络接口指定主时钟。使用 -w 等待 ptp4l 进入同步状态。
>sudophc2sys -s eth0 -w
PTP 在国际原子时 (TAI) 中运行,而系统时钟使用协调世界时 (UTC)。如果您不指定 -w 来等待 ptp4l 同步,您可以使用 -O 指定 TAI 和 UTC 之间的秒数偏移量
>sudophc2sys -s eth0 -O -35
您也可以将 phc2sys 作为服务运行
>sudosystemctl start phc2sys
在这种情况下,phc2sys 从 /etc/sysconfig/phc2sys 文件读取其选项。有关 phc2sys 选项的更多信息,请参阅 man 8 phc2sys。
要永久启用 phc2sys 服务,请运行以下命令
>sudosystemctl enable phc2sys
要禁用它,请运行
>sudosystemctl disable phc2sys
当 PTP 时间同步正常工作并使用硬件时间戳时,ptp4l 和 phc2sys 会定期将带有时间偏移和频率调整的消息输出到系统日志。
ptp4l 输出示例
ptp4l[351.358]: selected /dev/ptp0 as PTP clock ptp4l[352.361]: port 1: INITIALIZING to LISTENING on INITIALIZE ptp4l[352.361]: port 0: INITIALIZING to LISTENING on INITIALIZE ptp4l[353.210]: port 1: new foreign master 00a069.eefe.0b442d-1 ptp4l[357.214]: selected best master clock 00a069.eefe.0b662d ptp4l[357.214]: port 1: LISTENING to UNCALIBRATED on RS_SLAVE ptp4l[359.224]: master offset 3304 s0 freq +0 path delay 9202 ptp4l[360.224]: master offset 3708 s1 freq -28492 path delay 9202 ptp4l[361.224]: master offset -3145 s2 freq -32637 path delay 9202 ptp4l[361.224]: port 1: UNCALIBRATED to SLAVE on MASTER_CLOCK_SELECTED ptp4l[362.223]: master offset -145 s2 freq -30580 path delay 9202 ptp4l[363.223]: master offset 1043 s2 freq -28436 path delay 8972 [...] ptp4l[371.235]: master offset 285 s2 freq -28511 path delay 9199 ptp4l[372.235]: master offset -78 s2 freq -28788 path delay 9204
phc2sys 输出示例
phc2sys[616.617]: Waiting for ptp4l... phc2sys[628.628]: phc offset 66341 s0 freq +0 delay 2729 phc2sys[629.628]: phc offset 64668 s1 freq -37690 delay 2726 [...] phc2sys[646.630]: phc offset -333 s2 freq -37426 delay 2747 phc2sys[646.630]: phc offset 194 s2 freq -36999 delay 2749
ptp4l 通常以高频率写入消息。您可以使用 summary_interval 指令降低频率。其值是 2^N 表达式的指数。例如,要将输出减少到每 1024 秒(等于 2^10),请将以下行添加到 /etc/ptp4l.conf 文件中
summary_interval 10
您还可以使用 -u SUMMARY-UPDATES 选项减少 phc2sys 命令更新的频率。
本节包含几个 ptp4l 配置示例。这些示例不是完整的配置文件,而是对特定文件进行更改的最小列表。ethX 字符串代表您设置中实际的网络接口名称。
示例 20.1: 使用软件时间戳的从时钟 #
/etc/sysconfig/ptp4l:
OPTIONS=”-f /etc/ptp4l.conf -i ethX”
未对分发文件 /etc/ptp4l.conf 进行任何更改。
示例 20.2: 使用硬件时间戳的从时钟 #
/etc/sysconfig/ptp4l:
OPTIONS=”-f /etc/ptp4l.conf -i ethX”
/etc/sysconfig/phc2sys:
OPTIONS=”-s ethX -w”
未对分发文件 /etc/ptp4l.conf 进行任何更改。
示例 20.3: 使用硬件时间戳的主时钟 #
/etc/sysconfig/ptp4l:
OPTIONS=”-f /etc/ptp4l.conf -i ethX”
/etc/sysconfig/phc2sys:
OPTIONS=”-s CLOCK_REALTIME -c ethX -w”
/etc/ptp4l.conf:
priority1 127
示例 20.4: 使用软件时间戳的主时钟(通常不推荐) #
/etc/sysconfig/ptp4l:
OPTIONS=”-f /etc/ptp4l.conf -i ethX”
/etc/ptp4l.conf:
priority1 127
NTP 和 PTP 时间同步工具可以共存,双向同步时间。
当使用 chronyd 同步本地系统时钟时,您可以配置 ptp4l 作为大主时钟,通过 PTP 分发本地系统时钟的时间。在 /etc/ptp4l.conf 中包含 priority1 选项
[global] priority1 127 [eth0]
然后运行 ptp4l
>sudoptp4l -f /etc/ptp4l.conf
当使用硬件时间戳时,您需要使用 phc2sys 将 PTP 硬件时钟与系统时钟同步
>sudophc2sys -c eth0 -s CLOCK_REALTIME -w
如果网络中有一个高精度 PTP 大主时钟,但没有支持 PTP 的交换机或路由器,则计算机可以作为 PTP 从站和 stratum-1 NTP 服务器运行。这样的计算机需要两个或更多网络接口,并且靠近大主时钟或直接连接到它。这可以确保网络中的高精度同步。
配置 ptp4l 和 phc2sys 程序以使用一个网络接口通过 PTP 同步系统时钟。然后配置 chronyd 以使用另一个接口提供系统时间
bindaddress 192.0.131.47 hwtimestamp eth1 local stratum 1
注意:NTP 和 DHCP
当 DHCP 客户端命令 dhclient 收到 NTP 服务器列表时,它默认会将它们添加到 NTP 配置中。要防止此行为,请设置
NETCONFIG_NTP_POLICY=""
在 /etc/sysconfig/network/config 文件中。
本附录包含 GNU 自由文档许可协议版本 1.2。
版权所有 (C) 2000、2001、2002 自由软件基金会,公司。地址:51 Franklin St, Fifth Floor, Boston, MA 02110-1301 USA。任何人均可复制和分发此许可文档的逐字副本,但禁止修改它。
本许可协议的目的是使一份手册、教科书或其他功能性和实用文档“自由”的含义为自由:确保每个人都能有效地复制和重新分发它,无论是否进行修改,无论是商业用途还是非商业用途。次要地,本许可协议为作者和出版商保留了一种获得对其作品认可的方式,同时不被认为对其作品的修改负责。
本许可协议是一种“复制保留”协议,这意味着该文档的衍生作品也必须以相同的方式自由。它补充了 GNU 通用公共许可协议,该协议是一种专为自由软件设计的复制保留许可协议。
我们设计本许可协议是为了将其用于自由软件的手册,因为自由软件需要自由文档:自由程序应该附带提供与软件相同的自由的手册。但本许可协议不限于软件手册;它可以用于任何文本作品,无论主题如何,无论是否作为印刷书籍出版。我们主要推荐本许可协议用于那些目的在于指导或参考的作品。
本许可协议适用于任何手册或其他作品,以任何媒介形式,其中包含版权所有者放置的通知,说明它可以根据本许可协议的条款进行分发。这样的通知授予全球性的、免版税的许可,期限无限,以根据本文档中规定的条件使用该作品。下文中的“文档”是指任何这样的手册或作品。公众的任何成员都是被许可人,并被称作“您”。如果您以需要根据版权法获得许可的方式复制、修改或分发该作品,则您接受该许可。
“文档的修改版本”是指包含文档或其一部分的任何作品,无论是逐字复制的,还是经过修改和/或翻译成另一种语言的。
“辅助章节”是文档的一个命名附录或前言章节,专门处理出版者或作者与文档的总体主题(或相关事项)的关系,并且不包含任何可能直接属于该总体主题的内容。(因此,如果文档部分是数学教科书,辅助章节可能不能解释任何数学知识。)这种关系可能是与主题或相关事项的历史联系,或与它们相关的法律、商业、哲学、伦理或政治立场。
“不变章节”是某些辅助章节,其标题被指定为不变章节,在说明文档根据本许可协议发布时发布的通知中。如果某个章节不符合上述辅助章节的定义,则不允许将其指定为不变章节。文档可以包含零个不变章节。如果文档未识别任何不变章节,则不存在不变章节。
“封面文字”是某些短文段,在说明文档根据本许可协议发布时发布的通知中列为前封面文字或后封面文字。前封面文字最多为 5 个单词,后封面文字最多为 25 个单词。
“透明”的文档副本是指机器可读的副本,以一种向公众提供规范的格式表示,该格式适合使用通用文本编辑器或(对于由像素组成的图像)通用绘画程序或(对于绘图)一些广泛可用的绘图编辑器进行直接修改文档,并且适合输入文本格式化程序或自动翻译成各种适合输入文本格式化程序的格式。以其他透明文件格式制作的副本,其标记或缺少标记被安排以阻碍或阻止读者进行后续修改,不是透明的。如果用于大量文本,则图像格式不是透明的。不是“透明”的副本称为“不透明”。
适合透明副本的格式示例包括纯 ASCII 无标记、Texinfo 输入格式、LaTeX 输入格式、使用公开可用的 DTD 的 SGML 或 XML,以及符合标准的简单 HTML、PostScript 或 PDF,这些格式专为人工修改而设计。透明图像格式的示例包括 PNG、XCF 和 JPG。不透明格式包括只能由专有文字处理器读取和编辑的专有格式,DTD 和/或处理工具不易获得的 SGML 或 XML,以及一些文字处理器为输出目的而生成的机器生成的 HTML、PostScript 或 PDF。
“标题页”是指印刷书籍的标题页本身,以及所有需要以易读方式容纳本许可协议要求出现在标题页上的材料的后续页面。对于没有标题页的格式的作品,“标题页”是指作品标题最突出显示位置附近的文本。
一个章节“题为 XYZ”是指文档的一个命名子单元,其标题完全是 XYZ,或者在另一种语言中翻译 XYZ 后跟有 XYZ 的文本。 (此处 XYZ 代表下面提到的特定章节名称,例如“致谢”、“献词”、“认可”或“历史”。)要修改文档时“保留标题”,意味着它仍然是一个根据此定义“题为 XYZ”的章节。
文档可以包含与声明本许可协议适用于文档的通知相邻的免责声明。这些免责声明被视为在本许可协议中通过引用包含,但仅限于免除担保:这些免责声明可能具有的任何其他含义无效,并且对本许可协议的含义没有影响。
您可以以任何媒介形式复制和分发文档,无论是商业用途还是非商业用途,前提是本许可协议、版权声明和许可声明说明本许可协议适用于该文档,都必须在所有副本中重现,并且您不能向这些许可协议添加任何其他条件。您不得使用技术措施来阻止或控制您制作或分发的副本的阅读或进一步复制。但是,您可以接受为副本提供的补偿。如果您分发足够数量的副本,还必须遵守第 3 节的规定。
您也可以在相同条件下的基础上借出副本,并且您可以公开展示副本。
如果您发布印刷副本(或通常带有印刷封面的媒体中的副本)的文档,数量超过 100 个,并且文档的许可声明需要封面文字,则必须将副本包含在封面中,封面清晰且易于阅读地承载所有这些封面文字:前封面文字在正面封面上,后封面文字在背面封面上。两个封面还必须清晰且易于阅读地将您识别为这些副本的出版商。正面封面上必须以同样突出和可见的方式呈现完整的标题。您可以在封面中添加其他材料。只要它们保留文档的标题并满足这些条件,就可以将限制在封面上的更改视为其他方面的逐字复制。
如果所需的封面文字太多而无法清晰地适应,您应该将首先列出的文字(尽可能多地适应)放在实际的封面上,并将剩余的文字继续放在相邻的页面上。
如果您发布或分发超过 100 个不透明的文档副本,则必须在每个不透明副本中包含一个机器可读的透明副本,或者在每个不透明副本中说明一个计算机网络位置,公众可以使用公共标准网络协议从该位置下载文档的完整透明副本,无需添加任何材料。如果您使用后一种选项,则必须采取合理的预防措施,在开始分发大量不透明副本时,以确保该透明副本将继续可从所述位置访问,直到您最后一次分发该版本的副本(直接或通过您的代理或零售商)给公众至少一年之后。
建议,但不是必需的,您在重新分发大量副本之前联系文档的作者,以便给他们一个机会向您提供文档的更新版本。
您可以根据上述第 2 节和第 3 节的条件复制和分发文档的修改版本,前提是您根据本许可协议发布修改版本,修改版本充当文档的角色,从而许可向拥有其副本的任何人分发和修改修改版本。此外,您必须在修改版本中执行以下操作
在标题页(如果有封面,则在封面上)使用与文档不同的标题,以及与以前的版本(如果存在,应在文档的历史记录部分中列出)不同的标题。如果您获得原始版本发布者的许可,则可以使用以前版本的相同标题。
在标题页上,列出负责修改版本创作的一个或多个个人或实体,以及文档的所有主要作者(如果文档少于五个主要作者),除非他们免除您此要求。
在标题页上说明修改版本的出版商名称,作为出版商。
保留文档的所有版权声明。
在您的修改旁边添加适当的版权声明。
在版权声明之后包含一个许可声明,授予公众根据本许可协议使用修改版本的权限,形式如下所示的附录。
在许可声明中保留文档许可声明中给出的所有不变章节和所需的封面文字的完整列表。
包含本许可协议的未更改副本。
保留标题为“历史记录”的部分,保留其标题,并添加一个项目,说明修改版本的标题、年份、新作者和出版商,如标题页上所述。如果文档中没有标题为“历史记录”的部分,则创建一个说明文档的标题、年份、作者和出版商,如其标题页上所述,然后添加一个描述修改版本,如上一句所述的项目。
保留文档中提供的用于公开访问文档的透明副本的网络位置(如果有),以及文档中基于其文档的网络位置。这些可以放在“历史记录”部分。您可以省略对发布时间早于文档本身至少四年的作品的网络位置,或者如果原始版本发布者允许,则可以省略。
对于标题为“致谢”或“献词”的任何章节,保留章节标题,并在章节中保留所有贡献者的致谢和/或献词的实质和语气。
保留文档的所有不变章节,文本和标题均未更改。章节编号或等效内容不被视为章节标题的一部分。
删除标题为“认可”的任何章节。这样的章节不能包含在修改版本中。
不要将任何现有章节重新命名为“认可”或与任何不变章节的标题冲突。
保留任何免责声明。
如果修改版本包含新的前言章节或附录,这些章节符合辅助章节的资格并且不包含从文档中复制的任何材料,您可以选择将其中一些或全部章节指定为不变章节。为此,请将它们的标题添加到修改版本许可声明中的不变章节列表中。这些标题必须与任何其他章节标题不同。
您可以添加一个标题为“认可”的章节,前提是它仅包含对您的修改版本由各种方提供的认可——例如,同行评审声明或该文本已被组织批准为标准的权威定义。
您可以添加最多五个单词的前封面文字,以及最多 25 个单词的后封面文字,添加到修改版本中封面文字列表的末尾。任何一个实体(或其代表)只能添加一个前封面文字和一个后封面文字。如果文档已经包含由您或您代表的同一实体添加的相同封面的封面文字,则您不能添加另一个;但是,您可以获得先前添加旧版本的先前出版商的明确许可来替换旧版本。
文档的作者和出版商通过本许可协议不授予使用其姓名进行宣传或断言或暗示认可任何修改版本的许可。
您可以将本文档与其他根据本许可证发布的文档结合起来,遵循上述第 4 条中关于修改版本的规定,前提是您在组合中包含所有原始文档的所有不变章节,未经修改,并将它们全部列为组合作品的许可通知中的不变章节,并且保留所有它们的保修声明。
组合作品只需包含一份本许可证的副本,并且多个相同的不可变章节可以用一份副本代替。如果有多个名称相同但内容不同的不可变章节,请通过在章节标题末尾添加括号内的原始作者或发布者名称(如果已知),或者添加一个唯一的编号,使每个章节的标题唯一。在组合作品的许可通知中的不可变章节列表中对章节标题进行相同的调整。
在组合中,您必须将各个原始文档中标题为“历史”的部分组合成一个标题为“历史”的部分;同样地,组合任何标题为“致谢”的部分,以及任何标题为“献词”的部分。您必须删除所有标题为“推荐”的部分。
您可以创建一个包含本文档和其他根据本许可证发布的文档的集合,并将各个文档中的本许可证的副本替换为包含在集合中的单个副本,前提是您遵循本许可证关于对每个文档进行逐字复制的规则。
您可以从这样的集合中提取单个文档,并以本许可证的形式单独分发它,前提是您将本许可证的副本插入到提取的文档中,并遵循本许可证关于该文档逐字复制的所有其他规定。
将本文档或其衍生作品与其他独立作品在存储或分发介质的卷中组合,如果由此产生的版权不用于限制组合作品用户超出各个作品允许的法律权利,则称为“聚合”。当本文档包含在聚合中时,本许可证不适用于聚合中本身不是本文档衍生作品的其他作品。
如果第 3 条的封面文字要求适用于这些文档的副本,那么如果文档小于整个聚合的一半,则文档的封面文字可以放置在包围文档的封面上,或者如果文档是电子形式,则放置在电子封面上。否则,它们必须出现在包围整个聚合的印刷封面上。
翻译被认为是一种修改,因此您可以根据第 4 条的规定以本许可证的形式分发文档的翻译。用翻译替换不变章节需要其版权所有者的特别许可,但您可以包含不变章节的一些或全部翻译,以及这些不变章节的原始版本。您可以包含本许可证的翻译,以及文档中的所有许可通知和任何保修声明,前提是您也包含本许可证的原始英文版本以及这些通知和声明的原始版本。如果翻译与本许可证或通知或声明的原始版本之间存在分歧,则原始版本将优先。
如果文档中的某个部分标题为“致谢”、“献词”或“历史”,则第 4 条要求保留其标题(第 1 条)通常需要更改实际标题。
您不得复制、修改、再许可或分发本文档,除非本许可证明确规定。任何其他尝试复制、修改、再许可或分发本文档都是无效的,并将自动终止您在本许可证下的权利。但是,从您这里根据本许可证收到副本或权利的各方,只要这些方始终完全遵守本许可证,其许可证将不会被终止。
自由软件基金会可能会不时发布 GNU 自由文档许可证的新修订版本。这些新版本将与当前版本精神相似,但可能在细节上有所不同,以解决新的问题或疑虑。请参阅 https://gnu.ac.cn/copyleft/。
许可证的每个版本都赋予一个不同的版本号。如果文档指定本许可证的特定编号版本“或任何后续版本”适用于它,您可以选择遵循该指定版本的条款和条件,或自由软件基金会发布的任何后续版本(不作为草案发布)。如果文档未指定本许可证的版本号,您可以选择自由软件基金会发布的任何版本(不作为草案发布)。
Copyright (c) YEAR YOUR NAME. Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation License, Version 1.2 or any later version published by the Free Software Foundation; with no Invariant Sections, no Front-Cover Texts, and no Back-Cover Texts. A copy of the license is included in the section entitled “GNU Free Documentation License”.
如果您有不变章节、封面文字和封底文字,请将“with...Texts.”行替换为以下内容
with the Invariant Sections being LIST THEIR TITLES, with the Front-Cover Texts being LIST, and with the Back-Cover Texts being LIST.
如果您有不变章节而没有封面文字,或者这三者中的其他组合,请将这两种替代方案合并以适应情况。
如果您的文档包含程序代码的非平凡示例,我们建议您以您选择的自由软件许可证(例如 GNU 通用公共许可证)并行发布这些示例,以允许它们在自由软件中使用。